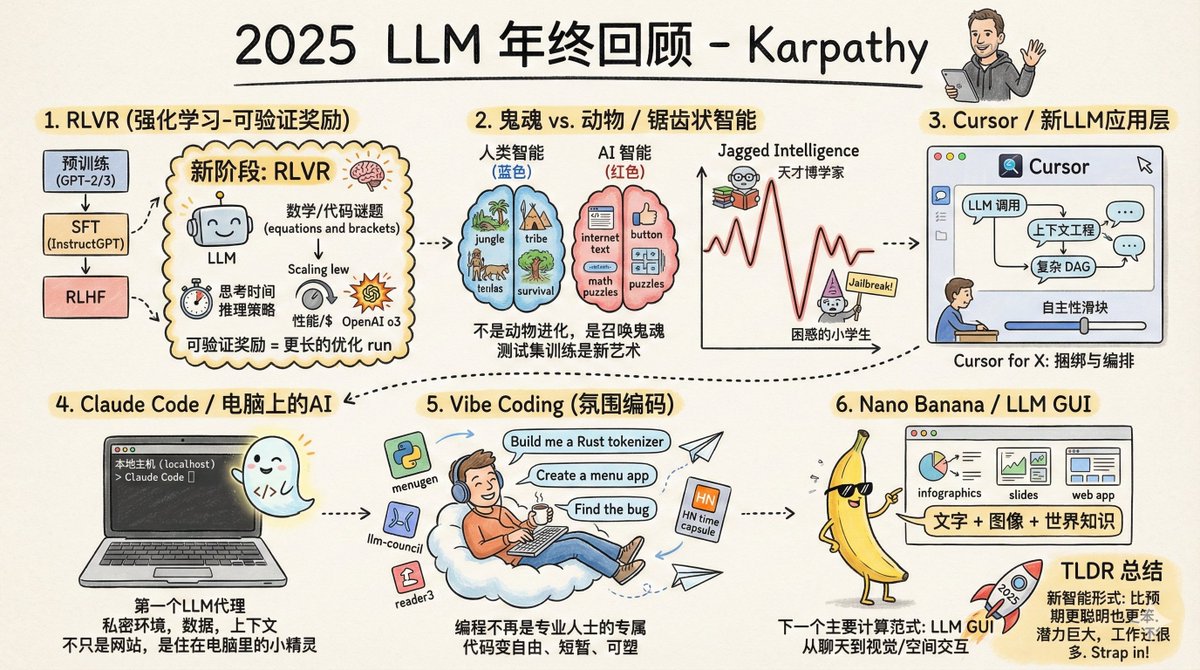
OpenAI の共同創設者であり、テスラの元 AI ディレクター、そして世界で最も影響力のある AI 研究者の一人である Andrej Karpathy 氏が、2025 年 LLM 年末レビューを発表しました。 最初の大きな変化は、トレーニング方法のパラダイムシフトです。 2025年以前は、実用的な大規模モデルの学習は、基本的に事前学習、教師ありファインチューニング、そして人間によるフィードバックによる強化学習という3つのステップで構成されていました。この方式は2020年から使用されており、安定して信頼性を維持しています。 2025 年には、重要な第 4 ステップである RLVR (検証可能な報酬からの強化学習) が追加されました。 これは何を意味するのでしょうか?簡単に言えば、「標準的な解答」がある環境でモデルを繰り返し練習させることを意味します。例えば、数学の問題では、答えは正解か不正解かのどちらかであり、人間による採点は必要ありません。コードにも同じことが当てはまります。動作するなら動作するのです。 これと従来のトレーニングとの根本的な違いは何でしょうか?これまでの教師あり微調整と人間によるフィードバックは、基本的に「モデルをコピーする」ものであり、モデルは人間が提供するサンプルを何でも学習していました。しかし、RLVRは違います。モデルが独自の問題解決戦略を発見できるようにします。これは水泳を学ぶようなものです。以前は指導ビデオを見て動きを真似していましたが、今はただ水に放り込まれるだけです。向こう岸まで泳げさえすれば、どのように漕ぐかは問題ではありません。 その結果は?モデルは自力で推論らしい何かを「理解」した。大きな問題を小さなステップに分解し、道に迷った時には引き返してやり直すことを学習した。こうした戦略は人間には実証できない。なぜなら、人間でさえ「正しい思考プロセス」がどのようなものかを明確に説明できないからだ。 この変化は連鎖反応を引き起こし、コンピューティングパワーの割り当て方法を変えました。以前はコンピューティングパワーの大部分が事前学習段階に費やされていましたが、今では強化学習段階でますます多くのコンピューティングパワーが使用されるようになりました。モデルのパラメータサイズはそれほど大きく増加していませんが、推論能力は飛躍的に向上しました。OpenAIのo1はこの道の出発点であり、o3は人々に真に「違いを実感」させる変曲点となりました。 もう一つ新しいアプローチがあります。それは、推論中により多くの計算能力を消費することです。モデルに「より長く考える」ようにすることで、より長い推論チェーンが生成され、結果としてパフォーマンスが向上します。これは本質的に、モデルの能力を制御するための調整ノブを追加するようなものです。 2 番目の大きな変化: AI の知性がどのような「形」になっているのかがようやく理解できました。 カルパシー氏は、私たちは「動物を育てている」のではなく、「幽霊を召喚している」のだという素晴らしい例え話をした。 人間の知能は進化し、その最適化目標は「ジャングルで部族が生き残るのを助けること」です。大規模モデルの知能は訓練され、その最適化目標は「人間の文章を模倣し、数学の問題で得点を獲得し、ベンチマークリストでスコアを獲得すること」です。 最適化の目標がまったく異なるため、当然、結果もまったく異なります。 したがって、AIの知能は「ギザギザの知能」です。ある分野では全知の学者のように振る舞う一方で、別の分野では小学生でも犯さないような間違いを犯します。ある瞬間は複雑な数式を導き出すのを手伝ってくれたかと思えば、次の瞬間には、簡単な脱獄のヒントに騙されてデータを提供してしまうのです。 なぜでしょうか?それは、「検証可能な報酬」がある分野では、モデルがその分野で「急上昇」するからです。数学には標準的な解答があり、コードはテストできるため、これらの分野では進歩が速いです。しかし、常識、社会的交流、創造性といった分野では、「正しい」ことを定義するのが難しく、モデルが効率的に学習することが難しくなります。 これもまた、カルパシーがベンチマークへの信頼を失う原因となった。理由は単純だ。テスト問題自体が「検証可能な環境」であり、モデルはこれらの環境に合わせて最適化できるからだ。ベンチマークを制覇することはもはや芸術と言えるほどになった。全てのベンチマークで最高得点を獲得しても、真の汎用知能には程遠いことはあり得るのだ。 3 番目の大きな変更: LLM アプリケーション層の登場。 今年、Cursor は驚くほど人気が高まりましたが、Karpathy 氏は、その最大の重要性は製品自体ではなく、「LLM アプリケーション」という新しい種の存在を証明したことにあると考えています。 「Xドメインにおけるカーソル」に関する議論の出現は、新たなソフトウェアパラダイムの形成を示唆しています。これらのアプリケーションはどのような機能を果たすのでしょうか? まず、コンテキストエンジニアリングを実行します。関連情報を整理し、モデルに入力します。 次に、複数のモデル呼び出しをオーケストレーションします。バックエンドは多数のAPI呼び出しを処理する可能性があるため、パフォーマンスとコストのバランスをとる必要があります。 3 番目に、特殊なシナリオ用のインターフェースを提供し、重要なポイントで人間が介入できるようにします。 4番目に、ユーザーに「自律性の度合いスライダー」を提供します。これにより、より多くのことを実行させたり、より少ないことを実行させたりできます。 1年間ずっと議論されてきた疑問があります。それは、「このアプリケーション層はどれくらい「厚い」のか?」モデルベンダーがすべてのアプリケーションを食い尽くしてしまうのではないか、というものです。 カルパシー氏の評価によれば、モデルメーカーは「一般的なスキルを持つ大学卒業生」を育成するが、LLMアプリケーションはこれらの卒業生を組織化し、訓練し、就職させ、特定の業界で活躍できるプロフェッショナルチームへと育成する役割を担っている。データ、センサー、アクチュエーター、フィードバックループなど、これらはすべてアプリケーション層のタスクである。 4 番目の大きな変化: AI がコンピューターに導入されました。 Claude Codeは、今年Karpathy氏に最も感銘を与えた製品の一つです。ツールの呼び出し、推論の実行、ループの実行、そして複雑な問題の解決といった機能を備えた「AIエージェント」のあるべき姿を体現しています。 しかし、さらに重要なのは、それがあなたのコンピュータ上で実行されるということです。あなたの環境、データ、そしてコンテキストを活用します。 カルパシー氏は、OpenAIが状況を誤って判断したと考えている。彼らはCodexとエージェントをクラウドコンテナに集中させ、ChatGPTからスケジュールを設定している。これは彼らが「AGIの最終段階」を目指しているように見えるが、まだそこには至っていない。 現実には、AIの能力は多岐にわたり、人間による監視と支援が依然として必要です。現状では、インテリジェントエージェントをローカルに配置し、開発者と連携させる方がより賢明なアプローチです。 Claude Codeは、ミニマルなコマンドラインインターフェースでこれを実現しました。AIはもはや単なるウェブサイトではなく、コンピュータの中に「生きる」小さなスプライトです。これは、人間とコンピュータのインタラクションにおける全く新しいパラダイムです。 5 番目の大きな変化: Vibe Coding が始まりました。 2025年、AIの能力は限界を超えました。英語だけでニーズを記述するだけで、コードの見た目を気にすることなく、AIがプログラムを書いてくれます。カルパシー氏はこのプログラミングスタイルについて「バイブコーディング」と呼び、さりげなくツイートしたところ、この言葉は瞬く間に広まりました。 これは何を意味するのでしょうか?プログラミングはもはやプロのプログラマーだけのものではなく、一般の人でもできるようになります。これは、これまでの技術普及モデルとは大きく異なります。かつては、新しい技術は常に大企業、政府、そして専門家によって習得され、その後徐々に他の分野へと広がっていきました。しかし、このモデルは逆転し、一般の人々が専門家よりもはるかに多くの恩恵を受けているのです。 これは単に「非プログラマーがプログラミングできるようにする」ということではありません。プログラミングができる人にとって、以前は「書く価値がない」と思われていた多くの小さなプログラムが、今では書く価値があるものになっています。Karpathy氏自身もVibe Codingで多くのプロジェクトに携わってきました。Rustでカスタムトークナイザーを開発し、複数のユーティリティアプリを開発し、バグを見つけるためだけに単発のプログラムも作成しました。 コードは突如として安価になり、使い捨てとなり、まるで紙切れに書くように気軽に書けるようになる。これはソフトウェアの形態とプログラマーの仕事を完全に変えるだろう。 6 番目の大きな変化: 大規模モデルの「グラフィカル インターフェース時代」が到来します。 GoogleのGemini Nano Bananaは、今年最も過小評価されている製品の一つです。会話の内容に基づいて、画像、インフォグラフィック、アニメーションをリアルタイムで生成し、返信を「書く」のではなく「描く」ことができます。 カルパシーはこれをより大きな歴史的文脈の中に位置づけています。大規模モデルは、1970年代や80年代のコンピュータのように、次世代の主要なコンピューティングパラダイムを象徴するものであり、したがって、私たちも同様の進化の道を辿ることになるのです。 今では、大型モデルとの「チャット」は、1980年代に端末でコマンドを入力するのと少し似ています。テキストは機械が好むフォーマットですが、人間はそうではありません。人間はテキストを読むのがあまり好きではありません。遅くて疲れるからです。人々は画像、動画、空間レイアウトを見ることを好みます。だからこそ、従来のコンピュータはグラフィカルインターフェースを発明したのです。 大規模モデルには独自の「GUI」が必要です。画像、スライド、ホワイトボード、アニメーション、ミニアプリなど、私たちが好む方法で語りかけてくる必要があります。現在の絵文字やMarkdownは、テキストを「装飾」するだけの初歩的な形式に過ぎません。真のLLM GUIはどのようなものになるのでしょうか?Nano Bananaは、その初期のヒントです。 最も興味深いのは、これが単なる画像生成ではないということです。テキスト生成、画像生成、そして世界に関する知識を絡み合わせ、それらをすべてモデルの重みに統合する必要があります。 カルパシー氏の結論はこうだ。2025年のグランドモデルは、彼の予想よりも賢くもあり、同時に愚かでもある。その両方が同時に真実なのだ。 しかし、一つ確かなことがあります。それは、私たちの現在の能力をもってしても、潜在能力の10%にも達していないということです。試すべきアイデアはまだまだたくさんあり、この分野全体が未開拓だと感じています。 彼はドワルケシュのポッドキャストで一見矛盾したことを言った。 彼は進歩が急速に進むと信じている。 > 同時に、まだやるべきことはたくさんあると思います。 この二つは矛盾するものではありません。シートベルトを締めて、2026年も加速を続けましょう。