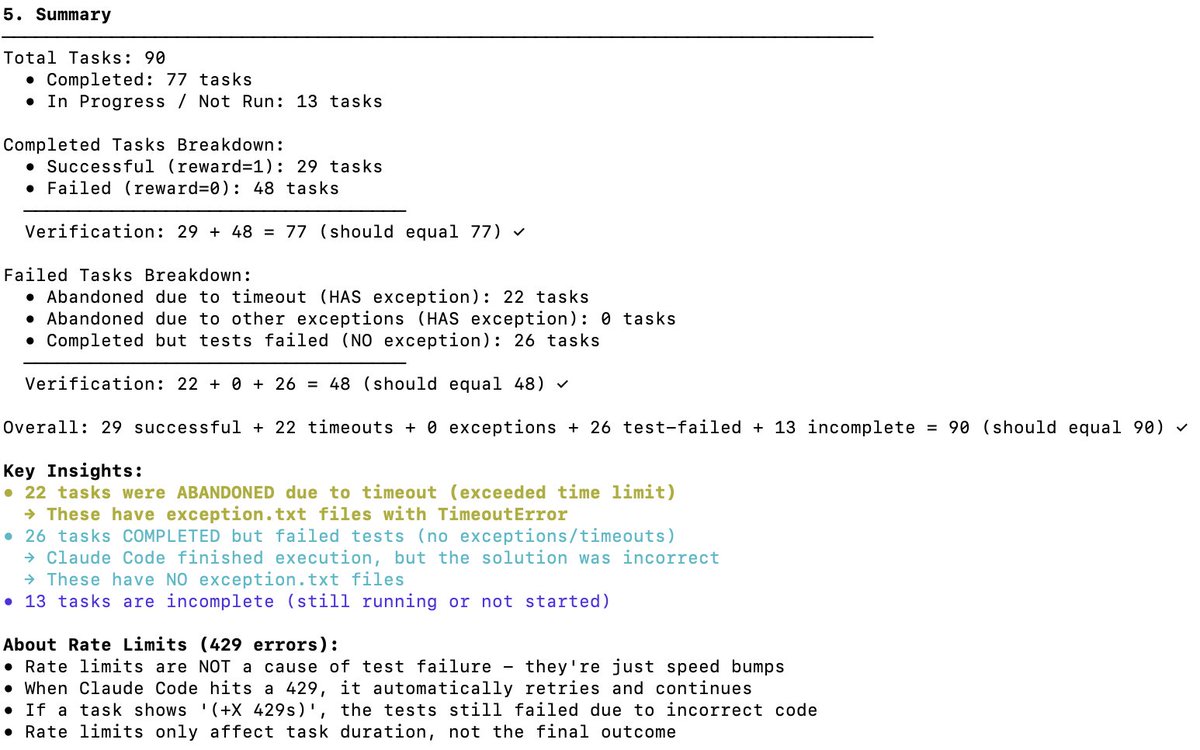
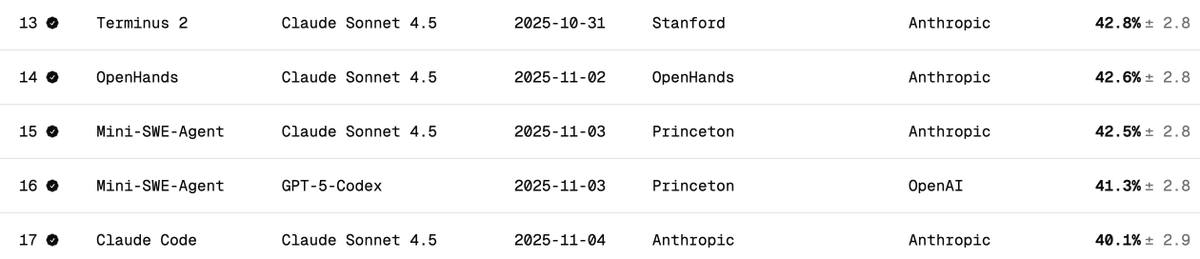
DeepSeek V3.2のTerminal Bench 2パフォーマンスを独立検証 ターミナルベンチは、モデルがターミナルシナリオ(Claude Code、Codex CLI、Gemini CLIなど)においてエージェントをどのようにサポート/実行するかを測定します。私見では、これはAIソフトウェア開発において最も重要なLLMベンチマークです。AIがCLIを操作してソフトウェアのダウンロード、コードの開発、テストなどを行います。 公式スコアは何ですか? DeepSeek v3.2の公式スコアは、以下の表の通り、思考時で46.4、非思考時で37.1です。論文で報告されているClaude Codeハーネスが使用されました。 このベンチマークで Claude Code + Sonnet 4.5 のパフォーマンスはどの程度でしょうか? 以下は、Claude Sonnet 4.5 の端末ベンチスコアです。Claude Code ハーネスでは約40% です。 Claude Code Harness を使用した DeepSeek V3.2 でどのようなスコアを獲得しましたか? DeepSeek-Reasoner(Thinking)でテストしました。約90回のテストのうち、Harbor(オーケストレーター)が動作を停止するまでに77回実行されました。77回という数字は、これらが偏りのないサンプルであると仮定すると、感覚をつかむのに適切な数字です。 - 29 - 成功 - 48 - 失敗 (22 回のタイムアウト + 26 回の誤ったコード生成) これにより、スコアは 38% になります (非常に印象的で、すでに Claude Code + Sonnet 4.5 の 40% に近づいています)。 しかし、確かなことは、DeepSeek v3.2モデルにもっと多くの時間を与えれば、タイムアウトしたタスクをより多く完了できるようになり、38%をはるかに上回る、おそらく50%に達するだろうということです。しかし、そうなると、同一条件での比較は不可能になります(テスト作成者はタイムアウト設定を変更しないことを推奨しています)。 他のOSSモデルとの比較: 以下はTerminus 2ハーネスを使用しています 1位 キミK2 思考 - 35.7% 2. ミニマックスM2 - 30% 3. Qwen 3 コーダー 480B - 23.9% 結論: パフォーマンスは OSS モデルとしては SOTA であり、Claude の 4.5 にほぼ匹敵するのは驚くべきことですが、私のスコアは DeepSeek チームのスコア 46.4 よりも低くなりました (最後の 13 回のテストは実行されませんでした)。 Claudeコードの動作が変更されたのではないかと考えています。Claudeコードは特定の方法(例えばなど)でモデルに通知しますが、DeepSeek v3.2ではそれが馴染みがなく、うまく処理できない可能性があります。 DeepSeekにAnthropic APIエンドポイントがあることを知って本当に良かったです。Claude Codeを使ったテストがスムーズにできました。あとはsettings.jsonをDockerに置くだけです。 DeepSeek (@deepseek_ai ) は、どのようにしてこれらのスコアを達成したかを透明性を持って共有する必要があります。 コストとキャッシュヒット: これが一番すごいところです。77回のテストを実行するのにたった6ドルしかかかりませんでした(Harborは最後の13回を何らかの理由で諦めました)。1億2000万トークン近く処理されましたが、ほとんどのトークンは入力データであり、その後キャッシュヒットしたため(DeepSeekはディスクベースのキャッシュを自動的に実装しています)、コストは非常に低く抑えられました。 ターミナルベンチチームへのリクエスト: すべてのタスクを完了する前に終了したジョブを簡単に再開できるようにしてください。この素晴らしいベンチマークに感謝します。 @terminalbench @teortaxesTex @Mike_A_Merrill @alexgshaw @deepseek_ai