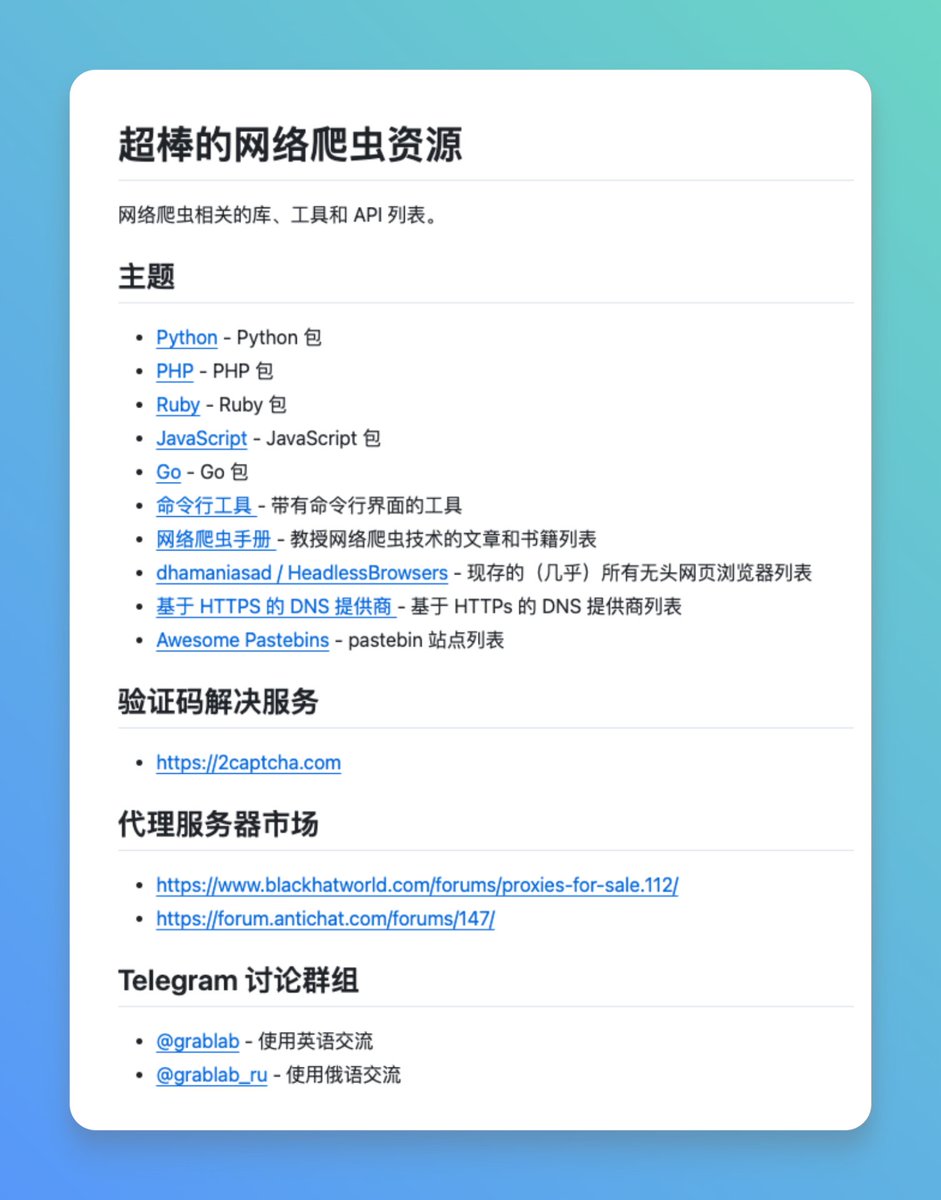
Web クローラーを開発する場合、最も頭を悩ませるのはコードを書くことではなく、リソースが非常に分散しているため、さまざまな言語やシナリオに適したライブラリやツールを見つけることです。 私は、さまざまな Web スクレイピングおよびデータ処理ツールを体系的に整理したオープンソース リソース コレクションである Awesome Web Scraping に偶然出会いました。 プログラミング言語別に構成されており、Python、PHP、Ruby、JavaScript、Goなどの主流言語のWebスクレイピングライブラリ、コマンドラインツール、学習教材などを網羅しています。 GitHub: https://t.co/MP1R3oMRNH ツールライブラリ自体に加えて、Web スクレイピングのチュートリアルやヘッドレス ブラウザのリストなどの実用的なリソースも含まれています。 このプロジェクトは、いくつかのよく知られた素晴らしいリストのデータに基づいており、リソースは比較的包括的であるため、将来の参照用に保存する価値があります。