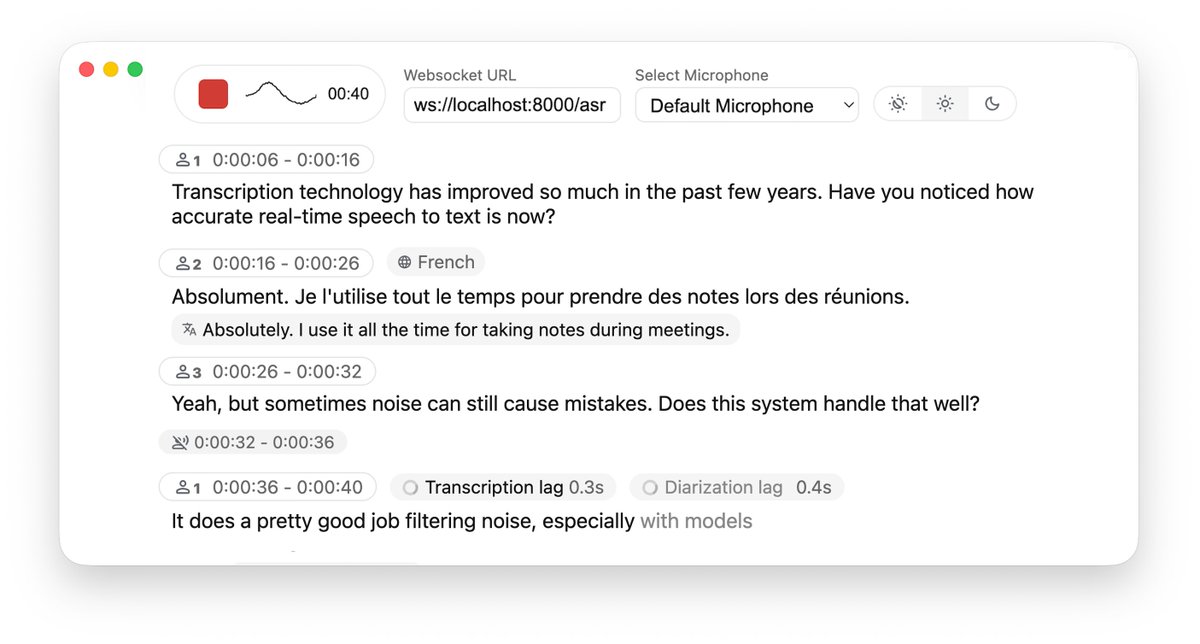
プロジェクトでリアルタイムの音声テキスト変換を実現するには、通常、クラウド API を選択する必要がありますが、これは高価なだけでなく、データのプライバシーに関する懸念も生じます。 Whisper のローカル展開は無料ですが、ストリーミング オーディオを処理する際の遅延と文章分割エクスペリエンスは満足のいくものではないことがよくあります。 私は GitHub で WhisperLiveKit オープンソース プロジェクトを見つけました。これは、ストリーミングの遅延の問題に特化して最適化された、完全なローカル リアルタイム音声認識および翻訳ソリューションを提供します。 高精度のリアルタイム文字起こしをサポートするだけでなく、話者認識(ダイアライゼーション)と音声アクティビティ検出(VAD)も内蔵しており、誰が話しているのか、いつ一時停止したのかを正確に区別できます。 GitHub: https://t.co/SVCcyqdqhG バックエンドは非常に柔軟で、Faster Whisper または Apple Silicon 向けに最適化された mlx-whisper エンジンとの統合をサポートし、さらに NLLW モデルを統合して 200 言語のリアルタイム翻訳を実現します。 このプロジェクトには、Dockerデプロイをサポートする、すぐに使えるPythonのサーバーサイドおよびWebフロントエンドのサンプルが含まれています。プライバシー保護と低遅延を実現する会議録画や同時通訳システムを構築するための、非常に堅牢なインフラストラクチャを提供します。