Bolmoのモデルは巧妙なアプローチを採用しています。ゼロから学習するのではなく、既存のモデルを「バイトエンコード」するのです。内蔵のローカルエンコーダ/デコーダがバイトシーケンスを「潜在的なトークン」に圧縮し、従来のTransformerに入力して処理します。これにより、最小限のオーバーヘッドで変換が可能になります。

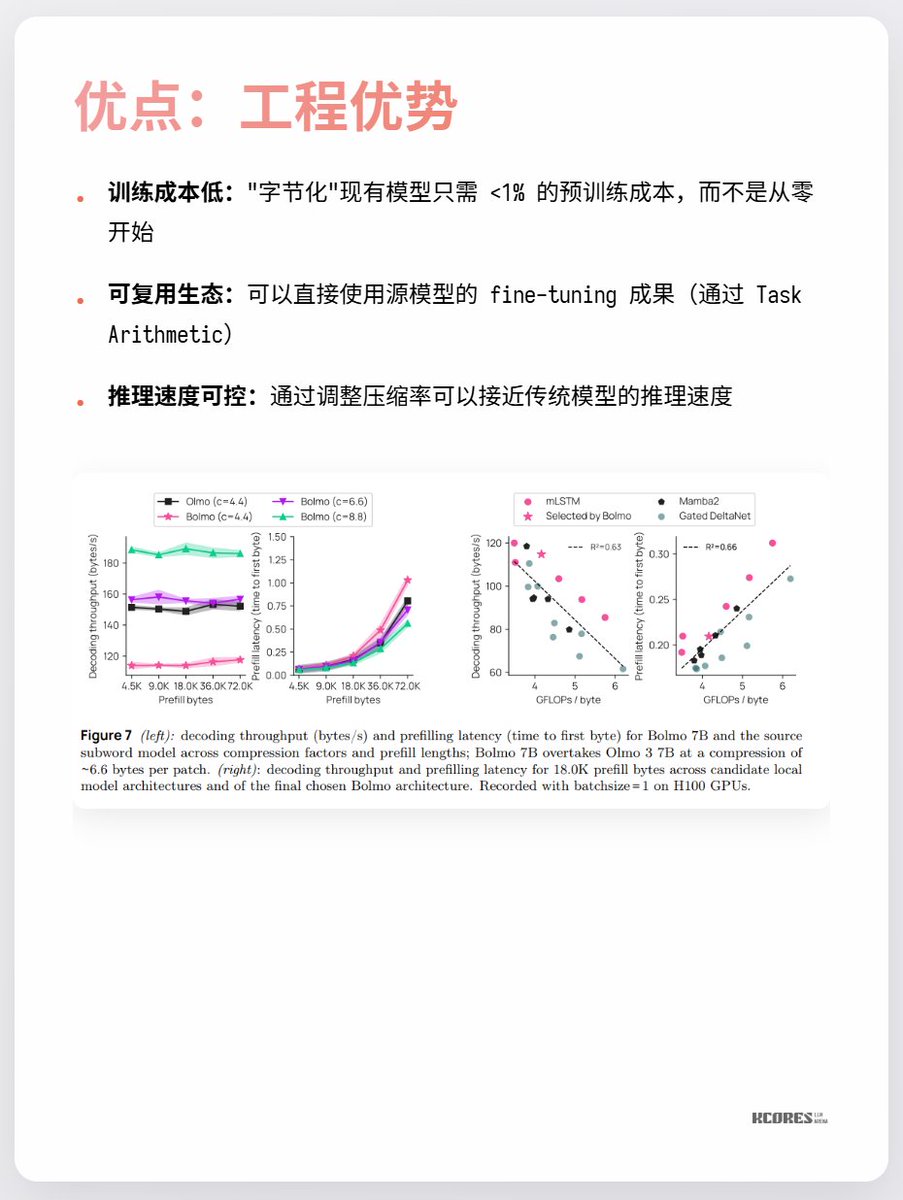

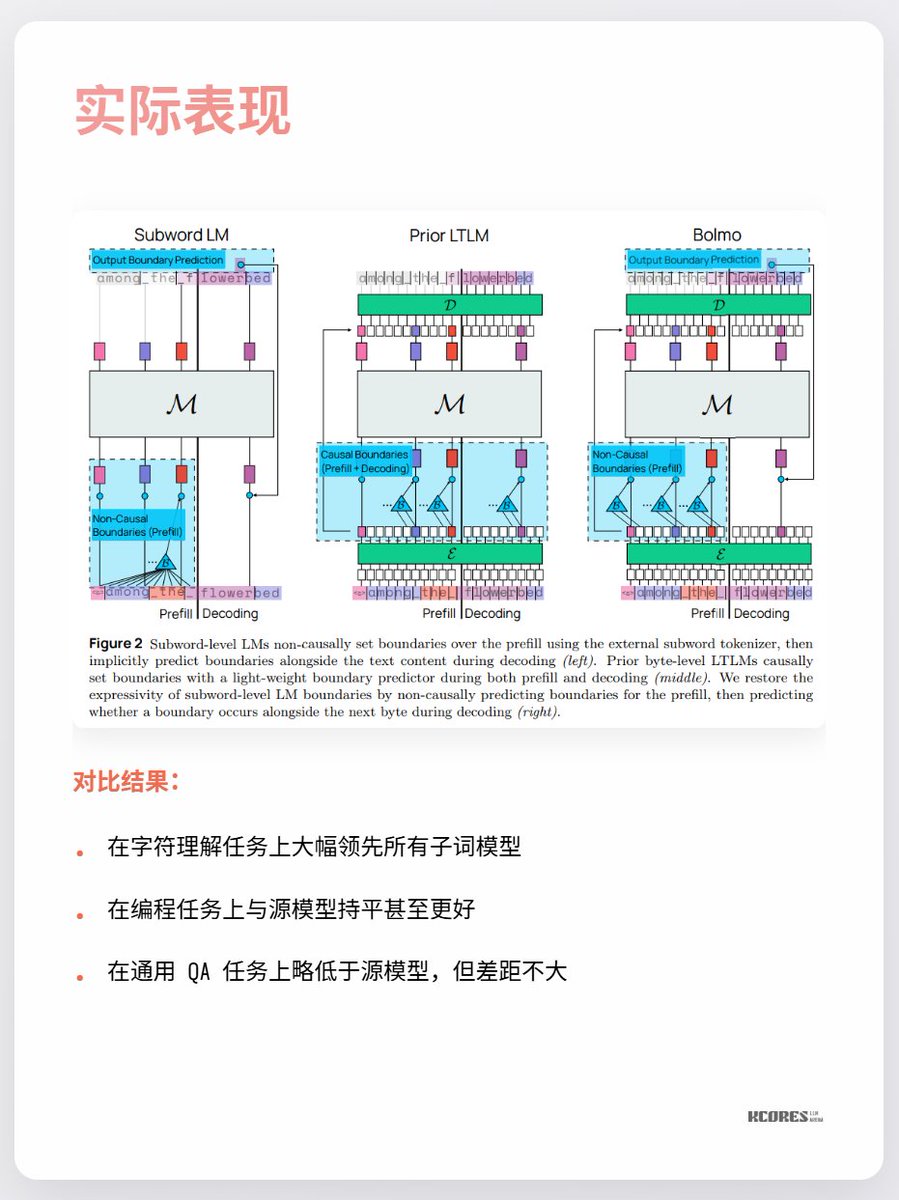
現時点での最大の論点は、目に見えるほどのメリットが見られない点と、シーケンスが長くなるとキーバリューキャッシュの容量が大きくなり、GPUメモリへの負荷が高まる点です。また、顕著なリードは文字認識という単一のタスクでのみ見られ、他のタスクでは目立った改善はほとんど見られません。 要するに、注目する価値があるということです。技術革新の時代におけるスパイラルな探求は常に非常に興味深いものです。例えば、個人的には水銀整流器(最後の写真)が好きでしたが、今ではIGBTに置き換えられています。

