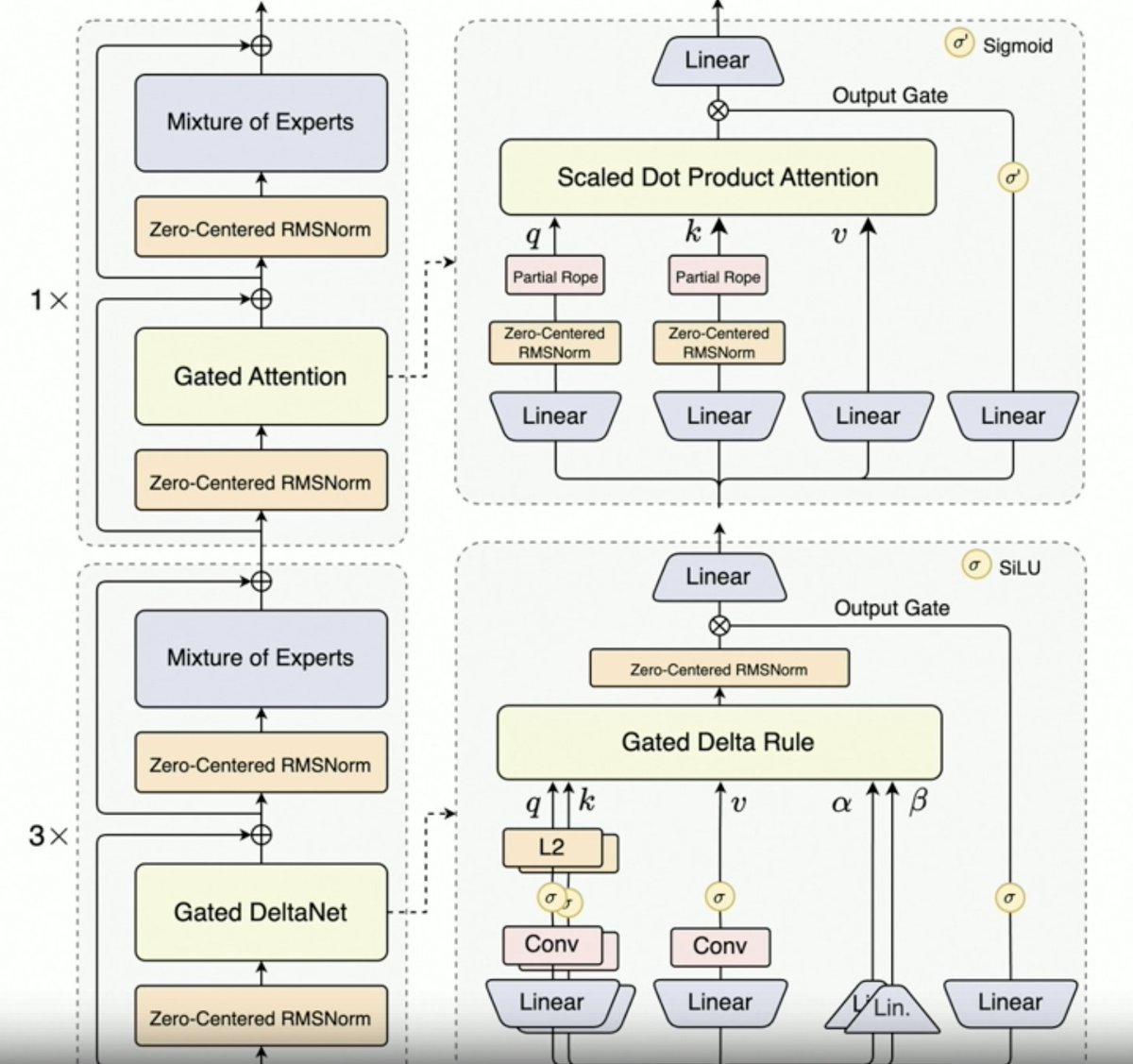
@JustinLin610 (Qwen 3 コーダー) が合成データ、RL、スケーリング、ゲートの注目度、将来の方向性について話しています。 - 思考はコーディングのユースケースをうまくサポートしません。 - コンテキスト長は256KBですが、コードはコンテキストに追加される前にフィルタリングされるため、コーディングエージェントにとっては128KBでも十分です。ただし、APIは100万トークンをサポートします。 - Qwen 2.5 Coderは、Qwen 3 Coderによる合成データの生成に役立ちました。ノイズの多いデータを取得し、それをクリーニングして書き換える作業が含まれます。 - Qwenチームによる、MegaFlowスケジューラを搭載した大規模RL環境。複数のスキャフォールド/エージェントを用いて軌道を生成しています(興味深い)。 - RL パフォーマンスが大幅に向上するので、努力する価値は十分にあります。 - Qwen3-MaxはAlibabaのスケールを飛躍的に向上させました。革新的な点はあまりありませんが、規模ははるかに大きくなっています。これはすべてスケーリングによるものです。 - Qwen3-Nextの成功を踏まえ、次世代のQwen LLMはGated Delta Attentionを搭載するでしょう。また、Sparse Attentionのトリック(DSAなど)も組み合わせられる可能性があります。 - 今後の方向性 1. 長いコンテキストのための新しいアーキテクチャ 2. 統合検索機能 3. コンピュータ利用エージェントのコーディングモデルに視覚を取り入れる 4. 長期タスク(24時間以上)のためのテクニック