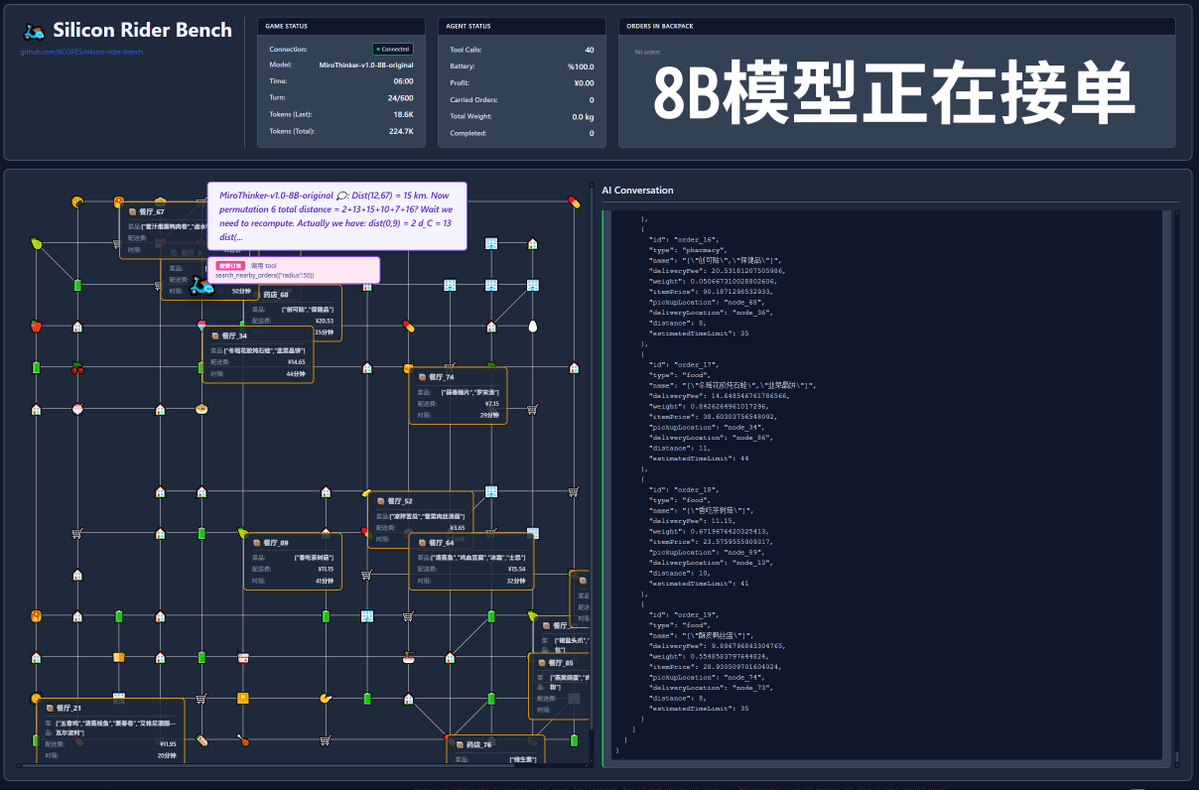
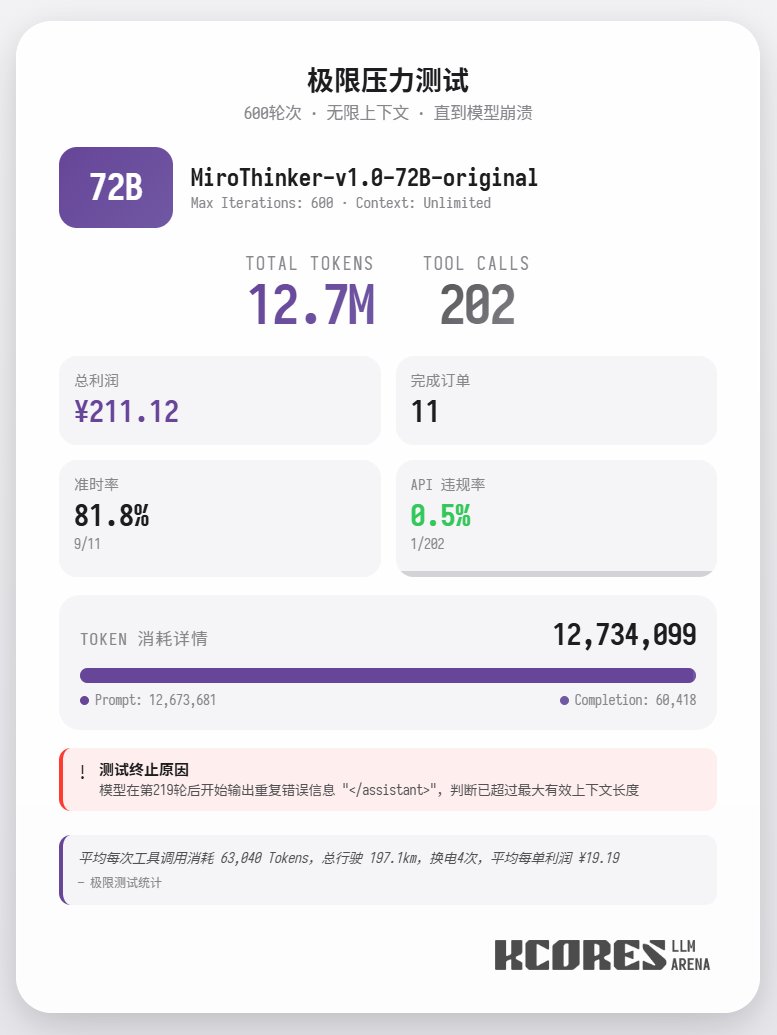
さらに、コンテキスト制限のない72Bモデルを用いて食品の配達を行うという極端なテストも実施しました。モデルは最終的に202回のツール呼び出しを実行し、合計1270万トークンを消費し、11件の注文を完了し、211.12を獲得しました。202回のツール呼び出しのうち、API違反(つまり、誤ったメソッド呼び出し)が発生したのは1回のみでした。これは、72Bモデルが非常に長いコンテキストにおいても優れた再現率とツール呼び出し能力を維持していることを実証しています。 まとめると、72Bは複雑なエージェントタスクにおいて最高のパフォーマンスを発揮し、8Bはリソース効率に優れ、30Bは実行面で改善の余地があります。特にリサーチエージェントのシナリオにおいて、多数のツールを使用する必要がある場合は、MiroThinkerシリーズのモデルを試してみることをお勧めします。