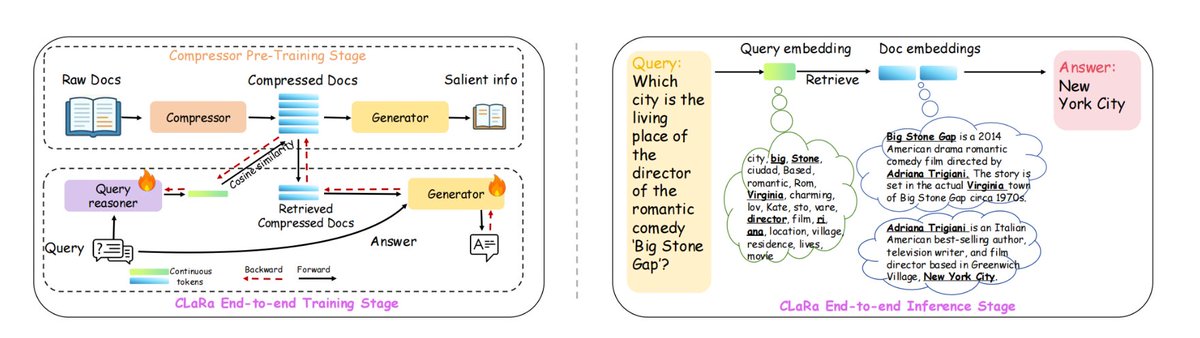
Apple は、長いコンテキストの処理の非効率性と、検索と生成の最適化プロセスの分離を解決する、ml-clara と呼ばれる新しい RAG フレームワークを開発しました。 基本的な考え方は、テキスト全体を大規模なモデルに取り込むことを避け、代わりに「検索」プロセスと「生成」プロセスを同じ微分可能な連続ベクトル空間に圧縮し、統一されたトレーニングと単一段階の推論を可能にすることです。 これにより、1) コンテキストの長さの増加による計算コストの爆発的な増加、2) 検索とジェネレータの独立したトレーニングによって生じる最適化目標の不一致、3) 勾配切断の問題などの問題が解消されます。 NQ、HotpotQA、MuSiQue、2Wiki では、4×/16×/32× の異なる圧縮率でトップの座を維持し、32× 圧縮でも、圧縮されていない純粋な検索ベースラインよりも優れていました。 正確な回答を生成するために必要な重要な情報を保持しながら、コンテキストの長さを最大 32 ~ 64 倍まで圧縮できます。 具体的には、1. まず、事前トレーニングを圧縮し、QA/繰り返しのセマンティクスを維持しながらドキュメントを 32 ~ 256 次元のベクトルに圧縮します。 2. 次に、圧縮されたベクトルを下流の質問応答タスクに適合させるために命令を微調整します。 3. 検索とジェネレータの両方を最適化するための、エンドツーエンドの共同トレーニングをさらに行います。 #RAG #mlclara
ギットハブ: github.com/apple/ml-clara