翻訳プロンプトをまとめてくださった@LipuAIXさん、ありがとうございます。AIを使って記事を翻訳した私の経験をいくつか共有したいと思います。プロンプトは少し複雑すぎると感じますが、根底にある考え方はしっかりしており、以前にも同様の見解を共有したことがあります。 1. 最高の翻訳は書き直しです。 2. 良い翻訳にはいくつかのステップが必要です。 ただし、シナリオにもよります。通常の翻訳シナリオであれば、一度の書き換えで十分です。現在の大規模言語モデル、特にGemini 3 Proの性能を考慮すれば、一度の書き換えで既にかなり高い品質が得られます。 本当にプロフェッショナルな翻訳をしたいのであれば、最初の書き直しの後にAIに校正させて磨きをかけることが必要です。 ただし、内容が非常に短い場合を除き、校正と磨き上げを同じプロンプトで行うべきではありません。 主な理由は、昨日述べたとおりです。大規模なモデルでは入力が非常に長くなる可能性がありますが、出力が長すぎると、コスト削減と深刻な錯覚が生じます。 2,000 語の記事を翻訳していて、プロンプトに従って 3 回読み直す必要があり、出力は 5,000 ~ 6,000 語になり、出力の品質は最後のほうで低下すると想像してください。 したがって、翻訳、校正、磨き上げは個別に行うのが最適です。 まず、翻訳についてお話しましょう。翻訳のプロンプトは元のツイートほど複雑である必要はありません。単に「書き直す」だけで十分です。重要なのは説明です。 - 記事スタイル - よく使われる翻訳語彙比較表 - ターゲットオーディエンス(オプション) 校正には原文と翻訳文の両方が必要であり、漏れや誤りがないか確認します。高い翻訳精度が求められない場合は、このステップを省略できます。 ポリッシングには元の英語テキストは不要で、翻訳のみが必要です。この場合、モデルは翻訳された文が流暢で中国語の表現習慣に沿っているかどうかをチェックするだけです。元の英語テキストはもはや必要ありません。 さらに、記事が長すぎる場合は、セクションに分割する必要があります。自然な章と段落に従って記事をセクションに分割するのが最善であり、通常は1レベルの段落で十分です。 各部分を前の部分とどのように接続するかについては、前の部分の原文と翻訳を文脈に追加して、次の部分の翻訳で前の部分の内容とスタイルを参照できるようにするのが簡単で効果的な方法です。 履歴ブロックをいくつ保持するかは、モデルとブロックサイズによって異なります。通常は、前のブロックの原文と翻訳があれば十分です。多すぎると不要になり、履歴結果を完全に省略しても問題ありません。 このプロセスは、APIを使ってプログラムを作成することも、手動でモデルを作成することもでき、例えば私はGeminiを使っています。Geminiでは、異なるプロンプトがそれぞれ異なるGemに作成され、必要なときにコンテンツをGemに貼り付けるだけです。
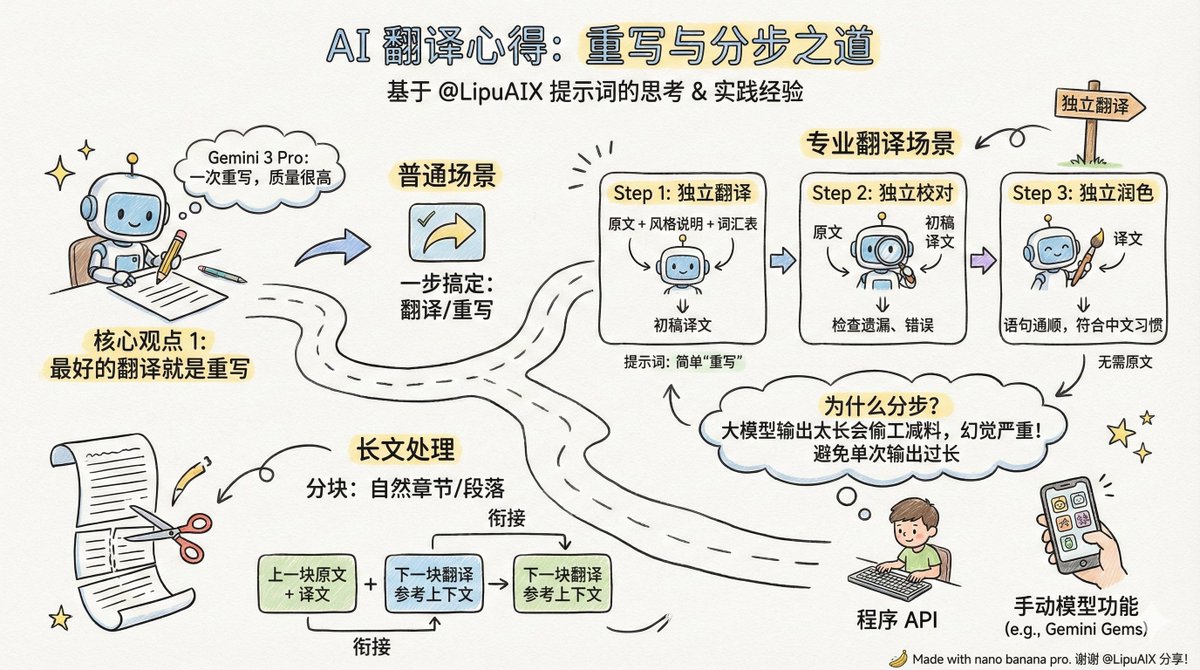
良い翻訳とは書き直しです。
翻訳プロンプト: