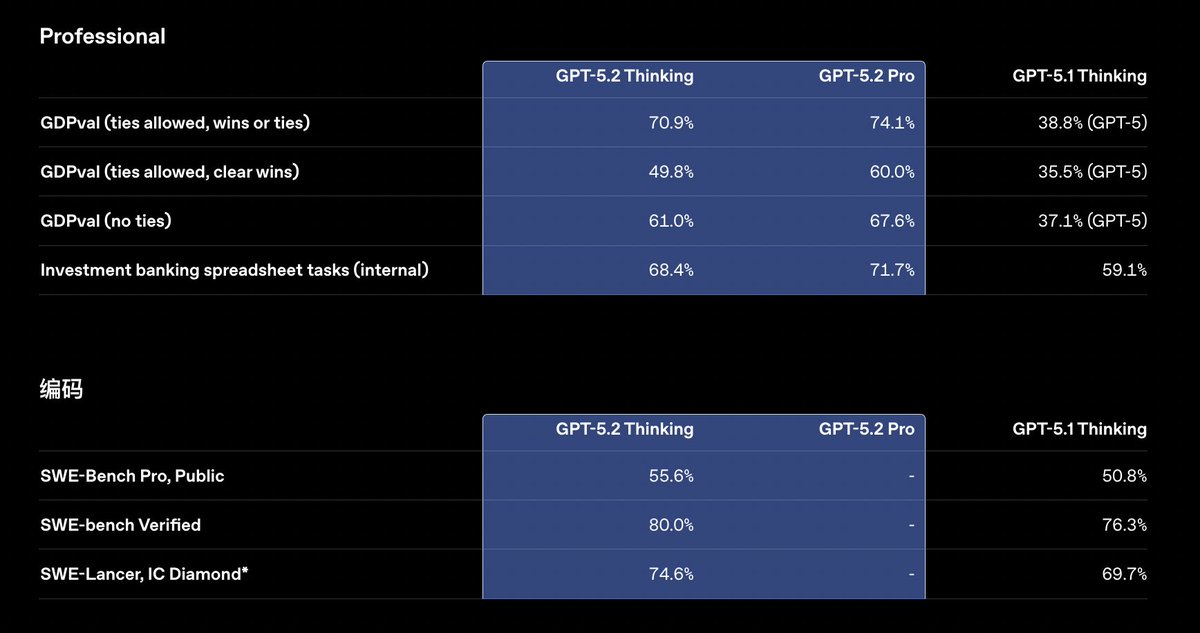
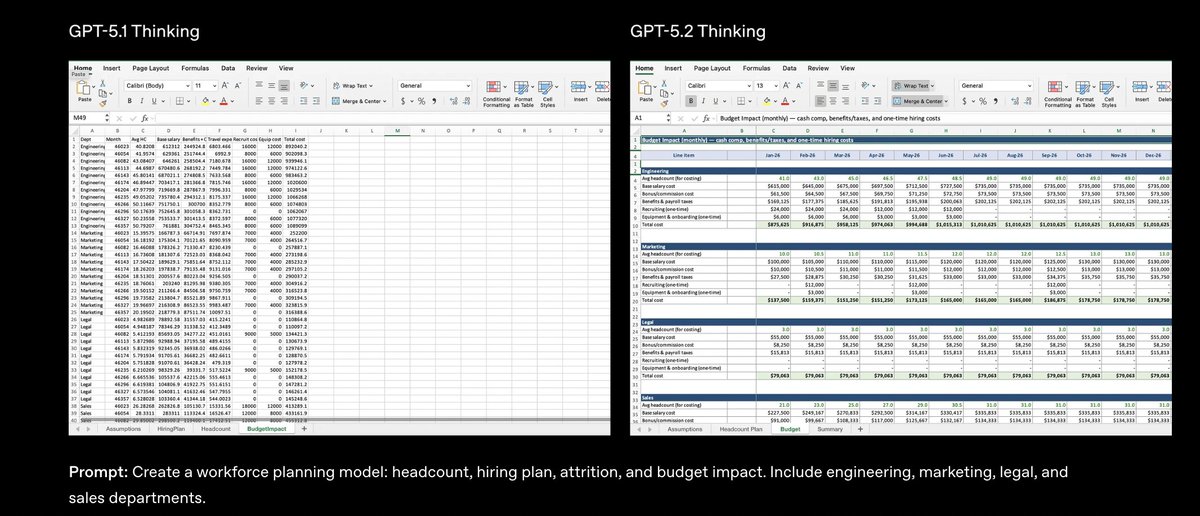
GPT-5.2 がリリースされ、知識労働、プログラミング、科学研究、長い文書、ビジョンタスクにおける業界の限界が包括的に引き上げられました。 インスタント、思考、プロの 3 つのレベルが含まれます。 GPT-5.2 思考は、GDPval (44 の職業知識タスクを測定する評価) で「人間の専門家レベル」を達成し、70.9% のケースで業界の専門家と同等かそれ以上の成果を上げ、専門家の 11 倍の速度と 1% 未満のコストを実現しました。 彼らは特にスプレッドシートとプレゼンテーションの作成に熟練しており、投資銀行のスプレッドシート モデリング タスクの平均スコアは GPT-5.1 よりも 9.3% 高くなっています。 つまり、これまで AI にコードの記述、PPT プレゼンテーションの作成、財務モデルの構築を依頼した場合、提供されるのはドラフトのみで、形式、数式、参照、外観などはすべて手動で修正する必要がありました。 要件が満たされると、数式、書式設定、配色、コメントがすべて含まれた Excel/スライド ファイルを一度に送信できるようになります。 コーディング能力: SWE-Bench Pro で 55.6%、SWE-bench Verified で 80%、フロントエンド 3D と複雑な UI を一度に生成する機能が強化されています。 数学および物理学の研究: AIME 2025数学コンペティションで100%の正解率を達成 FrontierMath T1-3 40.3% (+9.3 pct) は、研究者が統計学習理論の新たな証明を完成させるのに役立ちました。 GPQA ダイヤモンド卒業生レベル Q&A: 92.4%、プロレベル: 93.2%。 長いテキストとビジュアル: 256,000 トークン内では、「4 針」トークンの取得率はほぼ 100% であり、MRCRv2 セグメントが平均 30 プロットリードしています。 チャート、ダッシュボード、マザーボード画像を認識する際のエラー率が半減し、Python ツールとの統合をサポートします。 ツールの呼び出しとインテリジェントエージェント: Tau2-bench は、China Telecom のシナリオで 98.7% の成功率を誇り、ユーザーはフライトの変更、手荷物の追跡、特別座席のリクエストなど、複数のシステムにわたる 10 以上のステップを単一のプロセスで完了できます。 幻覚の軽減: 実際、ChatGPT 応答のエラー率は 30% 減少し、検索を有効にするとエラー率は 93.9% に達しました。 入力 1.75 / 1M トークン (0.175 キャッシュ)、出力 14; プロバージョン 21 / 168$ ChatGPT Plus以上のユーザーは、本日より段階的な展開を開始し、APIが完全にリリースされます。 #GPT52 #オープンAIGPT
ブログopenai.com/zh-Hans-CN/ind…IL