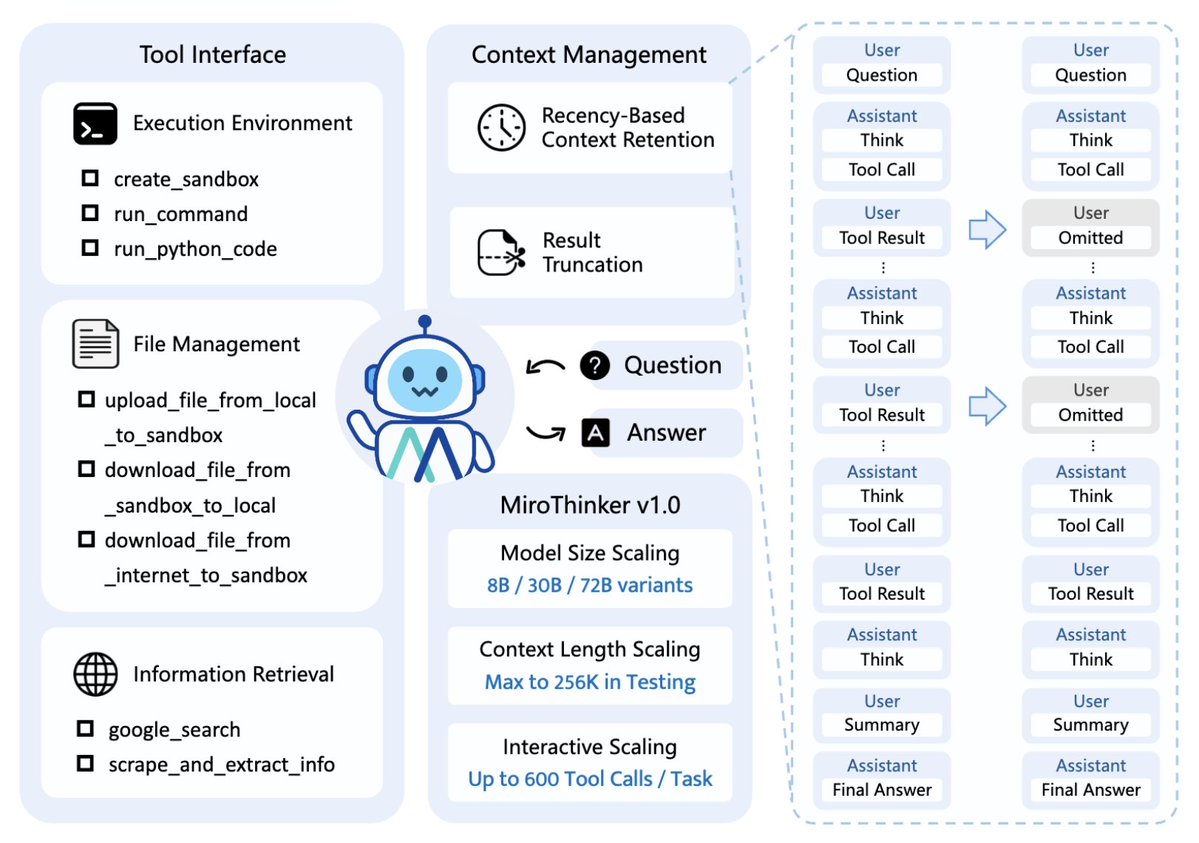
MiroMind チームは、まったく新しいオープンソースの bAgent モデル、MiroThinker v1.0 をリリースしました。 その最大の革新性は、「インタラクティブ スケーリング」という新しい概念を導入した点にあります。 スケーリング則のボトルネックを突破し、AIが自ら進化できるようにします。 このコンセプトは、「モデルのサイズが大きいほどパフォーマンスが向上する」という従来の線形成長パターンから脱却し、「モデルと環境の相互作用の深さと頻度」がインテリジェントな成長の重要な要素であることを強調しています。 MiroThinker は、外部ツール (検索エンジン、Linux サンドボックス、音声認識など) との複数の相互作用と推論をサポートしており、ユーザーはツールを柔軟に使用して情報を取得し、タスクを完了できます。 - 256K コンテキスト: 大量の情報 (数十万語) を記憶できます。 - 一度に最大 600 個のツール呼び出しを実行可能: AI は検索、コード実行、計算、翻訳などの外部ツールを継続的に使用できます。 - 複雑な推論と長時間のタスクを実行可能: 質問に答えるだけでなく、段階的に考え、情報を調査し、解決策を比較します。 「ディープ インタラクション スケーリング」とは何ですか? パフォーマンス ∝ モデルと環境の相互作用の深さ × 反射頻度 言い換えると: - モデルは受動的に知識を吸収するのではなく、能動的に環境と相互作用します。 - それぞれの試行錯誤と反省により、モデルは政策空間で「進化」することができます。 AIが「行動」を起こせば起こすほど、エラーを修正し、推論の質を向上させることができます。 人間も、複雑な事柄を試行錯誤を繰り返し、実践練習することでのみ真に学ぶことができるのと同じです。 🧩 例えば: 人間が料理を学ぶのと同じように、単にレシピを見るだけでは十分ではありません。自分で試して、失敗して、修正して、もう一度試さなければなりません。 AIにとって、環境との複数回の相互作用とフィードバック修正こそが、知能進化の真の原動力となります。それぞれの相互作用は「学習」の機会となり、知能はますます強化されていきます。 そのため、MiroThinker は「コンテキストの長さ」と「インタラクションのラウンド数」の両方を限界まで押し上げ、真の「思考ループ」を形成します。
複数の国際評価において GPT-5 アドバンス バージョンに近い、またはそれを超えるスコア: 複雑なウェブページを理解するためのBrowseCompテストでは47.1%のスコアを獲得し、OpenAIのDeepResearch(51.5%)に迫りました。 Human Ultimate Reasoning Test (HLE) では GPT-5-high を上回りました。 中国語のタスクでは、DeepSeek-v3.2 よりも約 7.7 パーセントポイント優れています。

完全にオープンソースで再現可能 MiroThinker v1.0 のすべてのコア リソースはオープン ソースです。これには以下が含まれます。 - モデルの重み - 推論とインタラクションフレーxiaohu.ai/c/a066c4/mirot…ストラクチャ - github.com/MiroMindAI/Mir…しい紹介:https://t.co/wpST53dHtd GitHub: https://t.co/KQZr8sTcby