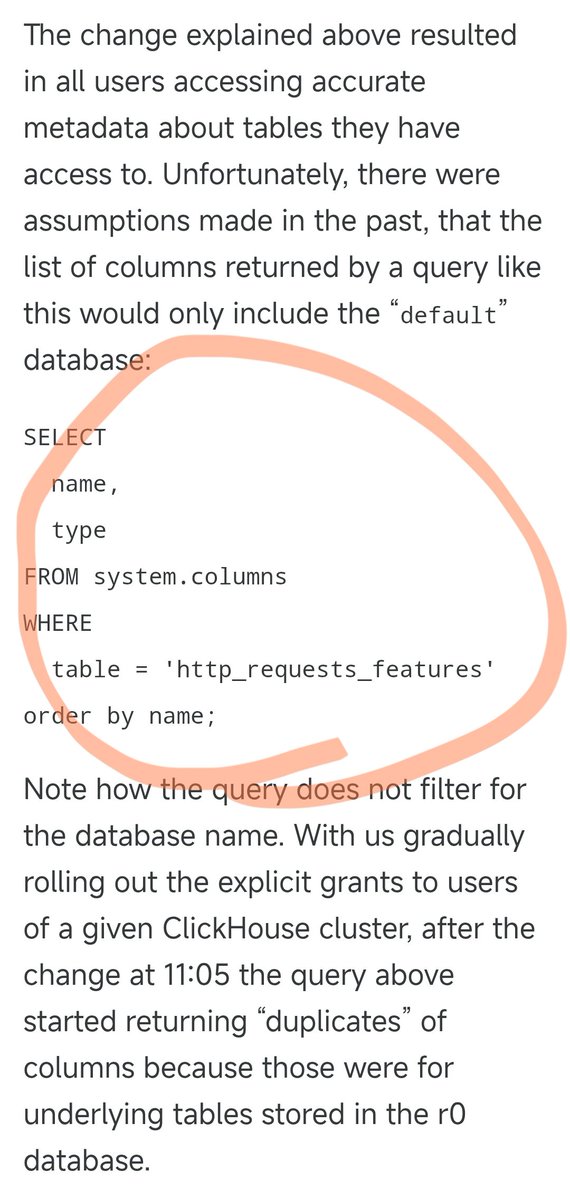
昨夜の Cloudflare の停止は、次の SQL ステートメントが原因でした。 以前は、この SQL クエリはデフォルトのデータベース内の列情報のみを照会し、完璧に機能していました。 しかし、昨日、一部のユーザーの権限がアップグレードされたため、このSQL文はデフォルトのデータベースと基盤となるr0データベースの両方からソリューション情報を返すようになりました。権限を調整した際に、誰もこのSQL文を適切に修正することを思いつきませんでした。 その結果、クエリ結果の数が倍増し、結果ファイルのサイズも倍増しました。当初約60個の特徴が含まれていたファイルは、約120個の特徴に増加しました。 ここで重要な設計上の特徴に触れます。パフォーマンスを最適化するために、Cloudflareのアンチクローラーモジュールは固定量のメモリを事前に割り当て、上限をハードコードしています。つまり、サポートできる機能は最大200個です。 実際に使用されたのは 60 個のみで、余裕は 3 倍以上あったため、当初の制限はかなり緩やかに設定されていました。 しかし、重複データにより、フィーチャーファイルのフィーチャー数が200個という制限を超えると問題が発生します。Rustコードには、フィーチャー数が制限を超えた場合にパニックを起こし、500エラーを返すチェック機能があります。 さらに悪いことに、この機能ファイルは5分ごとに自動生成され、世界中のすべてのサーバーに瞬時にプッシュされます。権限調整は5分ごとに各データベースノードに段階的にプッシュされるため、クエリがどのノードに届くかによって、適切なファイルが生成されることもあれば、不適切なファイルが生成されることもあります。 その結果、非常に奇妙な現象が発生しました。システムは動作しているのに断続的に故障し、時には正常に戻り、時には完全にクラッシュするという状態でした。この症状から、エンジニアたちはDDoS攻撃を受けているのではないかと疑いました。 偶然にも、Cloudflare のステータス ページ (サードパーティによってホストされており、Cloudflare のインフラストラクチャから完全に独立している) もこの時にダウンし、「攻撃」の疑いがさらに深まりました。 これにより、問題を特定する際に間違った方向に考えてしまい、時間を無駄にしていました。 権限調整が徐々に全ノードにプッシュされ、各ノードが破損したファイルを生成し始めたとき、システムは安定した障害状態に陥りました。そして、エンジニアたちはようやく真の問題を特定し、障害を修正することができました。 障害は11月18日19時28分頃に北京で始まり、22時30分に一旦復旧、19日1時6分に完全復旧しました。合計約5時間半にわたり継続しました。これは、Cloudflareにとって2019年以降最大の障害となりました。