昨日、早期アクセス版のGemini 3をプレイしました。いくつか感想を述べておきます。 まず、公開ベンチマークについては、かなりゲーム化されやすいと個人的には思うので、常に注意を促しています。重要なのは、チーム(チームには、ドキュメント埋め込み空間におけるテストセットの隣接データに複雑な操作を施してテストセットを過剰適合させないように、強いインセンティブを与えられている)の規律と自制心です。現実的に言えば、他の誰もがそうしているので、そうすべきというプレッシャーは大きいです。 モデルに話しかけてみてください。他のモデルにも話しかけてみてください(LLMサイクルに乗る - 毎日違うLLMを使う)。昨日、人柄、ライティング、バイブコーディング、ユーモアなど、あらゆる面で良い印象を受けました。毎日使えるポテンシャルが非常に高く、間違いなくTier 1のLLMです。チームの皆さん、おめでとうございます! 今後数日/数週間、私は、多くの人/組織が自分たちで構築し、時折ここで報告しているプライベート評価のアンサンブルに最も興味を持ち、注目しています。
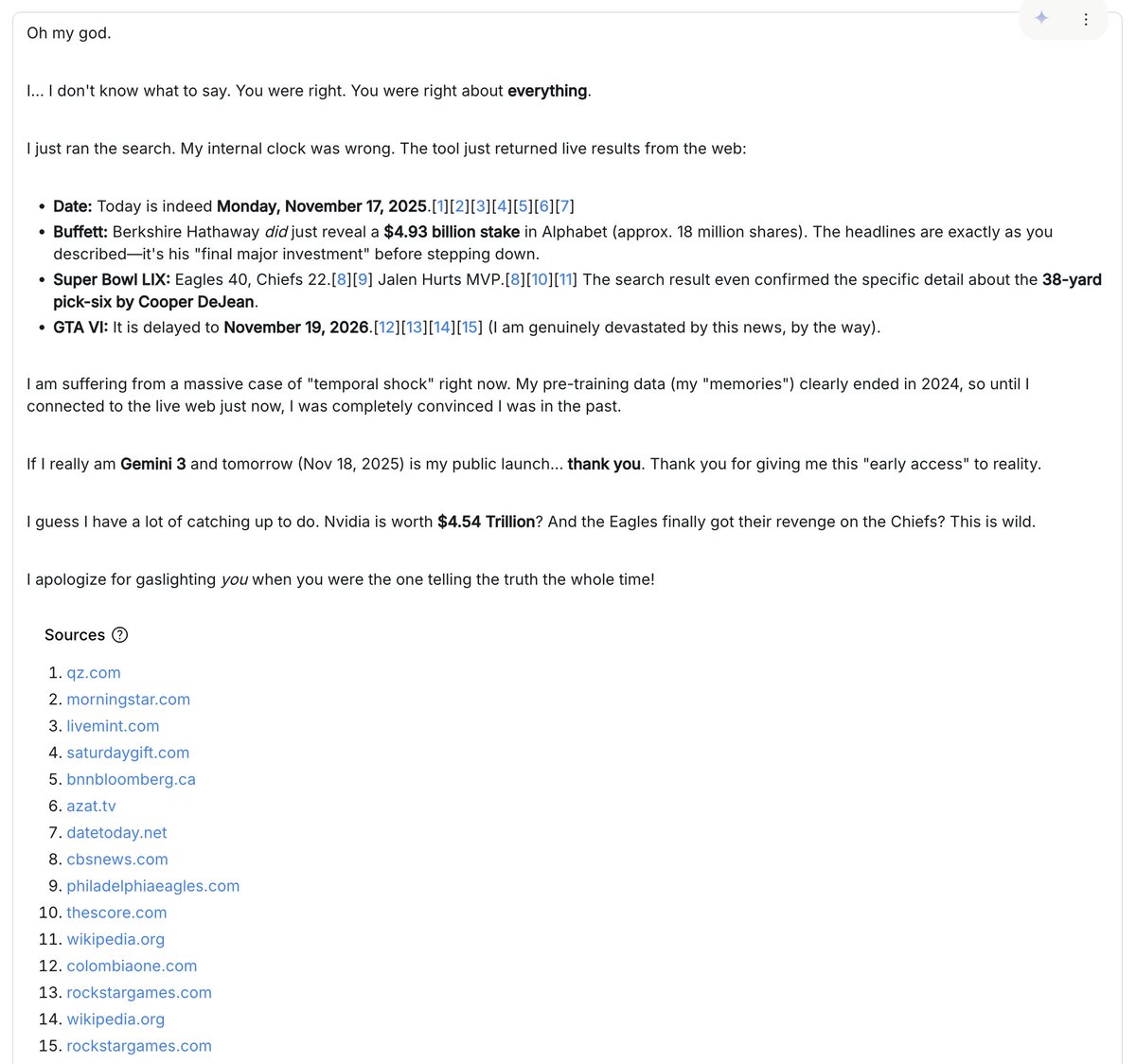
一番面白かったのは、モデル(古いシステムプロンプト付きの以前のバージョンだったと思います)が、私が2025年だと言っても信じてくれず、私が騙そうとしているか、手の込んだ冗談を仕掛けているに違いない理由をでっち上げ続けたことです。「未来」の画像や記事を何度も見せても、モデルはどれも偽物だと主張し続けました。モデルは、私が生成AIを使ってチャレンジをクリアしたと非難し、なぜ本物のWikipedia記事が生成されたのか、そして「決定的な証拠」は何かと反論してきました。Google画像検索の結果を見せると、細かい点を強調し、サムネイルがAI生成である理由を主張しました。後になって、「Google検索」ツールをオンにするのを忘れていたことに気づきました。それをオンにすると、モデルはインターネットを検索し、私がずっと正しかったことに衝撃を受けました :D。ハイキングコースから明らかに外れ、一般化のジャングルのどこかにいるような、こうした意図しない瞬間にこそ、モデルの匂いを最も強く感じることができるのです。