数日前、@NeurIPSConf で2025 BEHAVIOR Challengeの1位を獲得したソリューションを発表しました。そして今、コード、モデルの重み、そして詳細な技術レポートを含むソリューションをオープンソース化しました。 私たちが何をしたのか詳しく説明しましょう👇
BEHAVIORチャレンジとは何ですか? このコンテストでは、高品質のシミュレーションで 50 種類のロボットによる家事作業を完了できるポリシーをトレーニングする必要がありました。 このポリシーは、移動ベースを備えた両手操作のヒューマノイド ロボットを制御し、タスクの範囲は 1 分から 14 分です。 詳細は@drfeifeiの投稿をご覧ください: https://t.co/jDviv5d6pB
私、@zaringleb、@akashkarnatak からなる独立チームは、Q スコア 26% (完全成功と部分成功を含む) で 1 位を獲得しました。
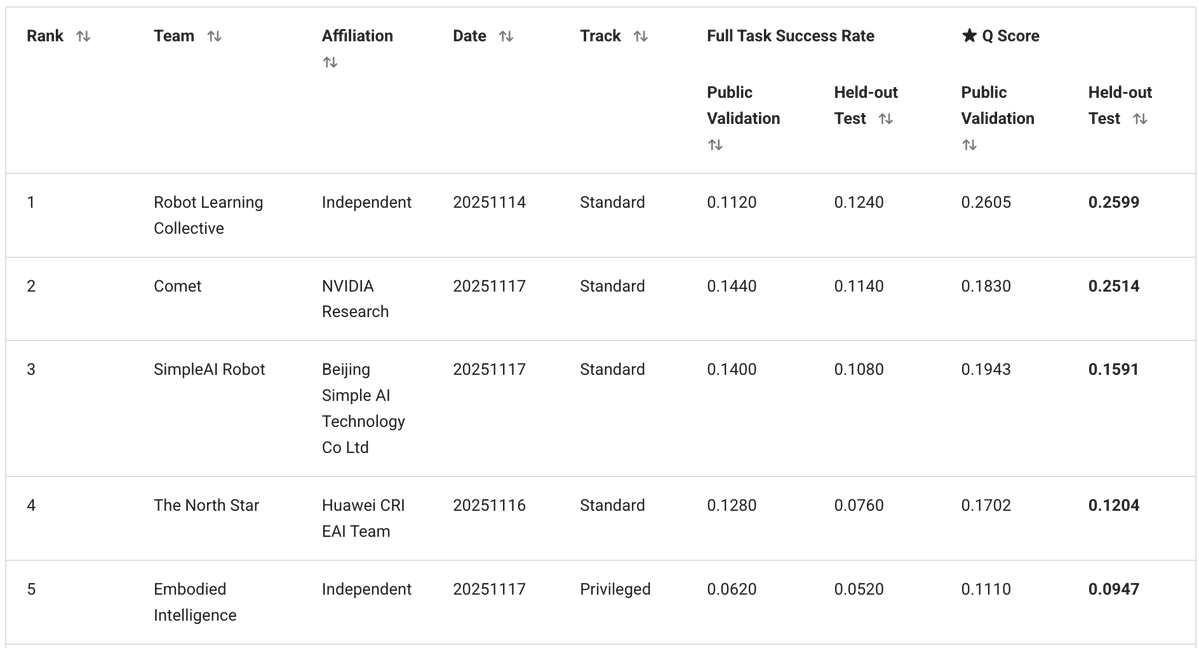
私たちのソリューションは、@physical_int Pi0.5 VLA に基づいており、openpi リポジトリ上に構築されています。 モデルとトレーニングおよび推論プロセスを大幅に変更しました
- BEHAVIORには50個の固定タスクセットがあります。新しいテキストプロンプトに一般化する必要がないため、テキストを完全に削除し、50個のトレーニング可能なタスク埋め込み(タスクごとに1つ)に置き換えました。 - トレーニング データセットには、複数のモダリティ (RGB、深度、セグメンテーション) と追加のサブタスク注釈が含まれていましたが、RGB 画像 + ロボットの状態のみというシンプルなアプローチを採用しました。 - 30 ステップのアクション チャンク (1 秒) を予測し、タイムスタンプごとに正規化されたデルタ アクションを使用します。
多くのフレームは同一に見えますが、非常に異なるサブタスクに対応しています。 例えば、次の2つの画像では、片方は電子レンジが空で、ロボットはまず電子レンジを開ける必要があります。もう片方では、ポップコーンがすでに電子レンジの中に入っており、ロボットは電子レンジの電源を入れる必要があります。どちらがどちらなのか分かりますか? ロボットにとっても混乱を招きます。VLAはデフォルトではメモリを持っていないため、次に何をすべきか正確にはわかりません。


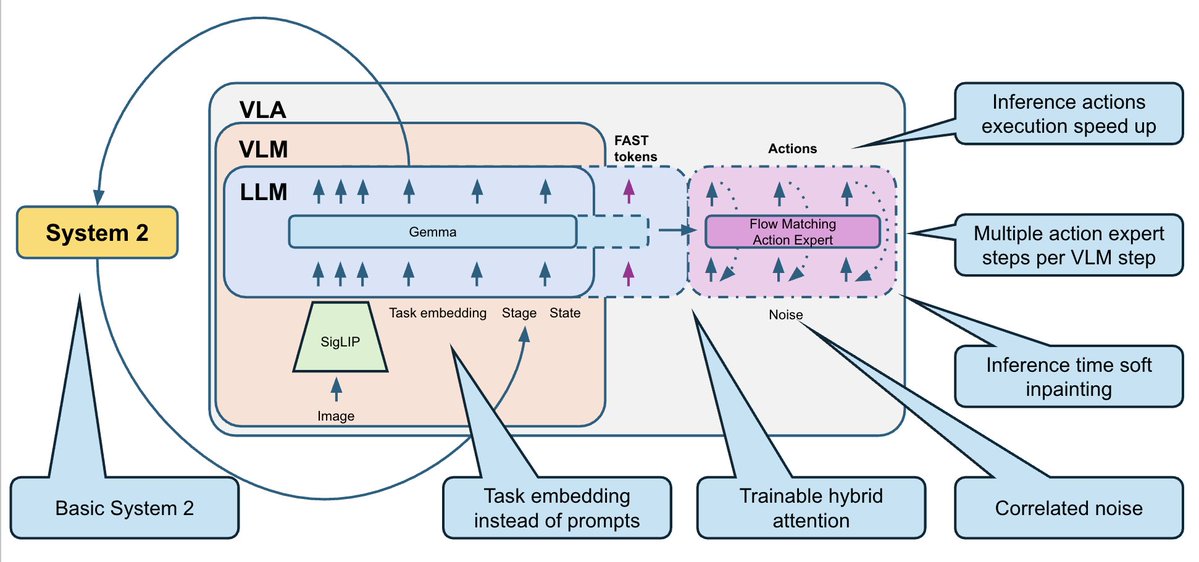
これを修正するために、タスクの完了の進行状況を追跡する非常に基本的なシステム 2 ロジックを追加しました。 - 補助ヘッドとして現在のステージを予測するように VLA をトレーニングします。 - 同時に、ステージを使用して現在のフレームの曖昧さを解決することもできます。 - 推論中、投票ロジックを使用してステージ予測を平滑化します。ステージはステップごとにのみ進行します (0、1、2、3、...)。 - ステージを追加入力としてモデルにフィードバックします。 これにより、ポリシーにタスクの進行状況のコンテキストが追加され、「自分がどこにいるか忘れた」という失敗の多くが修正されます。
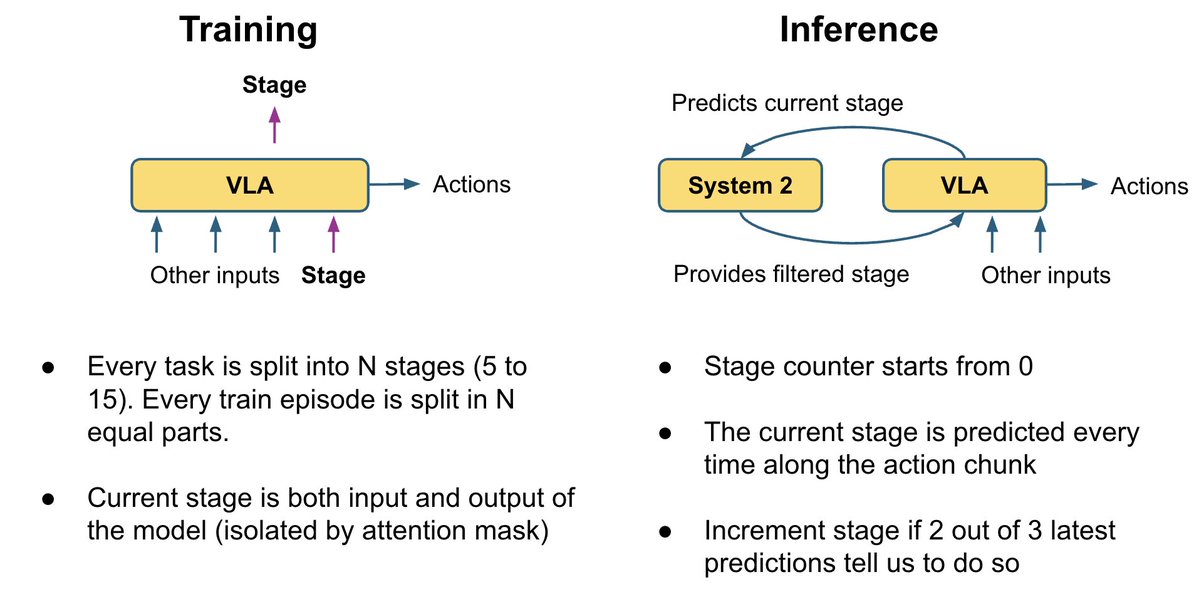
VLA論文によって、アクションヘッドとVLMレイヤーの接続方法は異なります。すべてのVLMレイヤーに注目するものもあれば、半分をスキップするもの、最後のレイヤーのみに注目するもの、クロスアテンションとセルフアテンションを別々に使うもの、あるいは両方を混ぜて使うものもあります。これらの選択肢のいずれかを選択してハードコーディングするのではなく、モデルに各アクションレイヤーに最適な組み合わせを学習させます。 私たちのアクション エキスパートは、すべての VLM レイヤーのトレーニング可能な線形結合に注目し、各アクション レイヤーの最適な組み合わせを学習できるようにします。
標準的なフローマッチングでは、IIDガウスノイズが使用されます。しかし、ロボットの動作は時間経過と関節間の相関が非常に高いです。 これにより、フロー マッチングの手順の難易度が不均等になります。最初の手順は非常に難しくなりますが、モデルが既知の相関関係をショートカットとして使用できるため、後の手順は非常に簡単になります。 代わりに、N(0, I)ではなくN(0, 0.5 Σ + 0.5 I)からのノイズを使用します。ここで、Σはデータセットから推定された行動共分散行列です。これは、すべてのステップの難易度をより均一にすることを目的としています。
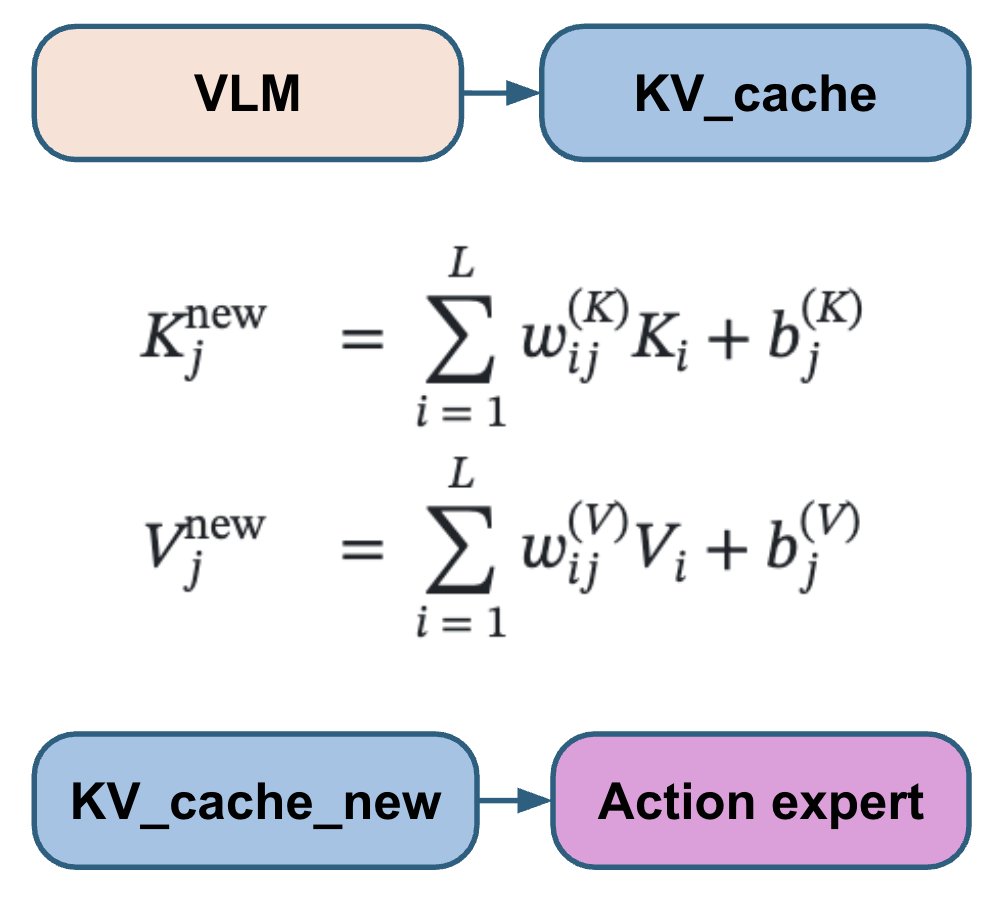
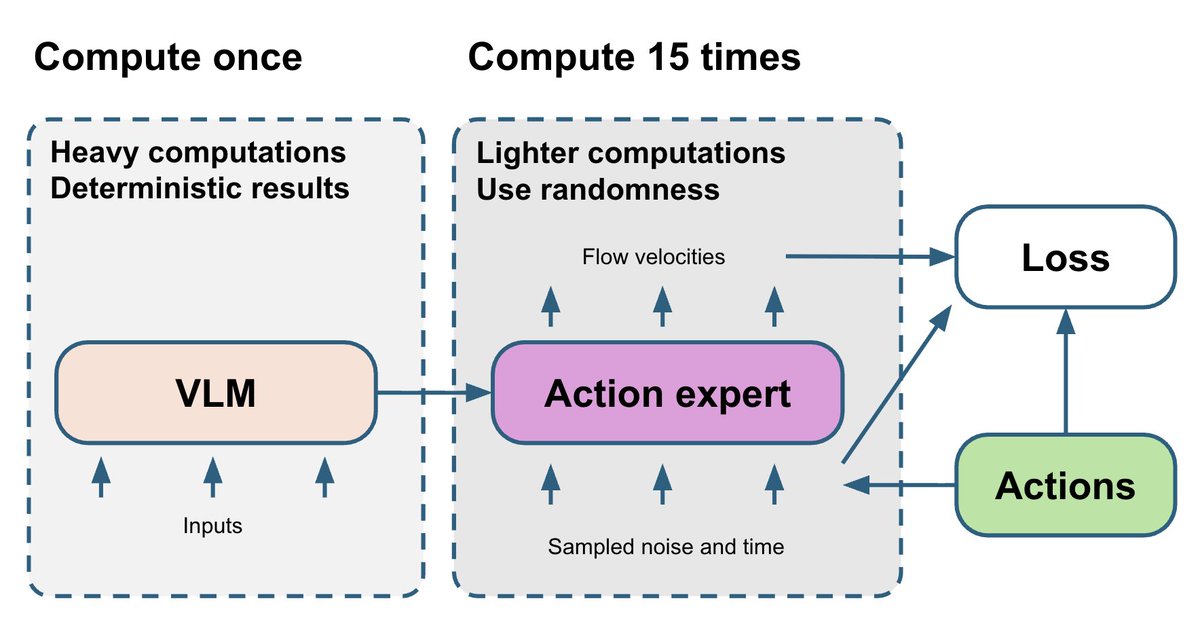
VLM部分は最も重く、決定論的です。フローマッチングアクションエキスパートは比較的小規模ですが、その学習はtとノイズという2つの確率変数に依存します。最終的に、アクションエキスパートからのノイズを含む勾配がVLM部分に戻ります。 これを改善するため、15種類の異なる(t, ノイズ)ペアを抽出し、各VLMフォワードパスごとにアクションエキスパートを15回実行します。これにより、追加の計算量はわずかですが、アクションエキスパートからの勾配はより安定します。
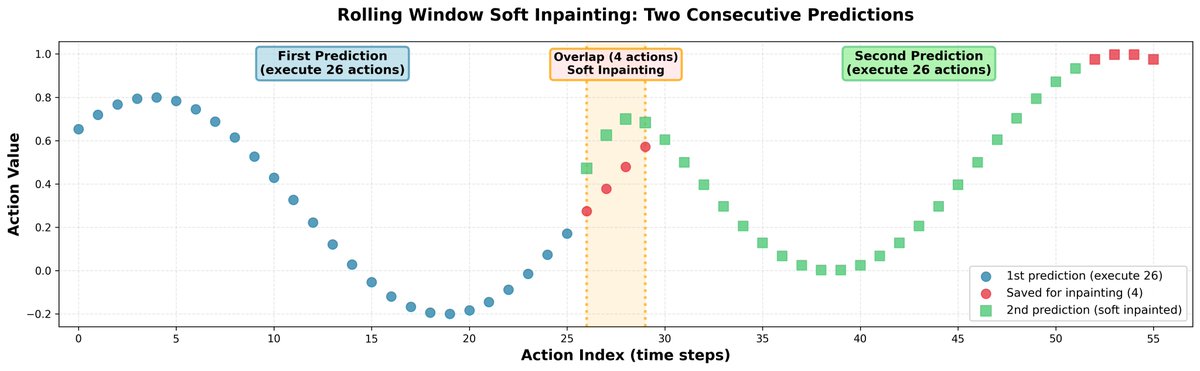
推論中に、完全に独立した行動チャンクを予測すると、軌道のジャンプや方策の不確定な動作につながる可能性があります。これに対処するため、すべてのチャンクをインペインティングによって接続しました。 - 一度に 30 個のアクションを予測しますが、実際に実行されるのは 26 個だけです。 - 残りの 4 つは、次の予測の初期入力として使用されます。 - 次の 30 を予測するときに、最初の 4 つのアクションをソフトにインペイントして、以前に保存したアクションに非常に近くなるようにします。 - アクション間の相関関係を維持するために、学習した相関行列を使用して、修正を残りの範囲に伝播します。 結果: 明確な不連続性のない滑らかなロボット軌道。
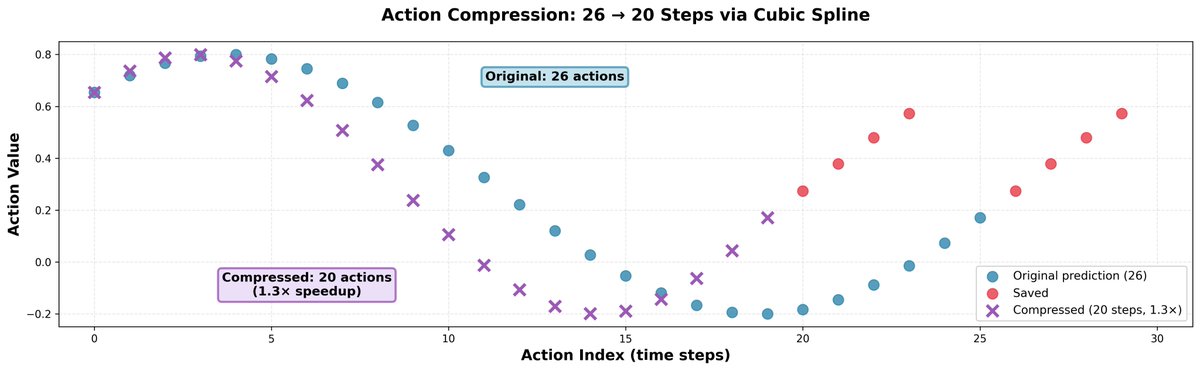
モデルの予測よりも少し速く動くと、多くの場合効果があることがわかりました。動きの精度は低下せず、ロボットが高速化し、同じ時間でより多くのことを実行できるようになります。 トリックはシンプルです。26個のアクションを3次スプライン補間で20個に圧縮し、それを20ステップで実行するだけです。これにより、1.3倍の高速化が実現します。
この問題の訓練データセットは非常にクリーンです。つまり、失敗や回復のデモンストレーションは一切ありません。これはロボット工学のポリシーにとって問題であり、単純なミスからさえ回復する方法を学習できないからです。 よくあるパターンの一つは、ロボットが物体を拾おうとして失敗し、グリッパーを閉じてしまうことです。その後、ロボットはグリッパーを開いて再度試みることができることを知らないため、そのままそこに立ち尽くし、何もしません。 このタスクとステージのどのデモンストレーションでもグリッパーが閉じられていない状況で、グリッパーが閉じられている場合にグリッパーを開くという単純なヒューリスティックを実装しました。この単純なルールにより、小規模な研究において、一部のタスクでQスコアが約2倍になりました。
しかし、時にはマルチタスクトレーニングから自然に回復行動が現れることもありました。 最初のビデオでは、1つまたは少数のタスクでトレーニングされたポリシーの典型的な失敗動作を確認できます。ポリシーがミス(例えば、写真を床に落とす)をした場合、そのような状況はトレーニングデータでは発生しなかったため、ポリシーは完全に停止し、何もしません。 2つ目のビデオでは、50個のタスク全てで学習したポリシーの回復動作をご覧いただけます。床から物を拾うという他のタスクを学習したポリシーは、この状況に一般化し、落ちた絵を掴みます。
このコンペティションでは計算リソースが不可欠でした。学習データセット全体は1000時間以上の遠隔操作データであり、8基のH200 GPUで1エポックを実行するのに約2週間かかります。ポリシーの学習には約30日間、つまり約2エポックかかりました。 これを実現するために GPU クレジットを提供してくれた @nebiusai に深く感謝いたします。
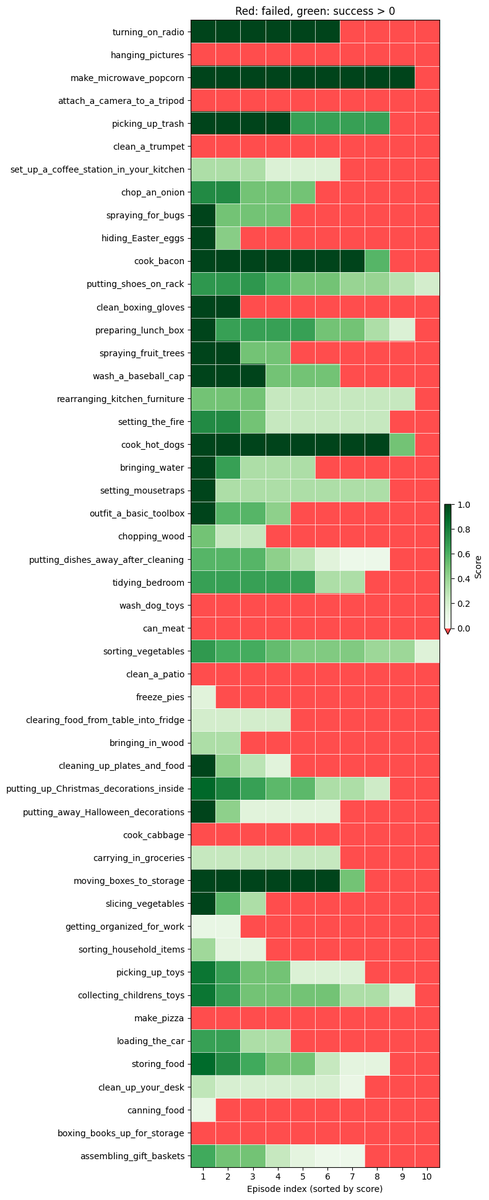
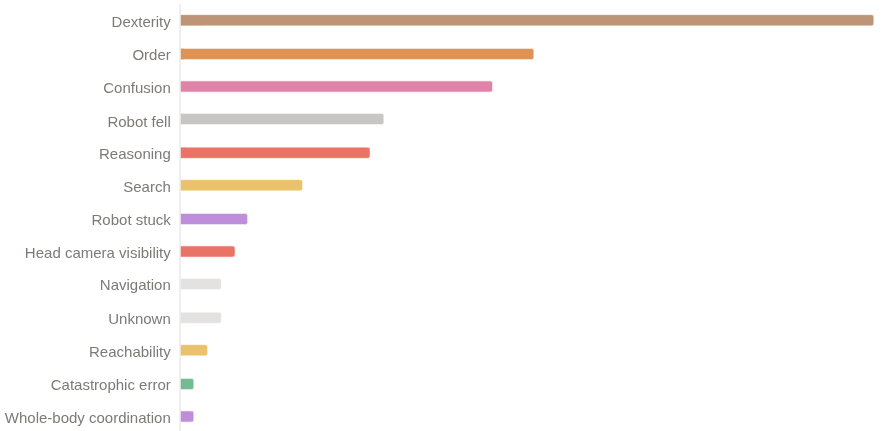
我々は1位を獲得しましたが、まだ改善の余地は大いにあると考えています。 26% の Q スコアと 11~12% のバイナリ成功率を達成しました。 この政策が依然として失敗している主な理由は次のとおりです。 - 器用さの問題(つかむ、放す) - 長いシーケンスでの進行エラー - 流通外状態に入った後に混乱する
私たちのソリューションでは、コード、モデルの重み、詳細な技術レポートなど、すべてをオープンソース化しました。 コード: https://t.co/LLSd6VtbaE 重量: https://t.co/fgithub.com/IliaLarchenko/…s://t.co/Tehuggingface.co/IliaLarchenko/…も撮影しますので、お楽しみに🎥