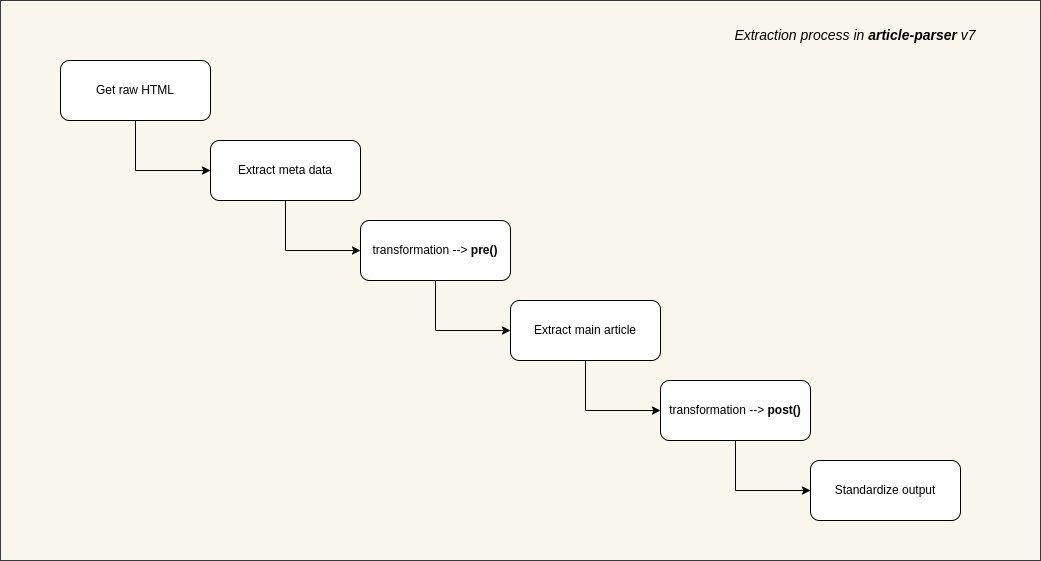
Web ページのコンテンツをスクレイピングして AI にフィードしたり、後で読むアプリケーションを作成したりする場合、最大の障害はネットワーク リクエストではなく、広告、サイドバー、ナビゲーションでいっぱいの画面からメイン テキストを正確に抽出する方法であることがよくあります。 最近、この問題を解決するために特別に設計されたオープンソースライブラリ「article-extractor」を発見しました。このライブラリは、複雑なURLからコア記事データをインテリジェントに識別し、抽出することができます。 ページの乱雑さを自動的に取り除き、構造化されたタイトル、本文、表紙画像、著者、さらには読書時間まで返します。 GitHub: https://t.co/bF0hvCYr8I カスタム変換ロジックをサポートしているため、特定のドメインの前処理または後処理ルールを記述でき、抽出精度が大幅に向上します。 Node.js、Bundle、ブラウザ環境と互換性があり、プロキシとカスタム ヘッダーの構成をサポートしているため、スクレイピング防止戦略に簡単に対応できます。 コンテンツ アグリゲータや RSS リーダーを開発している場合、または大規模なモデルをトレーニングするために Web ページ データをクリーンアップする必要がある場合は、このライブラリをツールボックスに追加する価値があります。