DSAは実のところ、かなり突飛なアイデアです。人々がそれを高く評価するのは(そもそも評価されるとしても)効率性の向上だけですが、層ごとの線形/SWA+完全ソフトマックスハイブリッドを最適化するという業界のパターンから大きく逸脱しています。このようなものを製品版に導入できるのは、非常に自信のある研究室だけです。
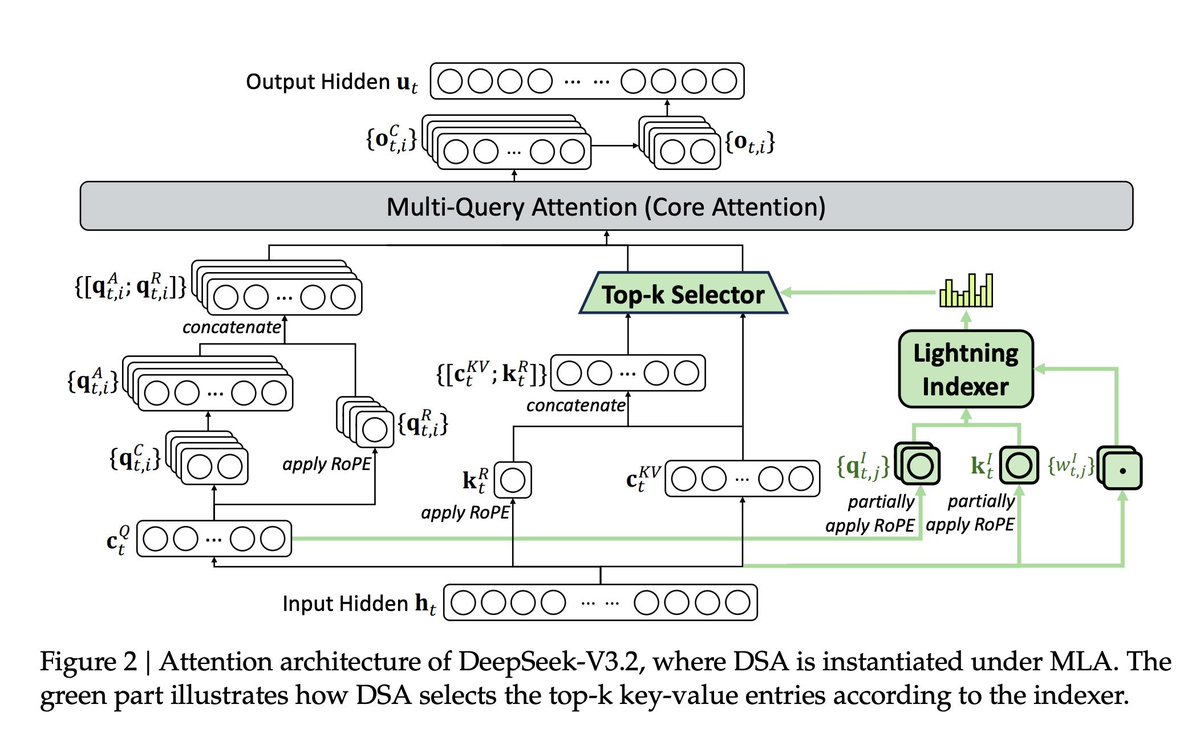
彼らが、学習後のスパース性が行き止まりであると主張した NSA の後でこれを行ったということは、彼らが埋没コストを無視できる能力があることを物語っています。 NSAはどうなったのか、ちょっと気になります。ブロック単位のアテンションが最適ではないのは明らかですが、DSAもその場しのぎの対応に過ぎません。
