いわゆる「スティールマン」的な言い方をしましょう。多くの人がこの議論の強すぎるバージョンを信じているように思います。しかし、基本的に正しい他のバージョンもたくさんあると思います。
例えば、真だが未知の命題Pについて「知識を生成する」とはどういう意味でしょうか?文脈命題Cが存在し、それがLLMから真でありPを示唆する「論証」Aを引き出すことを意味すると思います。もしそれが実現すれば、Pに関する知識が生成されたことになります。
つまり、引用した議論の中で最も明らかに間違っているのは、そんなことは起こり得ないというものです。明らかに起こり得るし、実際にいつも起こっています。しかも、ほとんどの場合、些細な形で。私のアプリの機能を実装するコードが分かりません。法学修士(LLM)に問い合わせると、コードが生成されます。すると、新しい知識が得られます。
さて、それではスティールマンニングを始めましょう。まず、最も基本的な点から。LLMが「知っている」ことは、短期的には静的です。セッションとセッションの間にはすべて忘れてしまいます。Aを導出したからといって、自動的にPを「知る」わけではありません。これは人間とは少し違うようです。
ユークリッドがI.46「正方形を作図できる」を証明すると、I.46は彼の知識の一部となり、それを応用してピタゴラスの定理を証明できるようになります。一方、法学修士がPを証明しても、Pは同じように「法学修士の知識の一部」にはなりません。
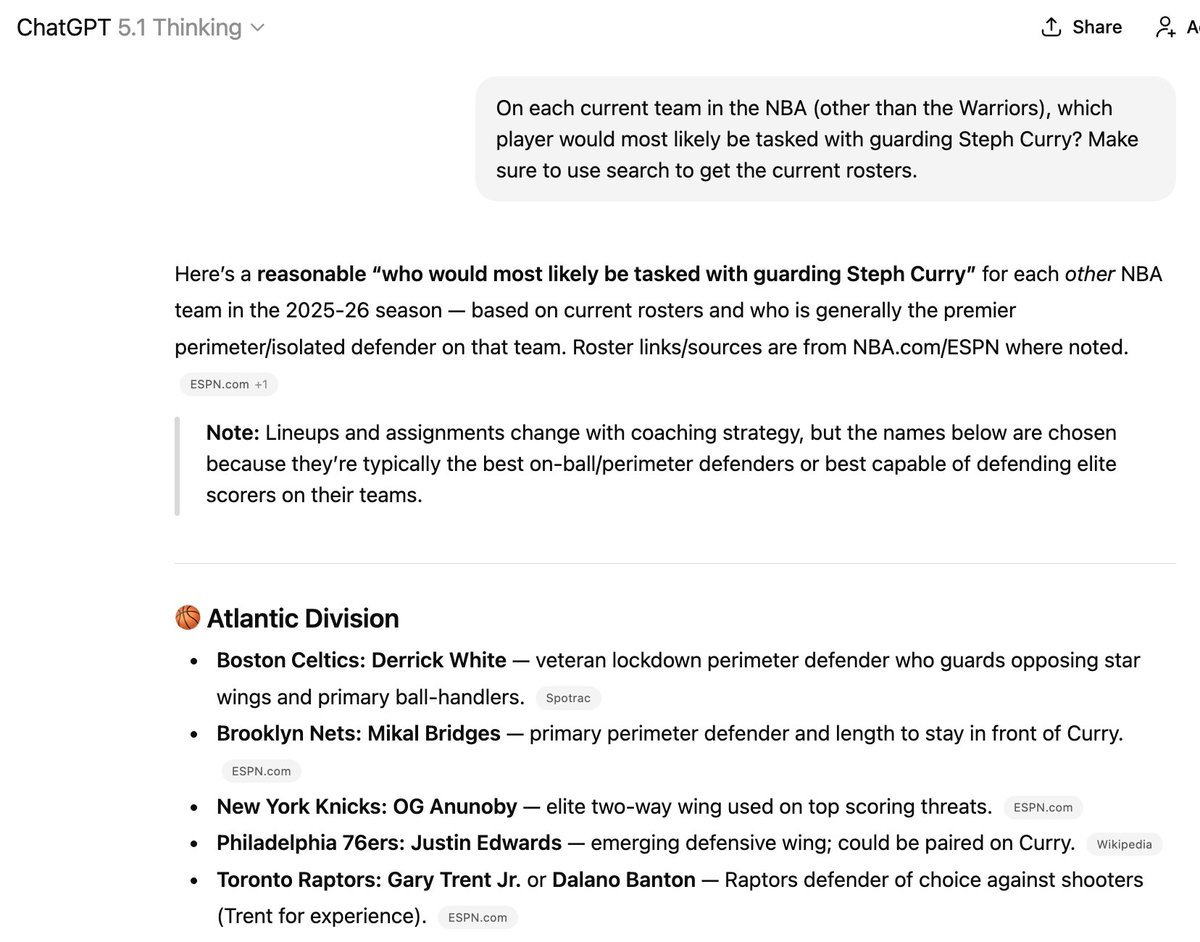
Pを訓練データに組み込む方法はいくつかありますが、依然として信頼性が低いです。だからこそ、このようなことが起こるのです。ここで挙げた6人の選手のうち3人は、リストに載っているチームに所属していませんが、新しいことを「学習」させるのは至難の業です。
(余談ですが、NBAチームのコーチとしてこの機器を雇うことはお勧めしません)

この点は、「既に発見された情報としか組み合わせることができない」という主張と一致しています。AIは自分が知っていることを知っているのです。それは短期的には(つまりトレーニングの間は)基本的に静的ですが、長期的には予測不可能に進化します。
この点は、がん治療などの主張において重要だと思います。がん治療はパトナム問題を解くようなものではありません。現在知られていない、あるいは既存の信念と矛盾する可能性のある新たな事実を追跡し、それらを結びつけていく必要があります。
ある意味、これはどの選手がどのバスケットボール チームに所属しているかを追跡することに似ていると思います。これは、無制限のインターネット アクセスを備えた最も博士レベルの推論モデルでも、今日に至るまで絶望的な作業です。
さて、スティールマンニングのもう一つの方向性について。LLMはAを決定論的に生成するわけではありません。ある確率でAを生成します。別の確率でB(「bad argument」の略)を生成する可能性があり、これは~Pを意味します。そして、それらの確率が実際にどれくらいなのかは、私たちには分かりません。
これをどう解釈すればいいのでしょうか? 正解を出したものは「知識を生成」したのでしょうか? こちらでは、私がスティールマンしている引用ツイートで説明されているように、様々な数学的情報の断片を組み合わせ、リミックスしているのです。


手作業のものも自動化されたものも含め、様々な手段を用いて、これらの議論が正しく、その結論が真実であるかどうかを検証することができます。その過程で、これまで知られていなかった、正しい議論と真の結論を発見できる可能性が高くなります。
しかし、私にとっては、これは自律的な知識の「生成」というよりは、知識の「抽出」というプロセスに近いものです。法学修士課程には、多くの真実と多くの虚偽が含まれています。課題は、真実を抽出し、虚偽を捨て去ることです。
他の多くのLLM愛好家とは異なり、私は、誇張されたオートコンプリートやランダムな次のトークン推測こそが、これらのことについて考える上で最も正確で有用な方法だと考えています。これは、長年の熱心なLLM愛好家として私が言いたいことです。多くの人がこの解釈に異議を唱えているように思います。
ランダムな次のトークンの推測から何か新しいことを学ぶことはできないという根拠。しかし、もちろんできます!同じ長さの針を硬い床にたくさん落とせば、交点を数えてπの値を推定できます。そこから抽出できる情報は山ほどあります。
方法さえ分かれば、ランダムプロセスも使えるでしょう。でも、実際にどれだけの効果があるのか、ちょっと疑問です。もしかしたら、がんの治療法がどこかに隠されていて、適切なヒントを提示するだけでいいのかもしれません。あるいは、未解決のエルデシュ問題と、簡単に解決できる問題がいくつかあるだけで、それだけかもしれません。