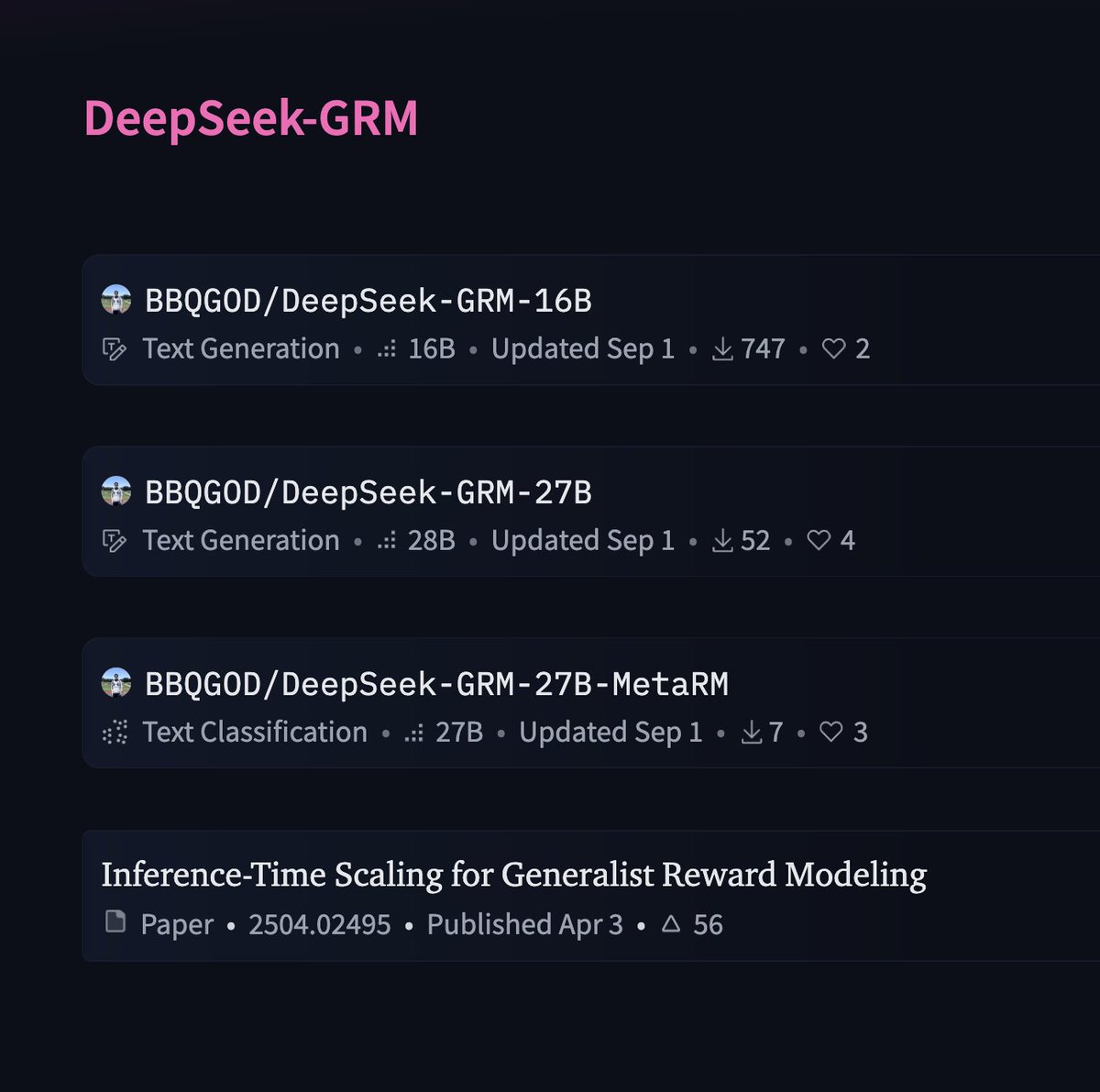
ちなみに、DeepSeek の「Self-Principled Critique Tuning (SPCT) によって強化された生成報酬モデル (GRM)」チェックポイントがいつの間にかリリースされていたことに今になって気づきました。 教師としては依然としてGemmasとV2-lite + V2.5が使用されていました。V3.2をベースにしたGRMがどれほど優れているか想像してみてください。

スレッドを読み込み中
X から元のツイートを取得し、読みやすいビューを準備しています。
通常は数秒で完了しますので、お待ちください。
1 件のツイート · 2025/12/03 6:10
ちなみに、DeepSeek の「Self-Principled Critique Tuning (SPCT) によって強化された生成報酬モデル (GRM)」チェックポイントがいつの間にかリリースされていたことに今になって気づきました。 教師としては依然としてGemmasとV2-lite + V2.5が使用されていました。V3.2をベースにしたGRMがどれほど優れているか想像してみてください。