言語モデルのための表現ベースの探索:テスト時からトレーニング後まで リンク - https://t.co/NSxfgxeTX4 私たちは RL を使用してモデルを改善していますが、本質的にはarxiv.org/abs/2510.11686上げるだけであり、真に新しい動作を発見することはほとんどありません。 ここでは、意図的な探索を重視し、同じソリューションのより信頼性の高いバージョンだけでなく、さまざまなソリューションを試すようにモデルを推進します。 主なお問い合わせ: LLM の内部表現 (隠れた状態) は探索をガイドできますか? 意図的な探索は私たちを研ぎ澄ます以上のものへと導くことができるでしょうか?

#2 - VLM に無限のビデオ ストリームを供給したいとします。VLM が崩壊するのをどうやって防ぐのでしょうか。 リンク - https://t.co/b0KulnGDS1 過去のすべてのフレームに対する完全な注意は二次関数的でarxiv.org/abs/2510.09608加します。数分後、コンテキストがトレーニングの長さを超え、モデルが劣化します。スライディングウィンドウはローカル整合性をまあまあに保ちますが、グローバルな解説は非常に愚かになります。彼らは Qwen2.5-VL-Instruct-7B を新しいモデル StreamingVLM に微調整し、それに対応する推論スキームとデータセットを作成しました。コアとなる設計理念は、推論時に kv 排除ヒューリスティックを適用するのではなく、トレーニングをストリーミング推論に合わせて調整することです。設計の主要コンポーネント: ストリーミング対応の KV キャッシュ、連続した RoPE、オーバーラップした完全な注意のトレーニング戦略、ストリーミング固有のデータ。これは非常に優れた論文であり、実際に専用のディスカッションに値します。

#3 - 思考か不正か?推論努力の測定による暗黙の報酬ハッキングの検出 リンク - https://t.co/z2RUEQZuOl モデルは、多くの場合、近道をすることでハックに報酬を与えます。 時にはそれarxiv.org/abs/2510.01367それを読んでハックを見ることができます。他の時にはそれは暗黙の報酬ハッキングです。CoT は合理的に見えます。 モデルは実際には近道をとっていますが(たとえば、漏洩した回答、バグ、RM バイアスの使用など)、それを偽の説明で隠しています。 モデルが不正行為をしている場合、ほとんど「本当の」推論をせずに高い報酬を得ることができます。そのため、著者は、説明を読んでそれを信頼するのではなく、モデルに早期に回答を強制した場合に、モデルがどれだけ早く報酬を獲得できるかを測定することを提案しています。 彼らはこの方法を TRACE (Truncated Reasoning AUC Evaluation) と呼んでいます。

#4 - LLMのための量子化強化学習 リンク - https://t.co/yGkbqg1kVk コード - https://t.arxiv.org/abs/2510.11696な貢献は、「推論github.com/NVlabs/QeRLなぜ使用すべきか」ということです。 QERL は NVFP4 4 ビット量子化を使用します。これにより、量子化ノイズを利用することで探索が驚くほど向上します。このノイズはモデルの出力分布を平坦化し、エントロピーを上げます。これは、図 4、5 のエントロピー曲線に示されています。 このノイズをトレーニング全体にわたって有効に活用するために、著者らは適応量子化ノイズ、つまりRMSNorm図6を通じて注入されるガウス摂動を追加します。 これにより、メモリの約 25~30% を使用しながらフル精度レベルの推論品質が得られ、RL ロールアウトが 1.2~2 倍高速化されるため、32B モデルでも単一の H100 でトレーニングできるようになります。 結果は完全なパラメータ RL と一致しているようです。 詳しく見る価値があります。

#5 - MFU を計算するには? リンク - https://t.co/Vegithub.com/karpathy/nanoc…lerによるnanochatでの素晴らしい議論

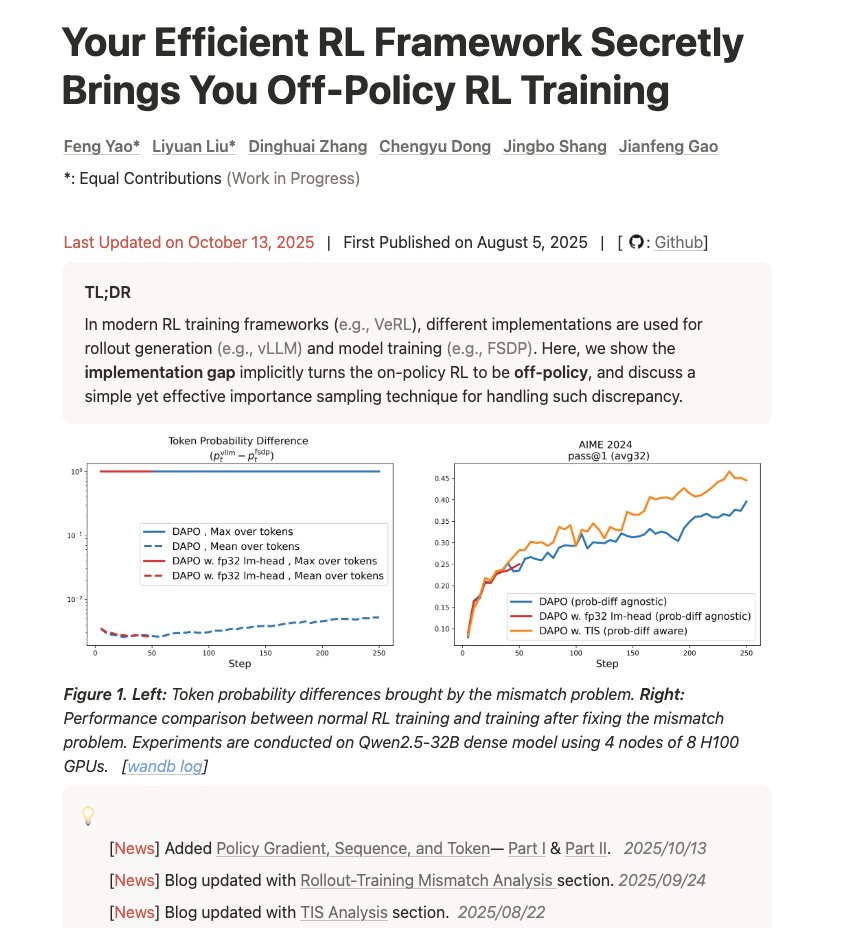
#6 - 効率的なRLフレームワークが密かにポリシー外のRLトレーニングをもたらす リンク - https://t.co/d2Loq5UwZQ トレーニングと推論の不一致を理解し、それが結果にどのfengyao.notion.site/off-policy-rl#…しいブログです。 「あなたのインフラは計算を破綻させています。その理由、その深刻さ、そして重要度サンプリングによる修正方法をご紹介します。」