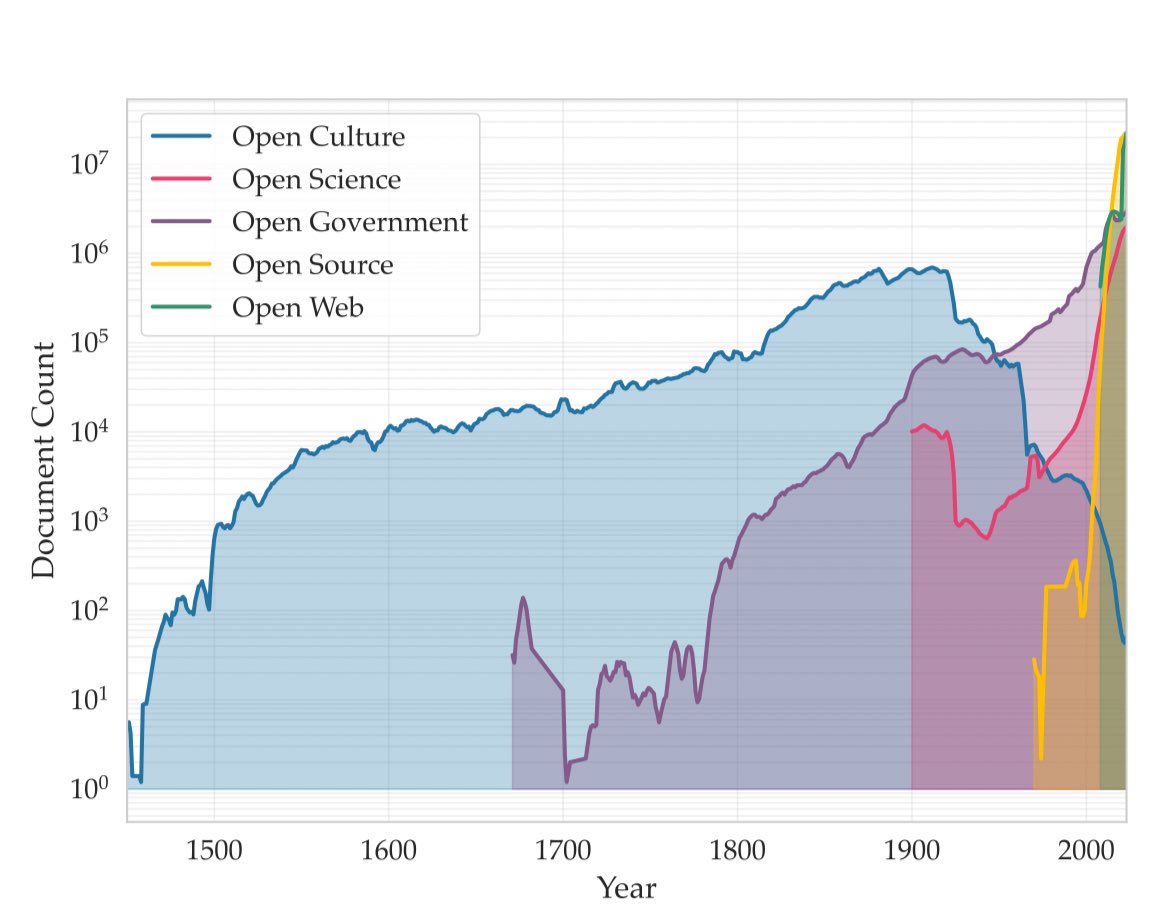
Common Corpus には、この種のプロジェクトで利用可能な最大のデータセット (1950 年以前の約 9,000 億トークン) があることを思い出してください。
しかし今は、時間ロックモデルのための合成環境アプローチに興味があります。ローマ時代の推論モデルも実現可能かもしれません。
スレッドを読み込み中
X から元のツイートを取得し、読みやすいビューを準備しています。
通常は数秒で完了しますので、お待ちください。
2 件のツイート · 2025/12/12 17:35
Common Corpus には、この種のプロジェクトで利用可能な最大のデータセット (1950 年以前の約 9,000 億トークン) があることを思い出してください。
しかし今は、時間ロックモデルのための合成環境アプローチに興味があります。ローマ時代の推論モデルも実現可能かもしれません。