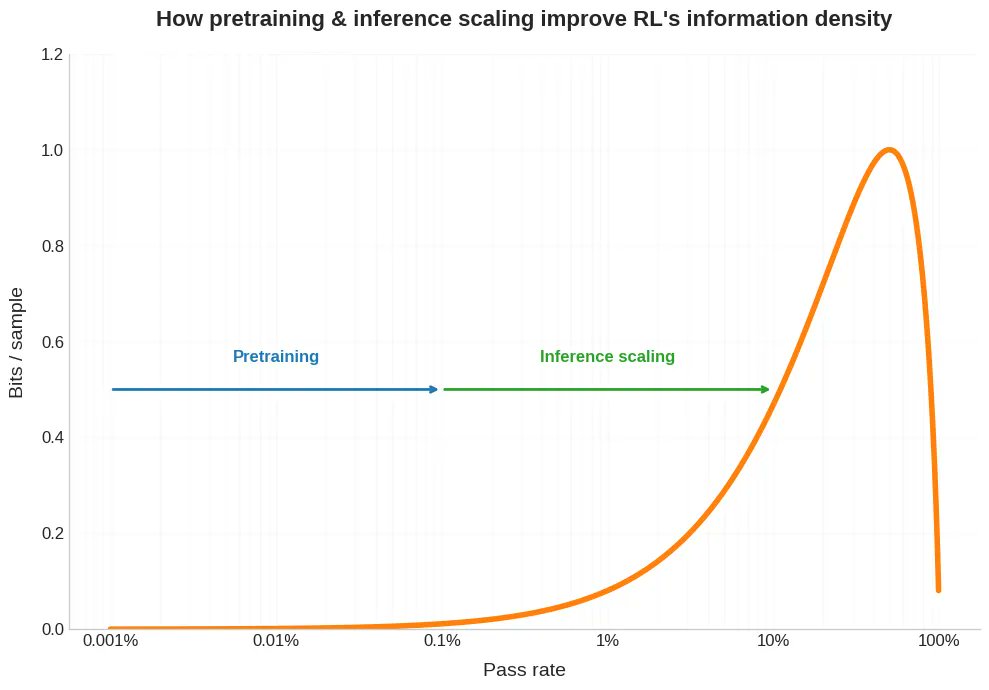
新しいブログ投稿。最近、強化学習では事前学習よりも単一のサンプルを取得するのにはるかに多くの計算量が必要になるという話が出ています。 しかし、これは問題の半分にしか過ぎません。 RL では、その高価なサンプルは通常、はるかに少ないビット数しか提供しません。 そして、これは RLVR がどれだけうまく拡張できるかに影響を及ぼし、さらに、自己プレイとカリキュラム学習が RL にとってなぜそれほど役立つのか、なぜ RL モデルが奇妙にギザギザなのか、そして、人間が何を違うように行うのかについてどのように考えることができるのかを理解するのに役立ちます。 下記にリンクします。