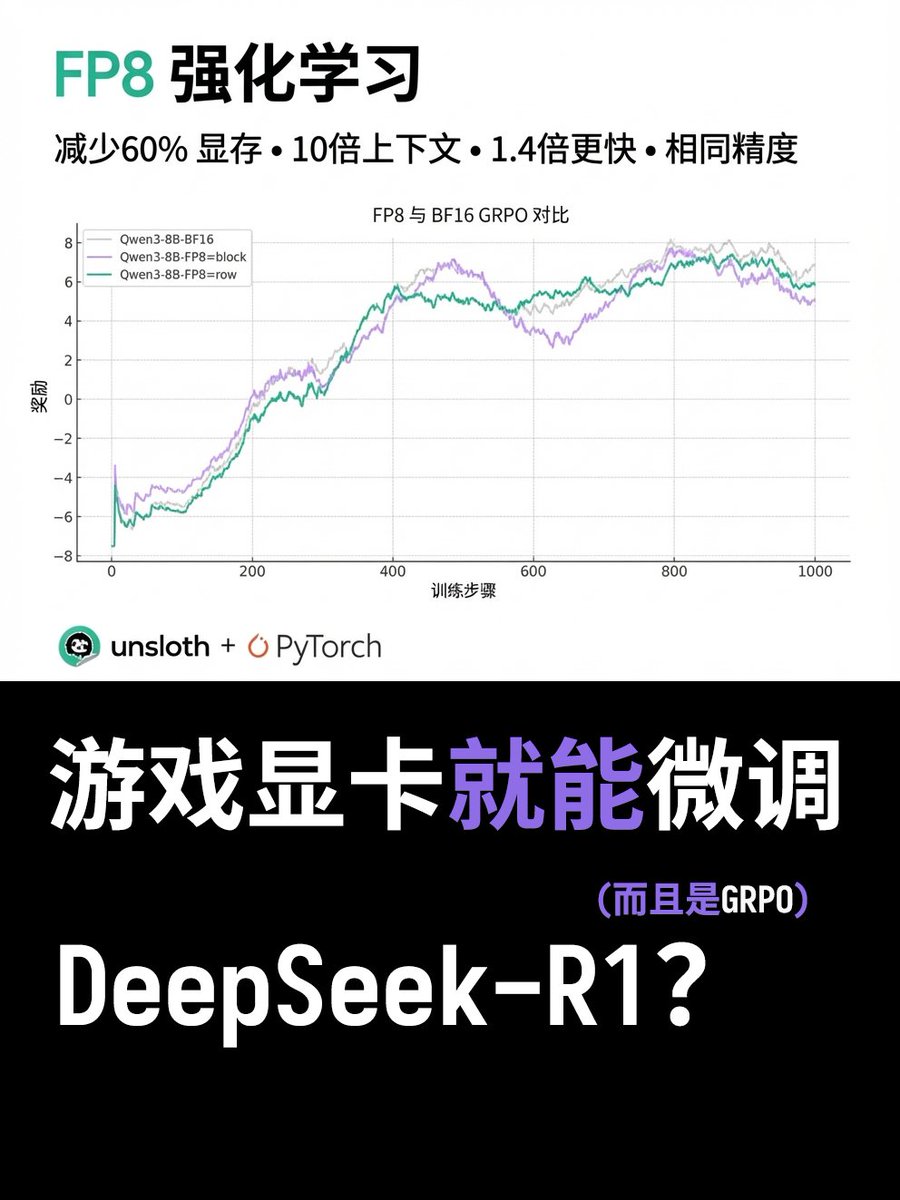
ゲーム カードでも FP8 GRPO を使用できるようになりましたか? Unsloth は、最小限の VRAM で DeepSeek-R1 の FP8 GRPO を微調整する方法を示す新しいチュートリアルをリリースしました。 彼らはPyTorchと連携し、FP8 RL推論速度を1.4倍向上させました。さらに、GPUメモリを60%削減し、コンテキスト長を12倍にすることでプロセスを微調整しました。このプロセスは現在、Unslothフレームワークで利用可能です。 この強化学習アプローチは、FP8精度の広範な採用を直接的に可能にし、FP8 GRPOをコンシューマーグレードのGPU(RTX 40、50など)に実装することを可能にします。テストデータによると、Qwen3-1.7BでのFP8 GRPOの実行に必要なVRAMはわずか5GBです。 チュートリアルアドレス: