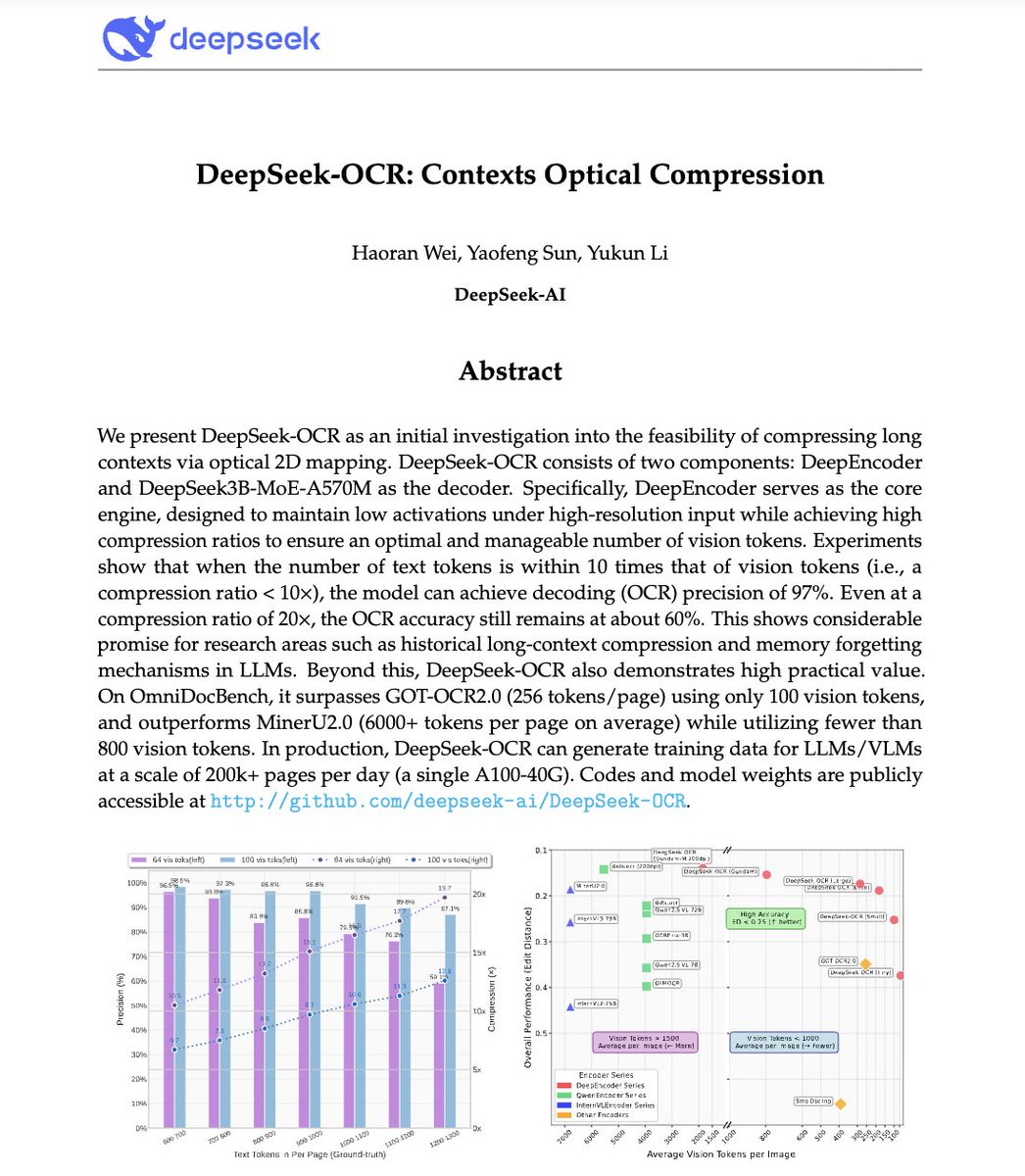
🚨 DeepSeek がちょっとすごいことをしました。 彼らは、長いテキストをビジョントークンに圧縮し、文字通り段落をピクセルに変換する OCR システムを構築しました。 彼らのモデルであるDeepSeek-OCRは、10倍の圧縮で97%のデコード精度を達成し、20倍の圧縮でも60%の精度を維持しています。つまり、LLMに必要なトークンのほんの一部を使って、1枚の画像で文書全体を表現できるということです。 さらにすごいのは、GOT-OCR2.0 や MinerU2.0 よりも最大 60 倍少ないトークンを使用し、1 台の A100 で 1 日あたり 20 万ページ以上を処理できることです。 これにより、AI の最大の問題の 1 つである、長期コンテキストの非効率性が解決される可能性があります。 より長いシーケンスに追加料金を支払う代わりに、モデルはすぐにテキストを読むのではなく見るようになるかもしれません。 コンテキスト圧縮の将来は、まったくテキストではなくなる可能性があります。 それは光学的なものかもしれません👁️ ギットハブ。 com/deepseek-ai/DeepSeek-OCR
1. ビジョンテキスト圧縮:核となるアイデア LLM は、トークンの使用量が長さの 2 乗に比例して増加するため、長いドキュメントの処理に苦労します。 DeepSeek-OCR はそれを逆転させます。テキストを読み取る代わりに、文書全体をビジョン トークンとしてエンコードします。各トークンは圧縮された視覚情報を表します。 結果: GPT-4 で 1 ページを処理するのと同じトークン バジェットに、10 ページ分のテキストを収めることができます。

2. DeepEncoder - 光学コンプレッサー スターの DeepEncoder を紹介します。 これは、16 倍畳み込みコンプレッサーによってブリッジされた SAM (知覚用) と CLIP (グローバル ビジョン用) の 2 つのバックボーンを使用します。 これにより、アクティベーション メモリが爆発することなく、高解像度の理解を維持することができます。 エンコーダーは、数千の画像パッチを数百のコンパクト ビジョン トークンに変換します。

3. マルチ解像度「ガンダム」モード 文書は、請求書≠設計図≠新聞など多岐にわたります。 これを処理するために、DeepSeek-OCR は、Tiny、Small、Base、Large、Gundam の複数の解像度モードをサポートしています。 ガンダム モードは、ローカル タイルと 512×512 から 1280×1280 にスケーリングされたグローバル ビューを効率的に組み合わせます。 1 つのモデル、複数の解像度、再トレーニングは不要です。

4. データエンジンOCR 1.0から2.0 彼らは単にテキストスキャンのトレーニングをしたわけではありません。 DeepSeek-OCR のデータには以下が含まれます。 • 100言語にわたる3,000万ページ以上のPDF • 1000万の自然風景OCRサンプル • 1000万枚のチャート + 500万枚の化学式 + 100万個の幾何学問題 単に読むだけでなく、科学的な図、方程式、レイアウトを解析します。

5. これは「単なる OCR」ではありません。 これはコンテキスト圧縮の概念実証です。 テキストを 10 分の 1 のトークンで視覚的に表現できる場合、LLM は長期記憶と効率的な推論に同じアイデアを使用できます。 GPT-5 が 100 万トークンのドキュメントを 10 万トークンのイメージマップとして処理することを想像してください。

プロンプトを書くのに何時間も無駄にするのはやめましょう → 10,000以上のすぐに使えるプロンプト → 数秒で自分だけの作品を作成 → 生涯アクセス。一度のお支払いで。 コピーを入手してください👇