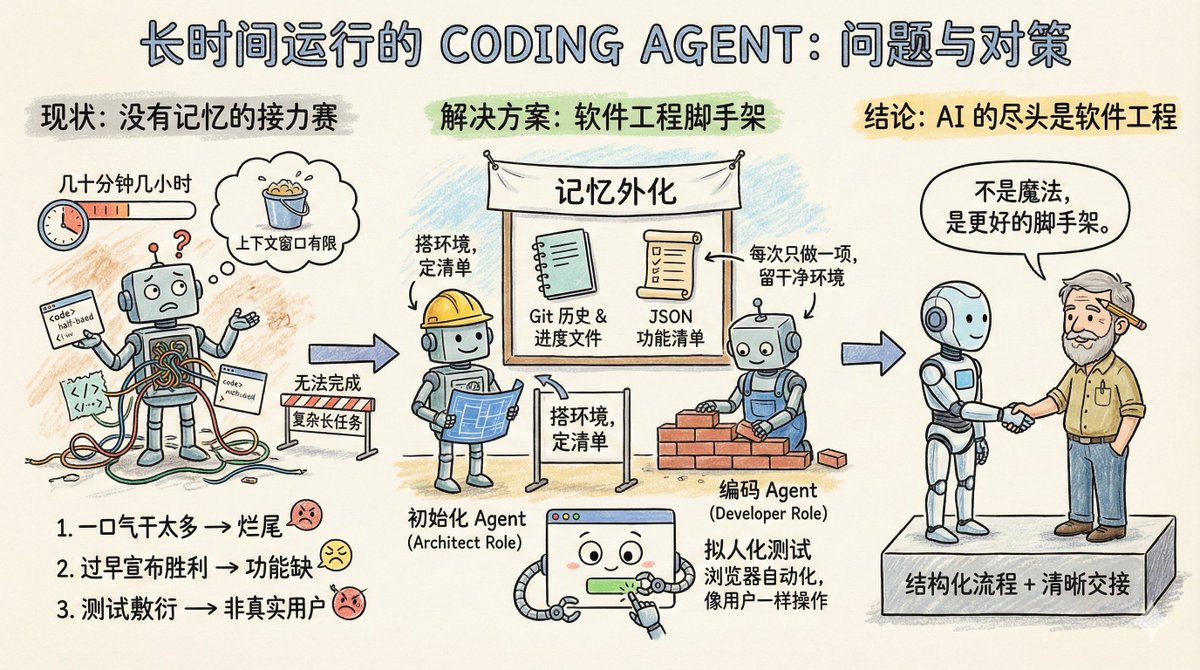
大規模なプロジェクトに取り組んでいるソフトウェアチームを想像してみてください。しかし、奇妙なルールがあります。各エンジニアは数十分、せいぜい数時間しか作業できず、その後は新しいエンジニアと交代しなければなりません。そのため、このチームは単純なプロジェクトタスクには適していますが、claude.aiファイルのクローン作成など、実行時間の長い複雑なプロジェクトには到底対応できません。 これがコーディングエージェントの現状です。メモリ不足とコンテキストウィンドウの長さ制限があり、長時間実行されるタスクの実行には適していません。 Anthropic のブログ記事「長時間実行されるエージェントのための効果的なハーネス」では、エージェントが複数のコンテキスト ウィンドウにわたってタスクを継続的に実行できるようにする方法について具体的に説明しています。 まず、エージェントが長時間のタスクで遭遇する主な問題を見てみましょう。 主なタイプは3つあります。 一つ目のタイプは、一度に多くのことをしようとするタイプです。例えば、claude.aiのようなウェブサイトのクローンをエージェントに依頼すると、エージェントはアプリケーション全体を一度に完成させようとします。その結果、コンテキストは十分に活用されておらず、機能の半分しか記述されておらず、コードは完全に混乱した状態になります。次のセッションが始まると、エージェントは未完成の製品をぼんやりと見つめることしかできず、前のステップで何が行われたかを推測することに多くの時間を費やします。 2つ目のタイプは、早まった勝利宣言と呼ばれます。プロジェクトの一部が完了し、後続の担当者が環境を確認し、ほぼ完了したと判断して、その日の作業を終えます。不足している多くの機能が無視されます。 3つ目のタイプは、おざなりなテストと呼ばれます。エージェントはコードを修正し、いくつかのユニットテストを実行したり、インターフェースをcurlで実行したりするだけで、実際のユーザーのようにエンドツーエンドのプロセスを実行することなく、すべてが正常であると判断します。 これら 3 つの失敗モードに共通するのは、エージェントが全体的な目標を認識しておらず、どこで停止するか、次のエージェントに何を残すかがわからないことです。 では、Anthropic の解決策は何でしょうか? 本質的に、これらはソフトウェア エンジニアリングからすぐに利用できるソリューションです。人間のチームに類似した共同作業のメカニズムを導入し、複雑なタスクをより小さく追跡可能で検証可能なタスクに分割し、明確な引き継ぎメカニズムを確立し、タスクの結果を厳密に検証します。 初期化エージェントはプロジェクト開始時に一度だけ登場します。その役割は、プロジェクトの実行環境をセットアップすることです。これはいわば建築家のようなもので、開発サーバーの起動を容易にするための init.sh スクリプトの作成、進捗状況を記録する claude-progress.txt ファイルの作成、最初の git コミットの実行、そして最も重要な機能リストの生成などを行います。 この機能リストはどの程度詳細なのでしょうか?claude.aiのクローン作成の場合、ユーザーが新しい会話を開始したり、質問を入力したり、Enterキーを押したり、AIの応答を確認したりといった、200を超える具体的な機能がリストされています。各初期状態は失敗としてマークされており、エージェントはそれぞれを個別に検証してから成功に変更する必要があります。 さらに、ここで注意すべき点があります。このリストはMarkdownではなく、JSON配列として記述されています。これは、Anthropicの実験で、Markdownと比較して、JSONを処理する際にモデルが恣意的に改ざんされたり上書きされたりする可能性が低いことがわかったためです。 もう1つはコーディングエージェントです。プロジェクトが始動した後、作業の責任を負います。その基本的な行動指針は2つだけです。一度に1つの機能だけを実行すること、そして完了後にクリーンな環境を残すことです。 クリーンな環境とはどのようなものでしょうか?メインブランチにコードをコミットする際の基準を想像してみてください。深刻なバグがなく、きちんと整理され、適切に文書化されたコードであれば、次の人が混乱を解消することなく、すぐに新しい機能の開発に取り掛かることができます。 各操作の前に、いくつかの処理が行われます。 – `pwd` を実行して、現在どのディレクトリにいるかを確認します。 – Git ログと進行状況ファイルを読んで、前回の実行で何が行われたかを理解します。 – 機能リストを確認し、未完了の機能の中で最も優先度の高いものを選択します。 – 基本的なテストを実行して、アプリがまだ使用可能であることを確認します。 次に、1 つの機能に焦点を当て、それが完了したら次の操作を行います。 - Gitコミットメッセージをクリアする – claude-progress.txt を更新 – 機能リスト内のステータス フィールドのみを変更し、要件自体を削除または変更しないでください。 この設計の独創性は、「記憶」をファイルとGitの履歴に外部化していることにあります。エージェントの各ラウンドは、コンテキストウィンドウ内の断片的な情報に頼るのではなく、信頼できる人間のエンジニアの日常業務を模倣します。つまり、まず進捗状況を同期し、環境が正しく動作していることを確認し、それから作業を開始します。 テストプロセスの改善については別途議論する価値があります。 エージェントは、ユニットテストの実行やAPIの呼び出しといったコードレベルの検証のみを使用していました。問題は、多くのバグがユーザーが実際にページを操作したときに初めて表面化するということです。 解決策は、エージェントにPuppeteer MCPなどのブラウザ自動化ツールを装備することです。エージェントはブラウザを開き、ボタンをクリックし、フォームに入力し、ページのレンダリング結果を確認するなど、まるで人間のように操作できるようになります。Anthropicは、claude.aiのクローンをテスト中にエージェントが撮影したスクリーンショットを示すアニメーションGIFを投稿し、エージェントが実際にユーザーのように動作していることを実証しました。 この技術は機能検証の精度を大幅に向上させます。もちろん、限界もあります。例えば、Puppeteerはネイティブブラウザのアラートポップアップをキャプチャできず、ポップアップに依存する機能はバグが発生しやすくなります。 この計画にはまだいくつかの疑問が残っています。 例えば、すべてを処理できる汎用エージェントを用意する方が良いのか、それとも専門分野に特化したエージェントを用意する方が良いのでしょうか?テスト専用のテストエージェントとクリーンアップ専用のコードクリーンアップエージェントを用意する方が効果的かもしれません。 例えば、この経験はフルスタックWeb開発に最適化されています。科学研究や金融モデリングといった長期サイクルのタスクに転用できるでしょうか?おそらく可能でしょうが、実験を通して検証する必要があります。 Xiangma@xicilion さんはこう言いました。 AIの最後には、依然としてソフトウェア エンジニアリングが残ります。 AIエージェントは魔法ではありません。人間のソフトウェアエンジニアリングの経験から学び、複雑なタスクを単純なものに分解し、構造化された作業環境と明確な引き継ぎメカニズムを備えている必要があります。 なぜ人間のエンジニアはチームやタイムゾーンを越えて連携できるのでしょうか?それは、Git、ドキュメント作成、コードレビュー、そしてテスト環境があるからです。AIエージェントが長期間自律的に動作するには、これらのツールも導入する必要があります。 Anthropicのアプローチは、ソフトウェアエンジニアリングにおけるベストプラクティスを、エージェントが理解できるキューワードとツールチェーンに変換するだけです。モデルをよりスマートにするのではなく、より優れた基盤を提供します。 Anthropicのアプローチは学ぶ価値があります。Claude、GPT、あるいは他のモデルを使う場合でも、複数ラウンドにわたる長時間のタスクを設計する際には、エージェントを次のラウンドに素早く移行させる方法と、車輪の再発明やコードの混乱を避ける方法を明確に理解する必要があります。単一ラウンドのタスクであっても、エージェントには記憶がないため、外部ファイルを用いて以前の行動を「思い出す」必要があります。 モデルの現在の機能だけでも、Coding Agent はすでに多くのことを実現できます。重要なのは、ソフトウェアエンジニアリングと同様にタスクを細分化し、ワークフローを設計できるかどうかです。 原文: 長時間稼働エージェントのための効果的なハーネス https://t.co/tERUGrV9wC 翻訳する:
この記事で言及されているタスク リストはグローバル コンテキストの一種ですが、すべてのグローバル コンテキストと同様に、長x.com/stevenlu1729/s…行するためのコンテキスト ウィンドウが足りなくなってしまいます。