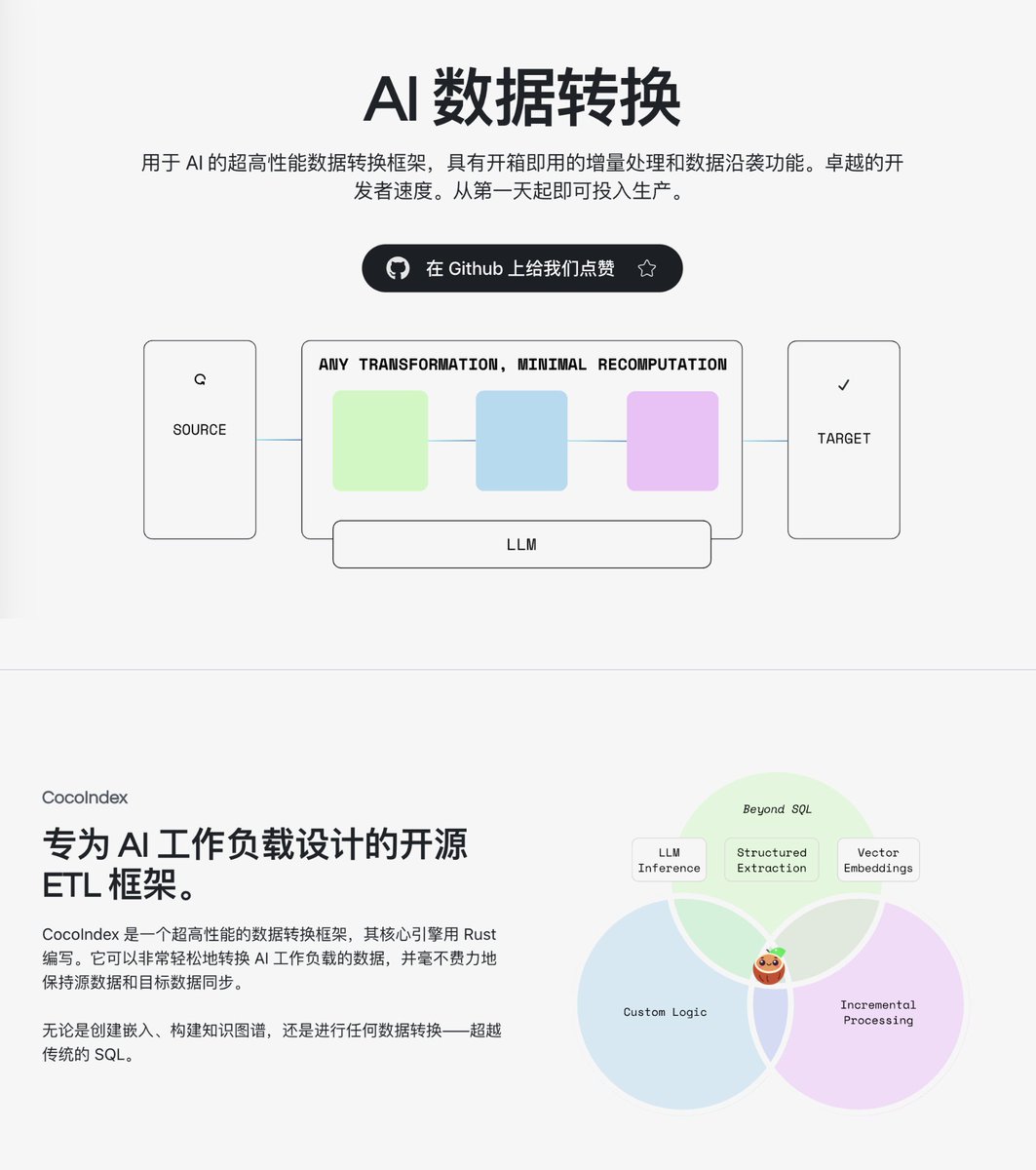
RAG アプリケーションを開発したり、ナレッジ ベースを構築したりする場合、最も面倒な部分はモデルの選択ではなく、データ処理パイプラインであることがよくあります。 データのクリーンアップ、スライス、ベクトル化を行うには、多数の Python スクリプトを作成する必要があり、ソース データが変更された場合、プロセス全体を再実行するには時間がかかり、コストもかかります。 私は最近、GitHub で CocoIndex オープンソース プロジェクトを見つけました。これは、AI シナリオ向けに特別に設計された高性能なデータ変換フレームワークです。 わずか 100 行程度の Python コードで、ファイルの読み取りとチャンク化からライブラリへのベクトルの挿入までのプロセス全体を定義できます。 GitHub: https://t.co/RwUjyHJEym ローカル ファイル、Amazon S3、Google Drive、Postgres、Qdrant、LanceDB などのベクター データベースなど、さまざまなデータ ソースとターゲットをサポートしています。 さらに、テキストのセグメンテーション、埋め込みの生成、PDF 解析、ナレッジ グラフの構築など、一般的に使用される変換コンポーネントも含まれています。 セマンティック検索、ナレッジグラフ、商品推奨、画像検索など、20 を超える実用的なアプリケーション シナリオを網羅した豊富な例が提供されており、直接参照して使用できます。