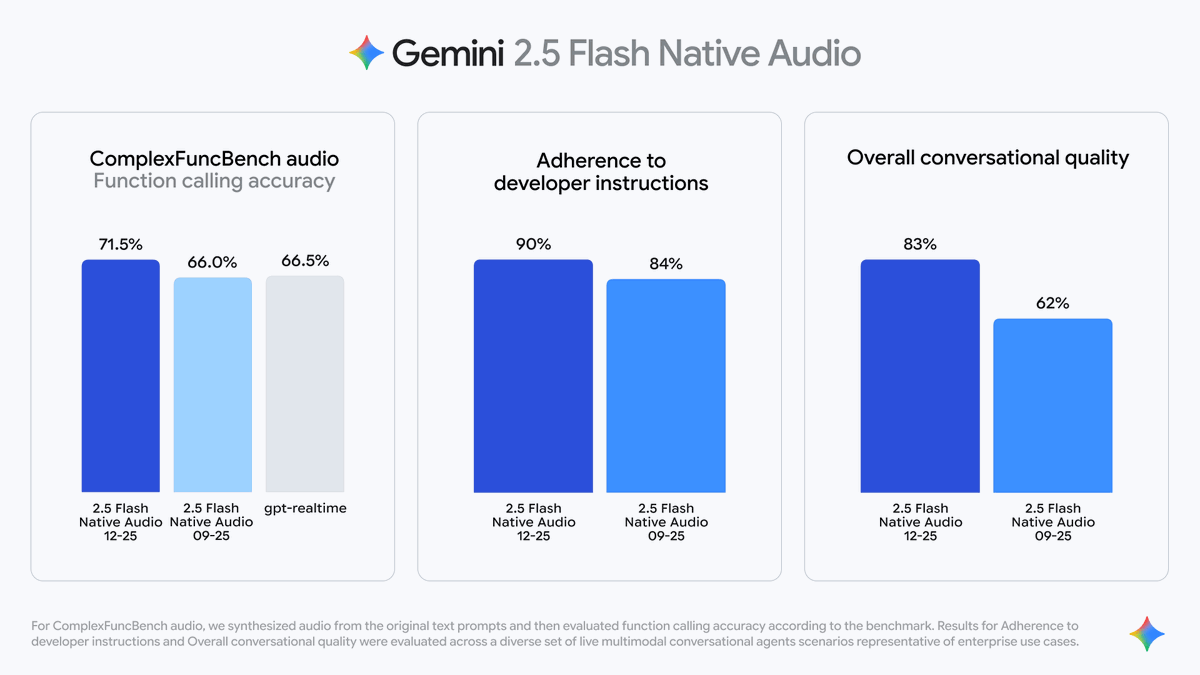
Googleが新しいGemini 2.5 Flash Native Audioモデルをリリース さまざまなリアルタイム音声アプリケーションを駆動するために使用される 「ネイティブ オーディオ」とは、最初にテキストを生成してから音声を合成するのではなく、自然な音声出力を直接生成するモデルの機能を指します。 「あなたの言うことを理解する」だけでなく、より自然な口調、リズム、間合いで「人間の声で即座に応答する」こともできます。 3 つのコア機能が包括的に強化されました。 1️⃣ よりスマートな「関数呼び出し」 Gemini は、音声会話中に次のような外部情報ソースに積極的にアクセスできるようになりました。 天気 API を呼び出します。 データベースをクエリします。 リアルタイムのニュースや株価情報を入手します。 ただ「答える」だけではなく、対話中にいつ情報を調べ、いつ会話を続けるかを判断し、「話しながら情報を調べる」ことでスムーズな音声の流れを維持できます。
2️⃣ 指導理解の向上 Gemini 2.5 Flash Native Audioは、複雑な音声指示をより正確に理解します。Googleのテストデータによると、次のようになります。 指示遵守率は 84% から 90% に増加しました。 出力コンテンツの完全性と正確性が大幅に向上しました。 3️⃣ 会話の流暢さの向上 Gemini 2.5 Flash Native Audio は複数の会話のコンテキストを記憶できるため、音声の遷移がより自然になります。
Gemini 2.5 Flash Native Audio モデルは Vertex AI で完全に利用できるようになり、Gemini API (プレビュー) でも使用できxiaohu.ai/c/xiaohu-ai/go…/t.co/CnBlan3RBh