大規模モデルにはトークナイザーが搭載されていることは周知の事実です。トークナイザーはモデルが使用する単語分割テーブルを記録し、意味を理解して計算を実行するための最小単位となります。しかし、そもそもなぜ単語分割が必要なのか疑問に思ったことはありませんか?UTF-8エンコードを使ってトークンを直接入力した方がよいのではないでしょうか? 本日の新しいモデル、Bolmo-8Bを見てみましょう。このモデルは従来のアプローチを完全に放棄し、UTF-8バイトを基本単位として採用し、各文字をバイト列として処理します。
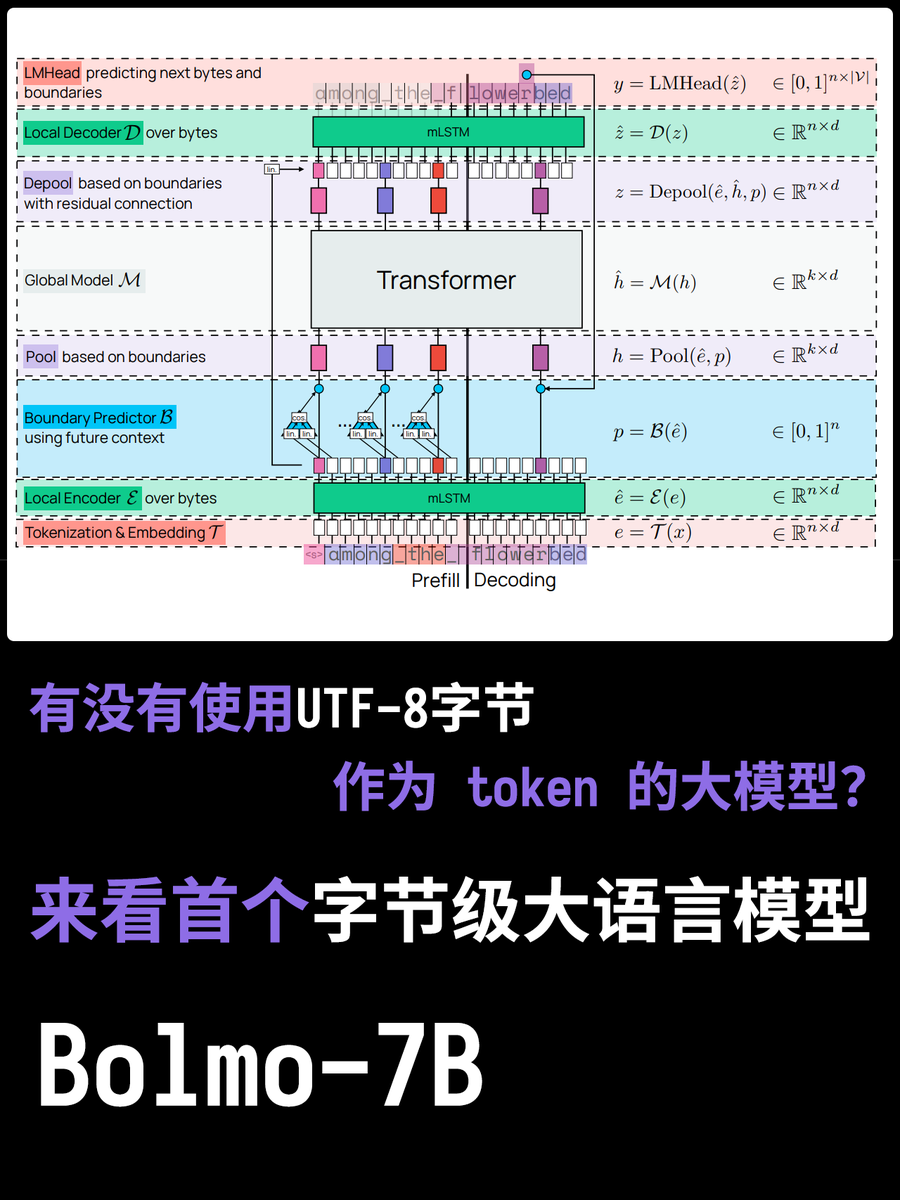
これを実行する最大の利点は、「Strawberryには『r』がいくつあるか?」といった質問に簡単に答えられることです。これは、各文字が個別にUTF-8でエンコードされているためです。 しかし、それがもたらす問題も非常に現実的です。単語は非常に複雑な場合もあれば、非常に単純な場合もあります。従来のトークナイザーはこの問題をある程度バランスよく処理できますが、UTF-8を使用する場合、各単語は単語の長さに相当するトークンを消費する必要があり、計算リソースの割り当てが非常に困難になります。
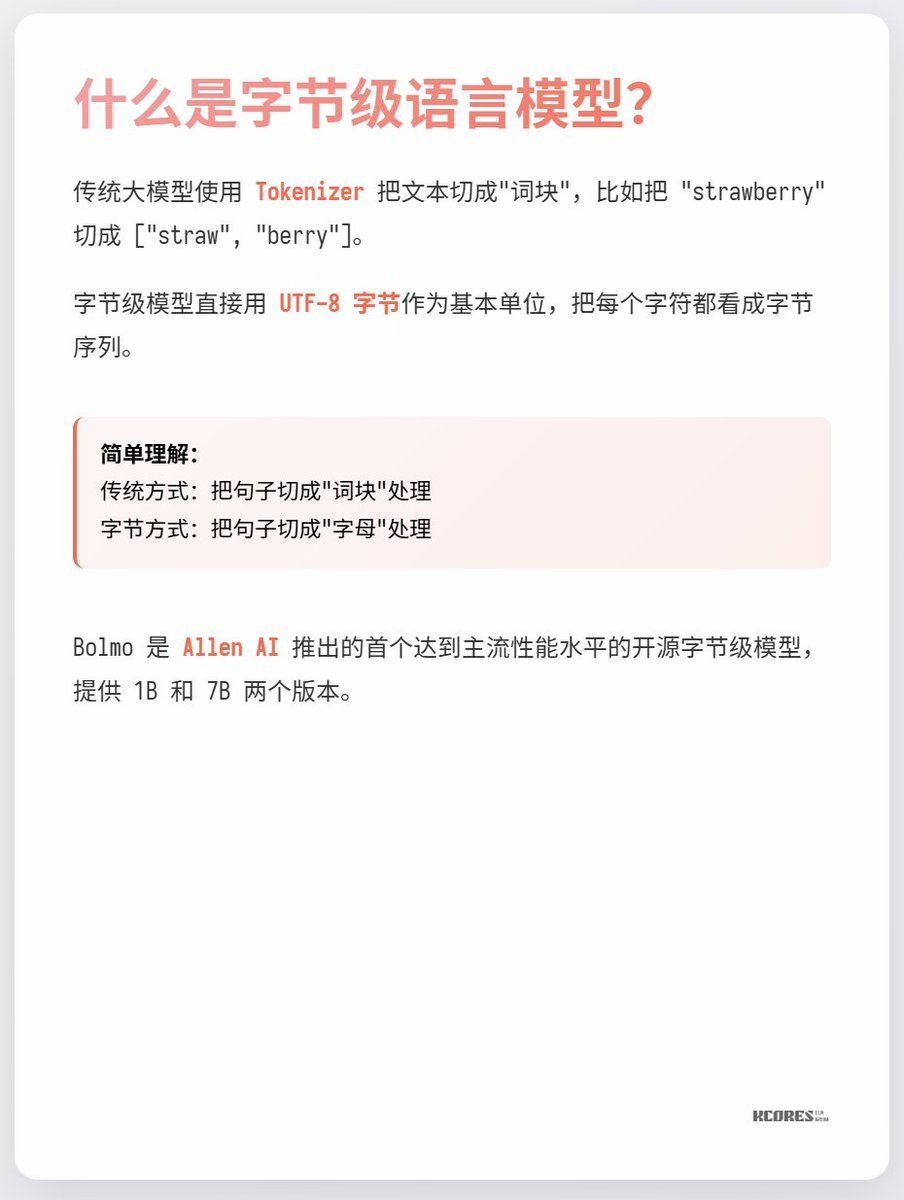



Bolmoのモデルは巧妙なアプローチを採用しています。ゼロから学習するのではなく、既存のモデルを「バイトエンコード」するのです。内蔵のローカルエンコーダ/デコーダがバイトシーケンスを「潜在的なトークン」に圧縮し、従来のTransformerに入力して処理します。これにより、最小限のオーバーヘッドで変換が可能になります。

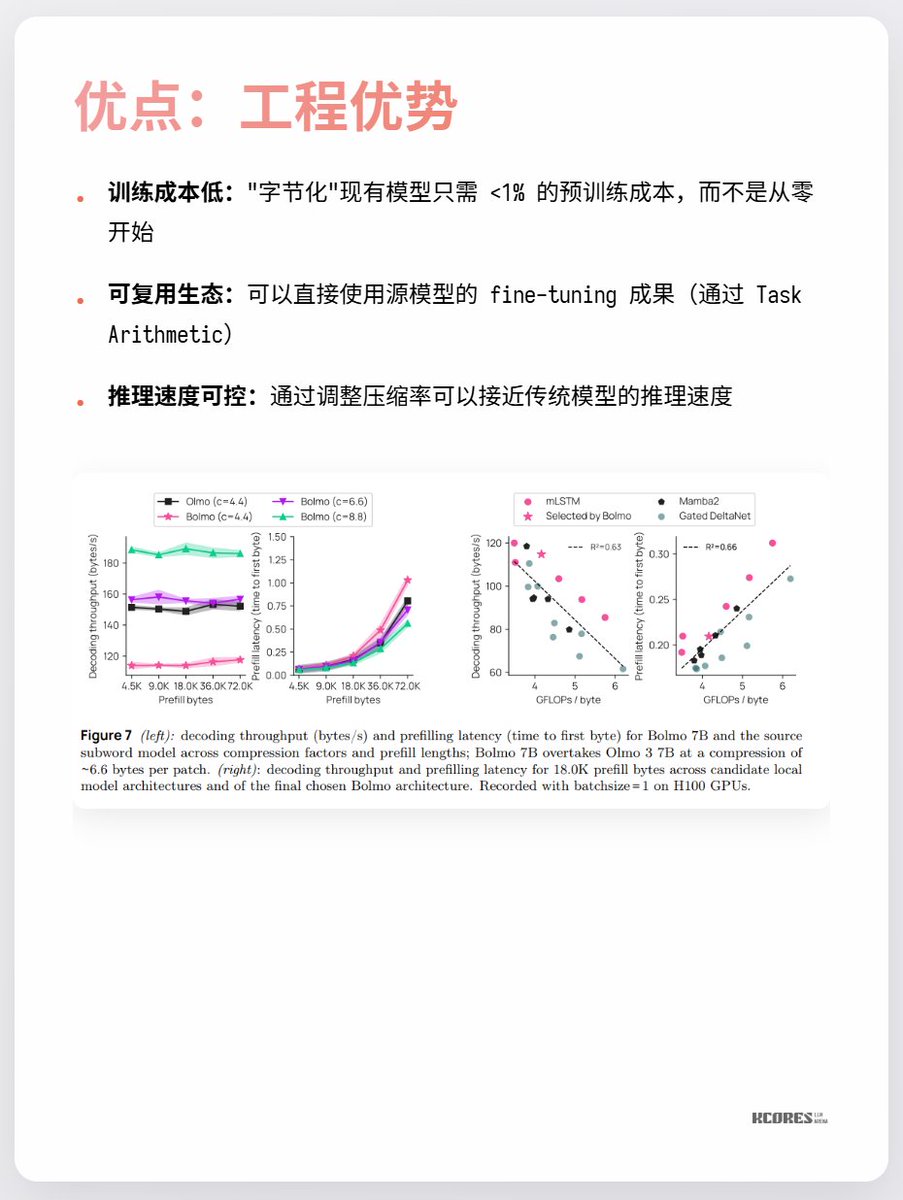

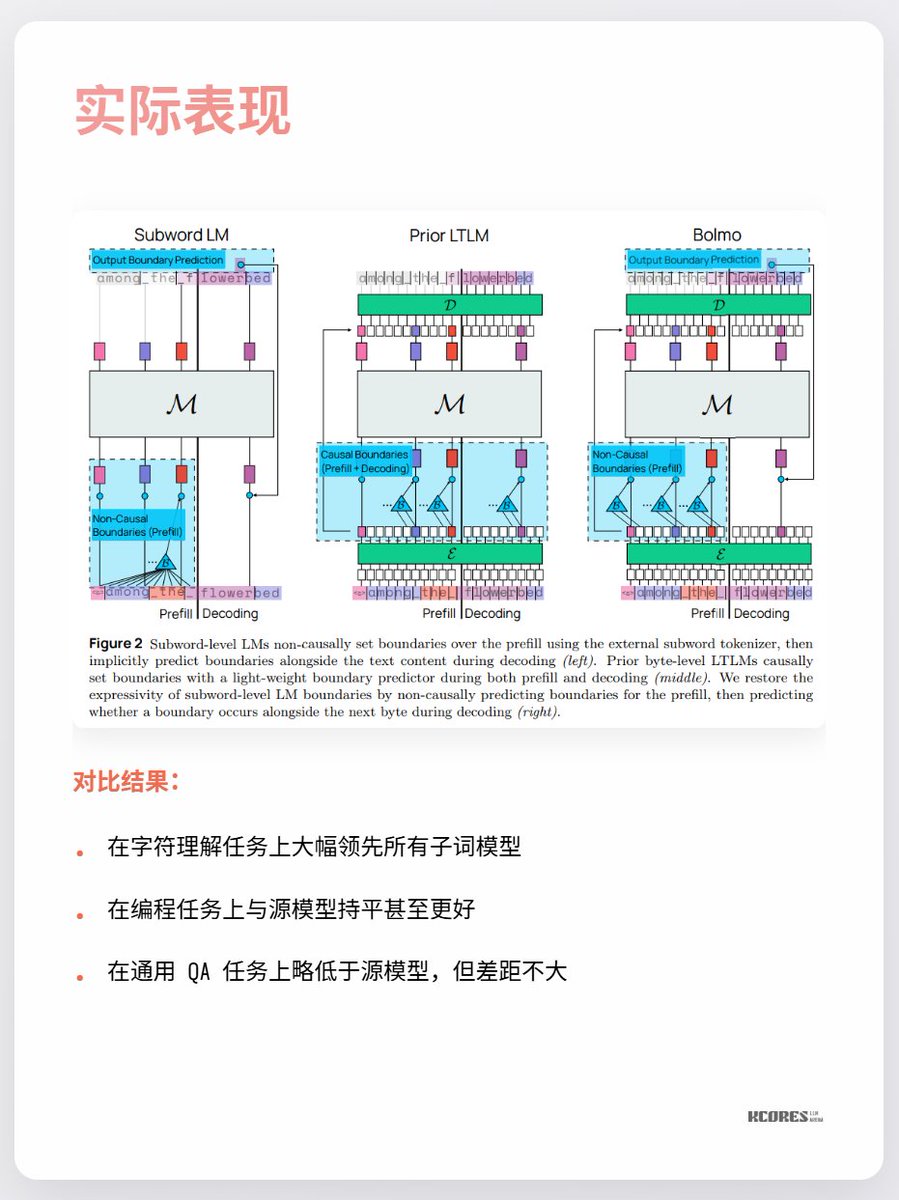
現時点での最大の論点は、目に見えるほどのメリットが見られない点と、シーケンスが長くなるとキーバリューキャッシュの容量が大きくなり、GPUメモリへの負荷が高まる点です。また、顕著なリードは文字認識という単一のタスクでのみ見られ、他のタスクでは目立った改善はほとんど見られません。 要するに、注目する価値があるということです。技術革新の時代におけるスパイラルな探求は常に非常に興味深いものです。例えば、個人的には水銀整流器(最後の写真)が好きでしたが、今ではIGBTに置き換えられています。

