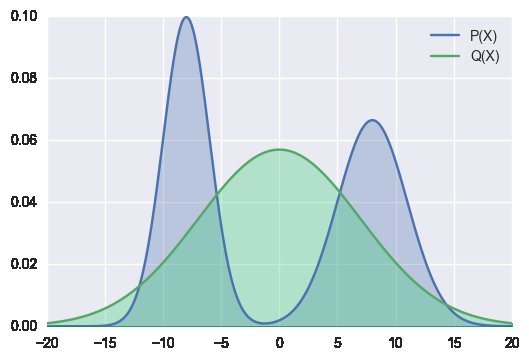
なぜ順方向KLを使用してデータ/モデルから分布を近似することを受け入れるのでしょうか(左の図)? (右の図) のようなアルゴリズムを目指してみませんか?

それとも、分布全体ではなく、より最近のバイアスを使用して KL を最小化しているため、すでにそれを実行しているのでしょうか?
スレッドを読み込み中
X から元のツイートを取得し、読みやすいビューを準備しています。
通常は数秒で完了しますので、お待ちください。
2 件のツイート · 2025/11/02 7:14
なぜ順方向KLを使用してデータ/モデルから分布を近似することを受け入れるのでしょうか(左の図)? (右の図) のようなアルゴリズムを目指してみませんか?
それとも、分布全体ではなく、より最近のバイアスを使用して KL を最小化しているため、すでにそれを実行しているのでしょうか?