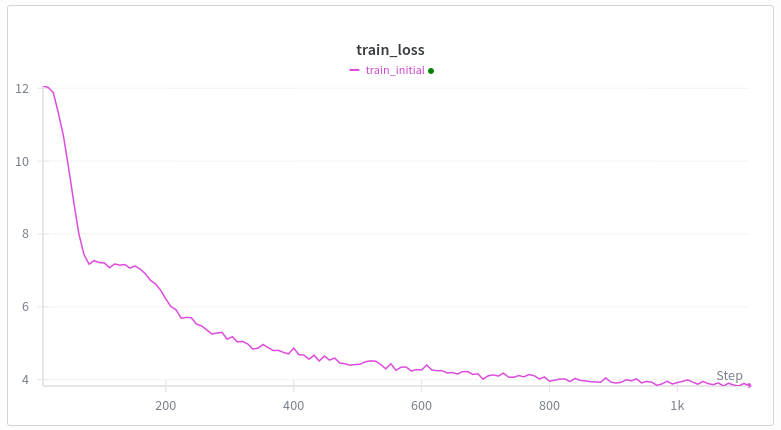
WebテキストでTransformerをゼロから学習させると、損失曲線は必ずこのようになります。最初の低下は理解できますが、2番目の低下はなぜでしょうか? ジェミニは私にナンセンスを言っています。 swiglu、rope、untied 埋め込みを除いて gpt2 と同じアーキテクチャ トレーニング: ミューオン + アダム 線形ウォームアップ(500ステップまで) 私の一番の考えは誘導ヘッド形成ミームですが、私の理解では、これは数千のトレーニング ステップや 10 億トークンなどのかなり遅い段階で発生し、バッチごとに 10 万トークンあります。 トランスフォーマーのトレーニングに携わる人なら、なぜこのようなことが起こるのか知っていますか?