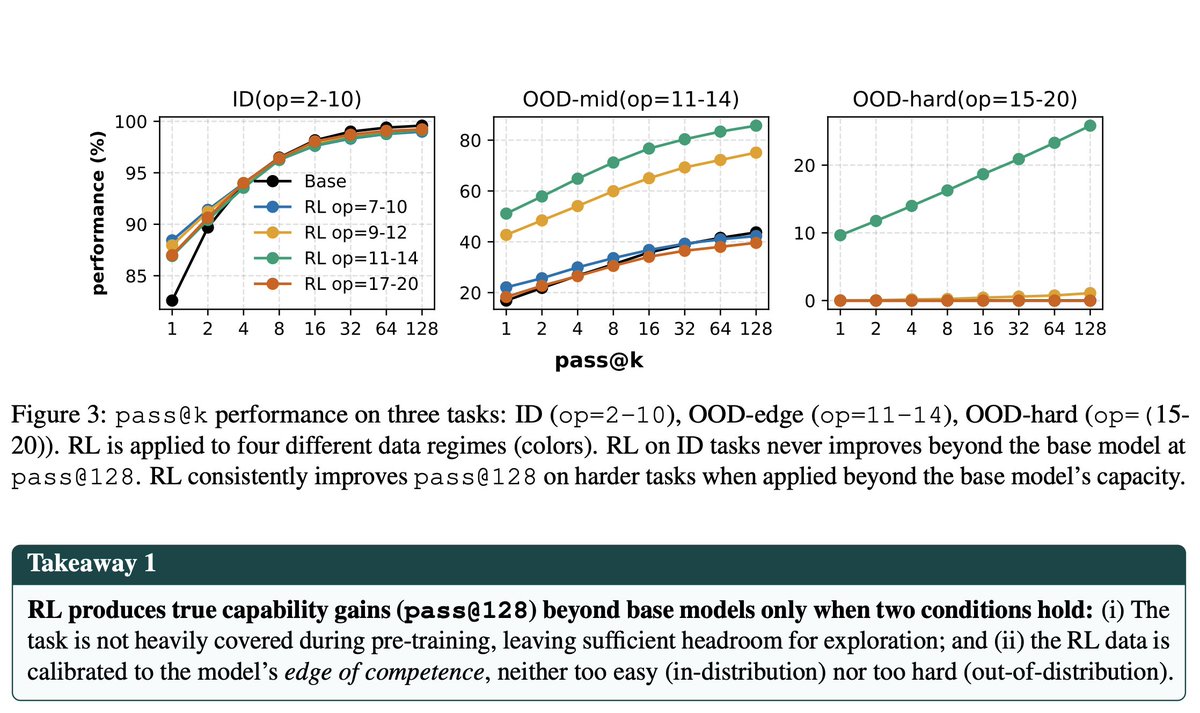
彼らはモデルを擬人化してはいけないと言い続けていますが、優れた技術はすべて、これまでずっと人間、行動、学習について研究されてきたことの類推であるように思われます。 「RLは、タスクが能力の限界にあるときに最も効果を発揮します」

これは興味深い論文なので、一読することをお勧めします。ただし、ここに記載されている情報のほとんどは、実務経験を積んだ人なら経験から知っている内容です。 しかし、とても良く書かれていて楽しく読むことができました。
スレッドを読み込み中
X から元のツイートを取得し、読みやすいビューを準備しています。
通常は数秒で完了しますので、お待ちください。
2 件のツイート · 2025/12/10 21:02
彼らはモデルを擬人化してはいけないと言い続けていますが、優れた技術はすべて、これまでずっと人間、行動、学習について研究されてきたことの類推であるように思われます。 「RLは、タスクが能力の限界にあるときに最も効果を発揮します」
これは興味深い論文なので、一読することをお勧めします。ただし、ここに記載されている情報のほとんどは、実務経験を積んだ人なら経験から知っている内容です。 しかし、とても良く書かれていて楽しく読むことができました。