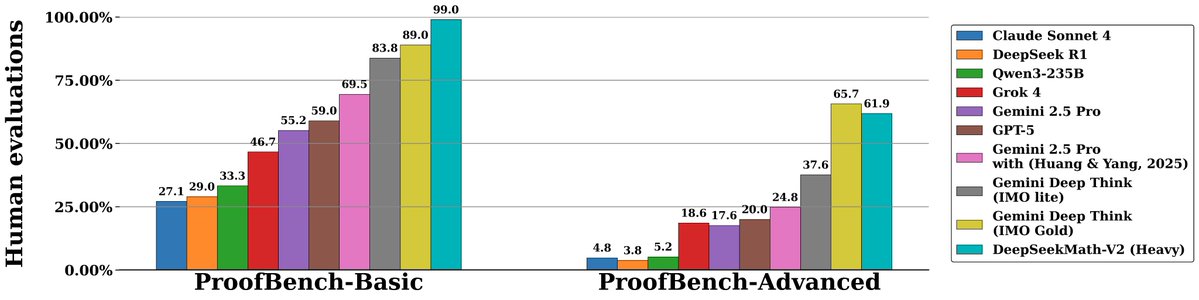
すごい!DeepSeek は、IMO の金メダル レベルに達する最新モデル DeepSeek-Math-V2 をリリースしました。 DeepSeek-V3.2-Exp-Base、685B をベースにしており、数学的推論と定理証明に重点を置いています。 Math-V2 は単に答えを計算するだけではなく、完全な証明を生成し、さらに自身の証明の妥当性をチェックすることもできます。 IMO 2025およびCMO 2024では金メダルレベルの成績を達成し、Putnam 2024では118/120というほぼ完璧なスコアを達成しました。 具体的には、まず、証明プロセスが厳密であるかどうかを判断するための正確で信頼できる検証者がトレーニングされます。 次に、このバリデーターを報酬モデルとして使用して、証明ジェネレーターは、提出前に証明内の問題を積極的に特定して修正するようにトレーニングされます。 ジェネレータが強力になるにつれて、検証の計算負荷は継続的に増加し、検証が難しい証明には自動的にラベルが付けられ、検証者のトレーニングにフィードバックされ、改善のための「生成-検証」サイクルが形成されます。 DeepSeekMath-V2 は、単に答えを提供するだけでなく、AI 数学に本質的に革命をもたらしました。今では証明を書くことができ、それだけでなく、エラーを自己チェックすることもでき、反復ごとにますます厳密になっています。 #ディープシーク数学V2
モデルhuggingface.co/deepseek-ai/De…sI 論github.com/deepseek-ai/De…A2e
