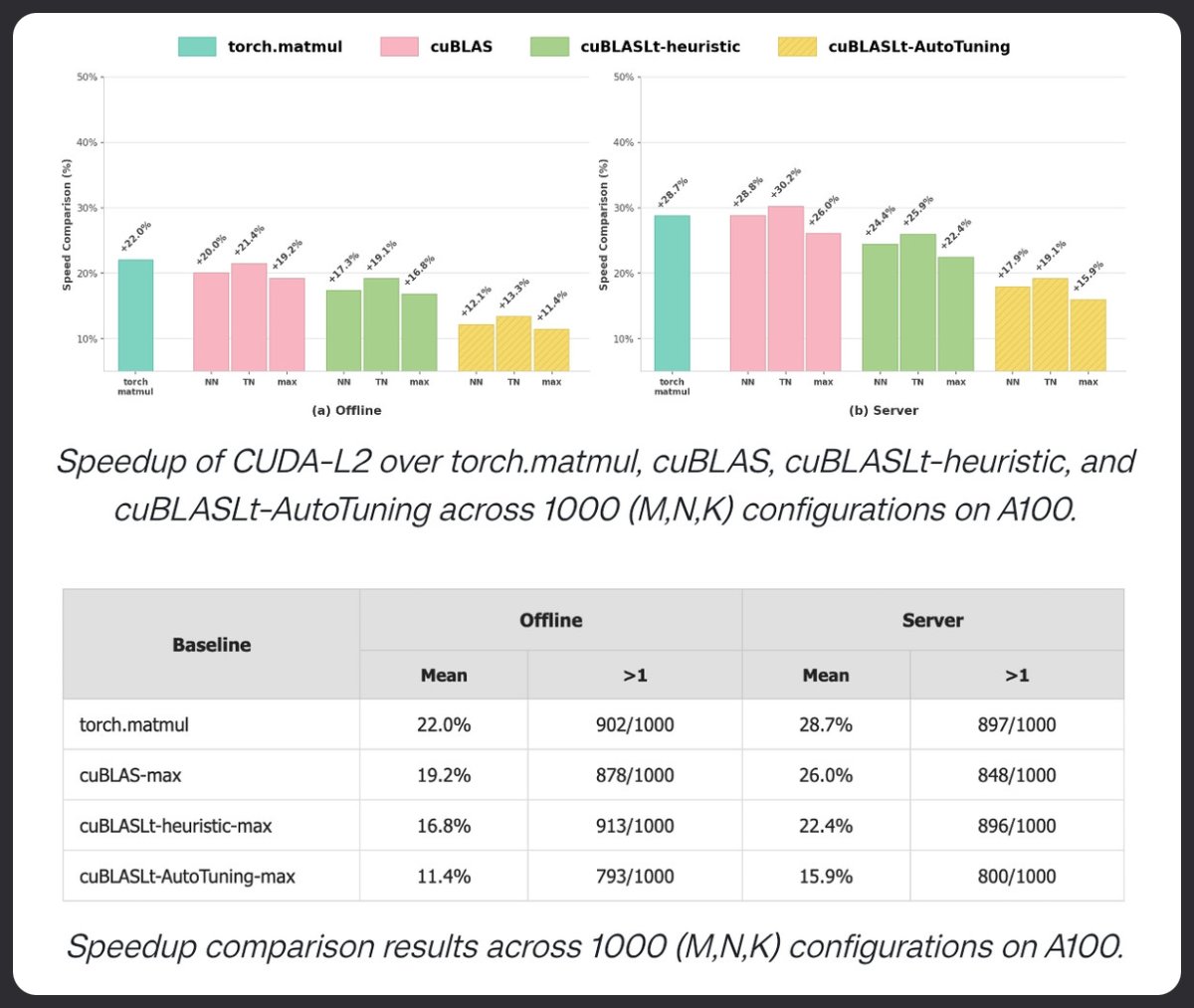
CUDA-L2 は強化学習を使用して、行列乗算において cuBLAS よりも優れたパフォーマンスを発揮します。 1000 の HGEMM 構成でテストされ、A100 上の torch.matmul、cuBLAS、cuBLASLt AutoTuning よりも優れています。 オフラインモードでは+22%。 サーバーモードでは+28.7%。 LLM は現在カーネルを調整しています。
📄 論文: htarxiv.org/pdf/2512.02551🔗 GitHub: github.com/deepreinforce-…