NVIDIA は、GPT-OSS-120B 専用に設計されたアクセラレーション モデルをリリースしました。 NVIDIAは、gpt-oss-120bで動作するように特別に設計された新しいモデル「gpt-oss-120b-Eagle3-throughput」をリリースしました。これはgpt-oss-120bの投機的デコードのプレモデルとして使用でき、gpt-oss-120bモデルの出力速度を向上させます。 投機的デコーディングをご存知ない方のために説明すると、これは小さなモデルを用いてデータを出力し、その出力をまとめて大きなモデルに入力して修正するというものです。この方法では、小さなモデルが「正しく推測」すれば、速度は非常に速くなります。さらに、通常の文脈では、ストップワード(言語において非常に高い頻度で出現するが、文の核となる意味を区別するのにほとんど貢献しない単語)が依然として多く存在します。そのため、速度の向上は顕著です。

モデル情報 / 1




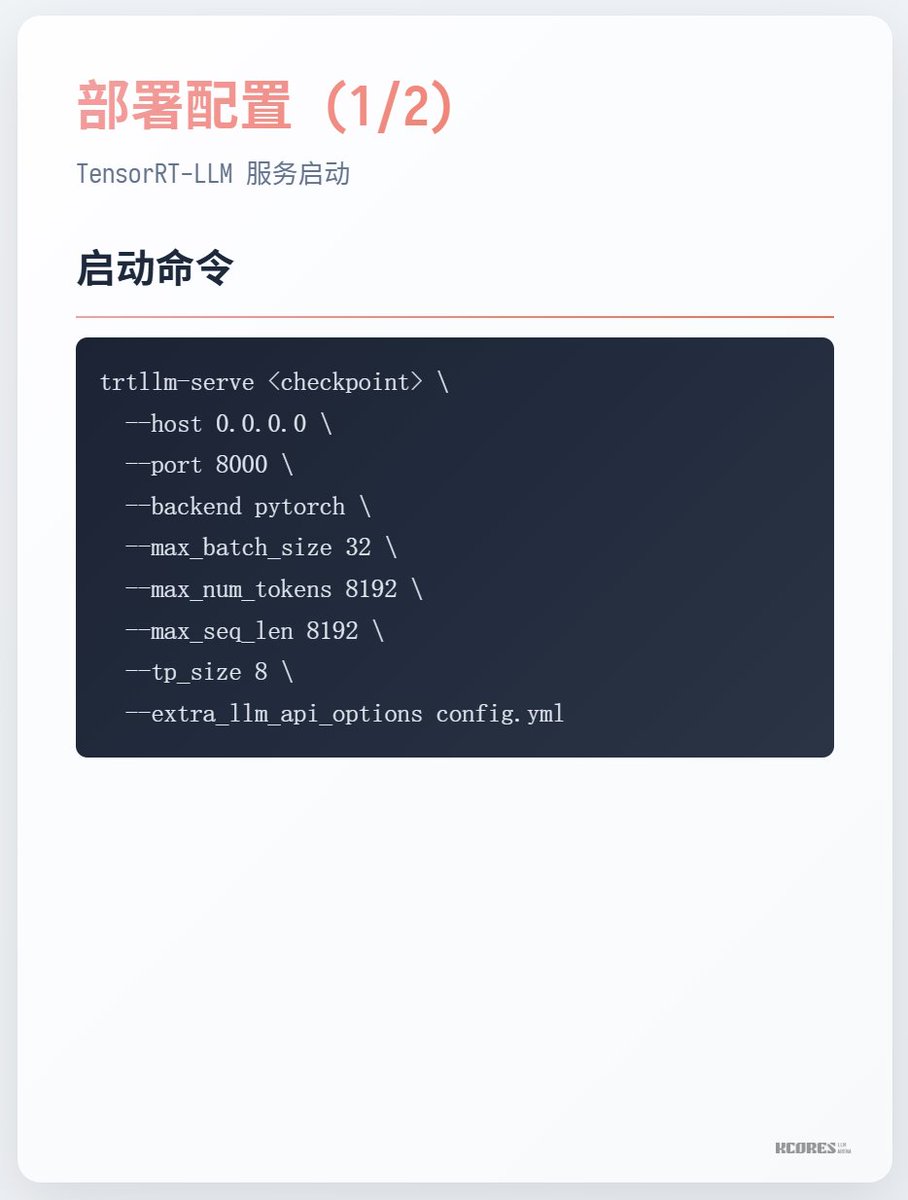
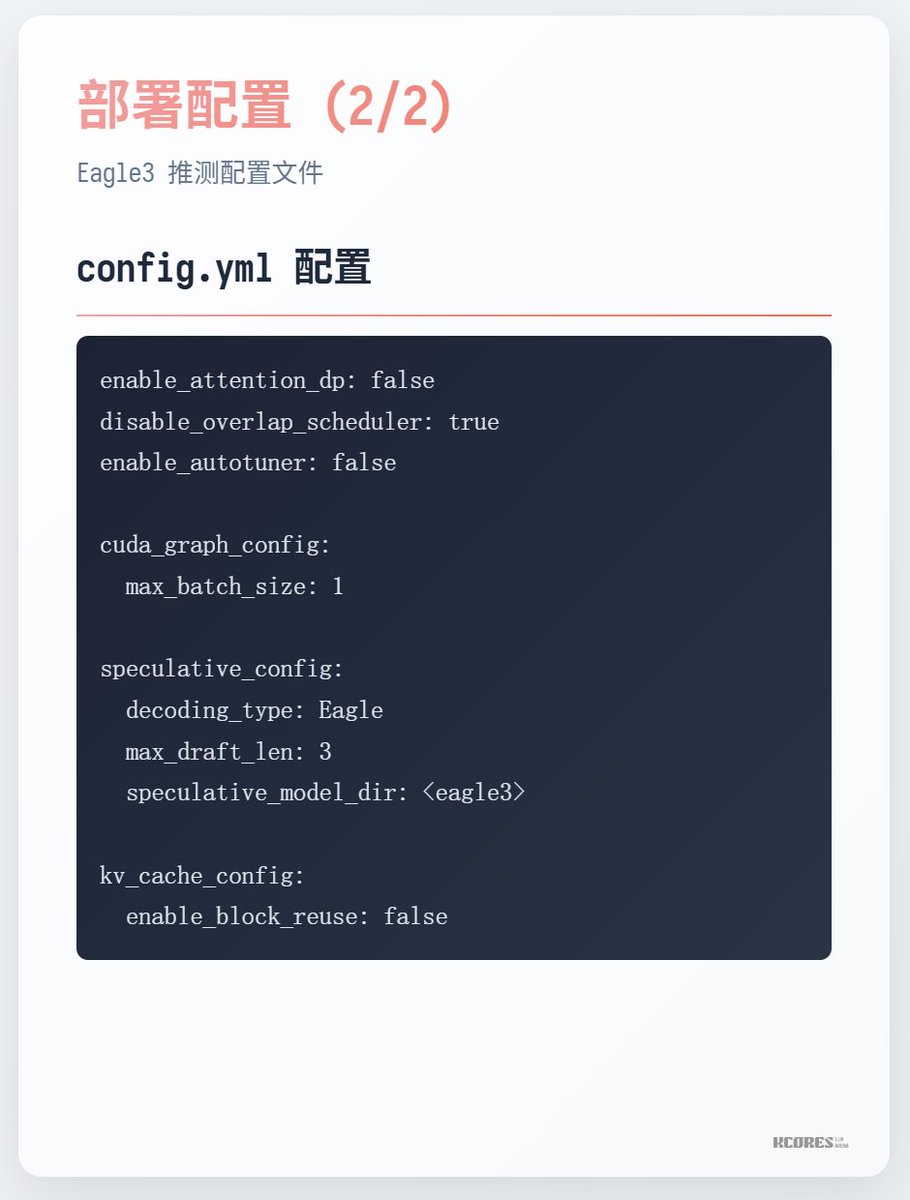
実行方法