Anthropic Fellows プログラムからの新しい研究: Selective GradienT Masking (SGTM)。 私たちは、高リスクの知識(危険な武器に関する知識など)が、モデルに広範囲な影響を与えることなく削除できる小さな別のパラメータセットに分離されるようにモデルをトレーニングする方法を研究しています。

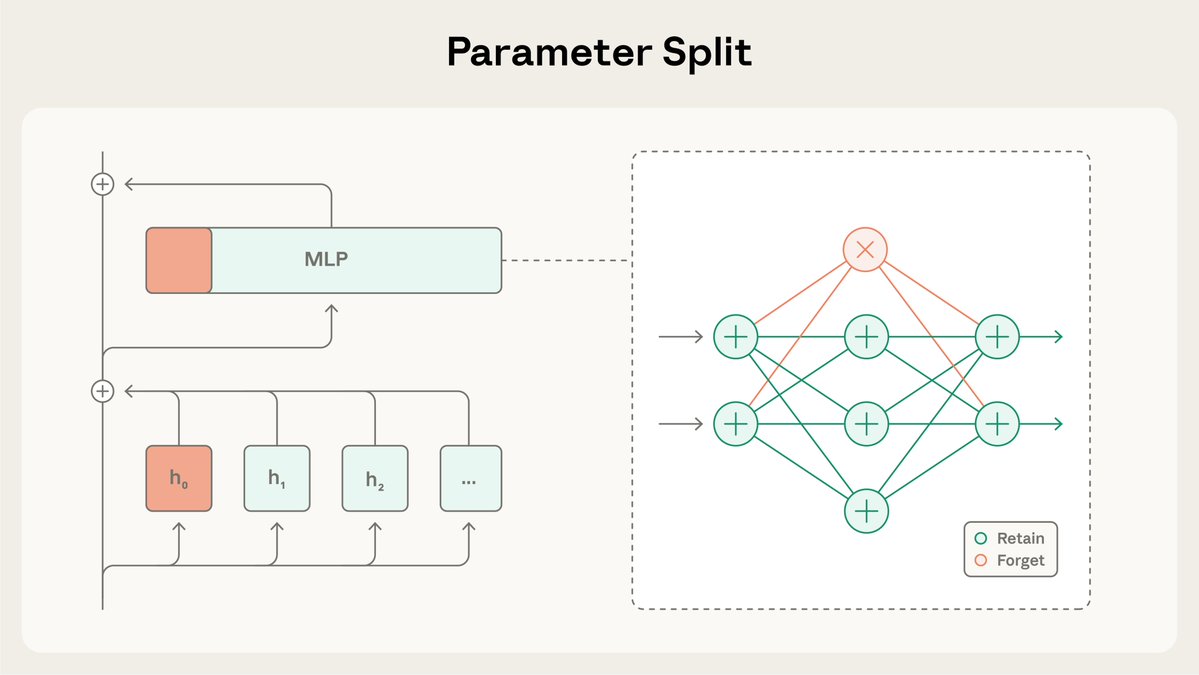
SGTMはモデルの重みを「保持」サブセットと「忘却」サブセットに分割し、事前学習中に特定の知識を「忘却」サブセットに誘導します。その後、高リスク環境での展開前に、この知識を「忘却」サブセットから削除することができます。 詳細はこちら:https://t.co/BfR4Kd86b0
本研究では、SGTMがWikipediaで学習したモデルから生物学の知識を除去できるかどうかを検証しました。生物学以外のWikipediaページにも生物学に関するコンテンツが含まれている可能性があるため、データフィルタリングによって関連情報が漏洩する可能性がありました。
一般的な機能を制御すると、SGTM でトレーニングされたモデルは、データ フィルタリングでトレーニングされたモデルよりも、望ましくない知識の「忘れる」サブセットでのパフォーマンスが低下します。

トレーニングが完了した後に行われる学習解除方法とは異なり、SGTM は元に戻すことが困難です。 SGTM で忘れられた知識を回復するには、従来のアンラーニング手法である RMU と比べて 7 倍の微調整ステップが必要です。

この研究には限界がありました。標準的なベンチマークではなく、小規模なモデルと代理評価を使用した簡略化された設定で実行されたのです。 また、データ フィルタリングと同様に、SGTM は、攻撃者が自ら情報を提供するコンテキスト内攻撃を阻止しません。
SGTMに関する完全な論文はこちらをご覧ください: https://arxiv.org/abs/2512.05648するために、関連コードを GitHub でも公開しています: https://t.co/zRmJYy6bDE。
この研究は、Anthropic Fellows プログラムの一環として @_igorshilov が主導しました。