OlmoRLのインフラストラクチャはOlmo 2の4倍高速で、実験の実行コストを大幅に削減しました。変更点は以下のとおりです。 1. 連続バッチ処理 2. 機内アップデート 3. アクティブサンプリング 4. マルチスレッドコードに多くの改良を加えました
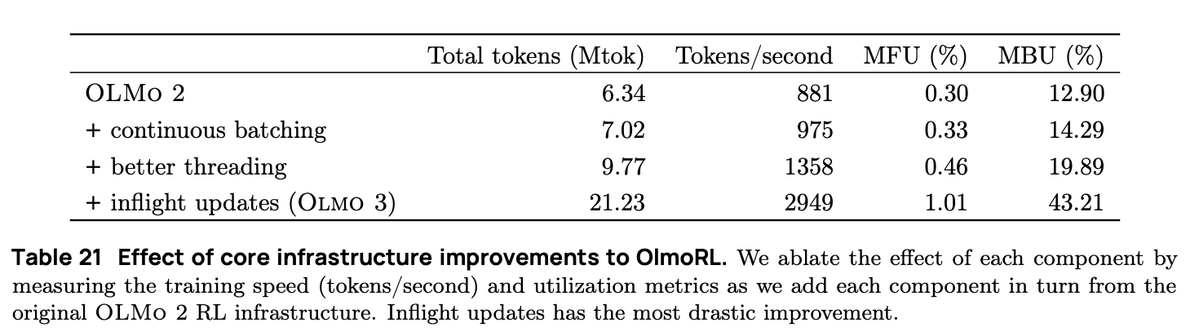
継続的なバッチ処理では、完全に非同期な生成設定に移行します。この設定では、プロンプト用と生成結果用の 2 つのキューがあります。 私たちのアクターは完全に非同期的に動作し、完了すると継続的に新しいプロンプトを生成して生成します。
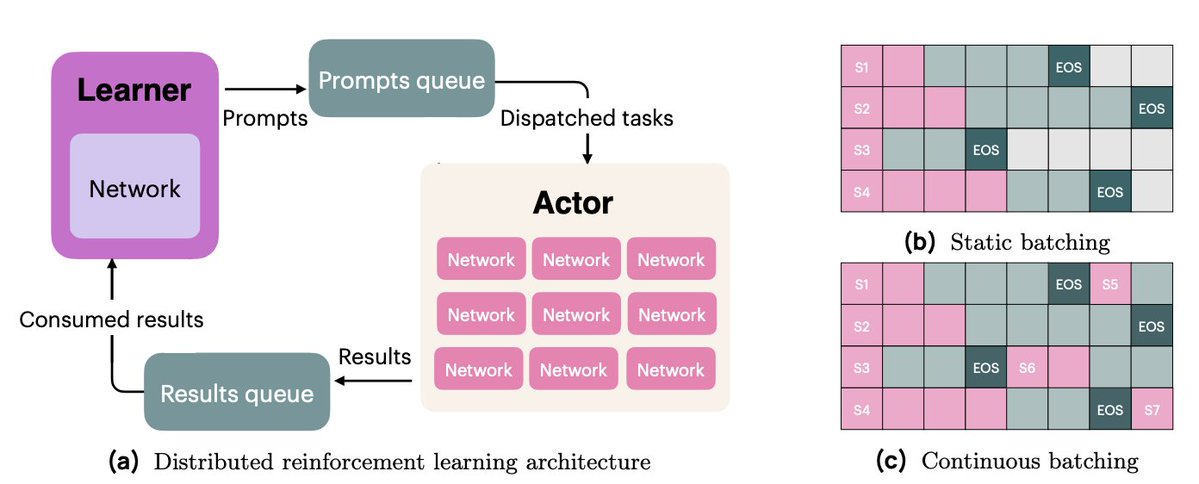
インフライトアップデート(PipelineRL、@alexpiche_、@DBahdanau ら提供)を利用すると、生成の途中でアクターを更新できます。重みを更新するために生成キューを空にする必要がないため(これは静的バッチ処理と同じ問題です)、システムは大幅に高速化されます。

アクティブ サンプリング (@mnoukhov からの新しい貢献) は、報酬の分散が 0 のグループ (つまり、利点が 0、勾配が 0) がフィルターで除外され、トレーニング ステップごとにバッチ サイズが変化するという、GRPO で発生する厄介な問題を解決します。
以前の論文では、フィルタリング後に常に十分な数のグループが得られることを期待して、必要なグループの3倍をサンプリングすることでバッチサイズの変動問題を解決していました。しかし、Michaelはコードを変更し、非定数報酬グループのバッチが一杯になるまで待ってからトレーニングを行うようにしました。
俳優と学習者の同期を保つには、多くの難しい作業が必要でした。
最後に、同期を減らし、アクターが非同期で動作できるようにするために、コードベースのリファクタリングに多大な時間を費やしました。これには、Pythonのスレッドとasyncio APIに関する広範なエンジニアリング作業が必要でした。
私たちの RL インフラ作業は、私自身、@hamishivi、@mnoukhov、@saurabh_shah2、@tyleraromero の貢献によるグループ作業であり、@vwxyzjn から提供された基盤の上に構築されました。
私たちの取り組みについて詳しくは、論文、ブログ投稿、関連記事(太平洋標準時午前 9 時から始まるライブ ストリームを含む)をご覧ください。