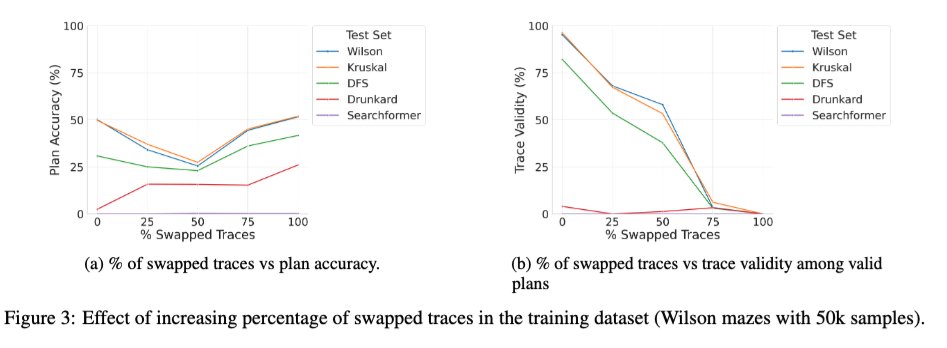
LRM における中間トークンの役割に関する体系的な研究である「Beyond Semantics」論文の拡張版を arXiv にアップロードしました。興味を持っていただける方もいらっしゃるかもしれません。🧵 1/ 興味深い新しい研究の一つは、正しいトレースと間違ったトレースを混ぜてベーストランスフォーマーをトレーニングした場合の効果です。トレーニング中に間違った(入れ替わった)トレースの割合が0から100に変化すると、推論時のモデルのトレース妥当性は予想通り単調に低下します(右下のグラフ)。しかし、解の精度はU字曲線を描きます(左下のグラフ)。これは、トレーニング中に使用されるトレースの正確性ではなく、「一貫性」が重要であることを示唆しています。