Tang Jie (@jietang) est professeur à l'université Tsinghua et directeur scientifique en intelligence artificielle chez Zhipu (l'entreprise à l'origine des modèles GLM). Il est également l'un des plus grands experts en modélisation à grande échelle en Chine. Il a récemment publié un long message sur Weibo (voir les commentaires) où il partage ses réflexions sur les modèles à grande échelle en 2025. Il est intéressant de noter que Tang Jie et Andrej Karpathy partagent de nombreuses observations, tout en soulignant certains points de vue divergents. La mise en parallèle des perspectives de ces deux experts de renom permet d'obtenir une vision plus complète. Le contenu est assez long, mais je souhaite souligner une phrase au début : Le premier principe de l'application des modèles d'IA ne devrait pas être la création de nouvelles applications ; son essence réside dans le remplacement du travail humain par l'IA générale. Par conséquent, le développement d'une IA capable de remplacer différents emplois est la clé de son application. Si vous développez des applications d'IA, gardez toujours à l'esprit ce principe fondamental : l'IA n'a pas pour vocation de créer de nouveaux produits, mais de remplacer le travail humain. Une fois ce principe assimilé, les priorités deviendront évidentes. L'argument principal de Tang Jie comporte sept niveaux de logique. --- Premier niveau : L'entraînement préalable ne l'a pas tué, il n'est simplement plus le seul protagoniste. Le pré-entraînement demeure la base permettant aux modèles d'acquérir des connaissances du monde et des capacités de raisonnement élémentaires. Davantage de données, des paramètres plus nombreux et une puissance de calcul accrue demeurent les moyens les plus efficaces d'améliorer l'intelligence d'un modèle. C'est comme pour un enfant qui grandit : la quantité de nourriture (puissance de calcul) et de nutriments (données) doit être suffisante. C'est une loi physique incontournable. Mais l'intelligence seule ne suffit pas. Les modèles actuels présentent un problème : ils sont souvent déséquilibrés. Pour améliorer leurs performances, nombre d'entre eux se concentrent sur des problèmes spécifiques, ce qui les rend moins efficaces face à la complexité du monde réel. C'est comme jeter un enfant dans le grand bain du monde du travail après neuf années de scolarité obligatoire (formation initiale) et le laisser gérer les situations imprévues qui ne figurent pas dans les manuels scolaires ; c'est là que se développent les véritables compétences. Par conséquent, l'accent est mis ensuite sur les phases de « milieu et de fin d'entraînement ». Ces deux étapes permettent d'« activer » les capacités du modèle, notamment sa capacité d'alignement dans les scènes complexes. Que sont les scénarios de longue traîne ? Ce sont des besoins rares mais bien réels. Par exemple, aider les avocats à rédiger certains contrats spécifiques ou aider les médecins à analyser des images de maladies rares. Ces scénarios représentent un faible pourcentage de l’ensemble des tests, mais sont essentiels dans les applications concrètes. Bien que les benchmarks généraux évaluent les performances des modèles, ils peuvent aussi conduire à un surapprentissage. Ceci rejoint l'avis de Karpathy selon lequel « l'entraînement sur l'ensemble de test est un art nouveau ». Chacun cherche à améliorer son classement, mais obtenir un score élevé au classement général ne garantit pas la résolution de problèmes concrets. --- Deuxième niveau : L'agent représente la transition du statut d'« étudiant » à celui de « personne active ». Tang Jie a utilisé une analogie frappante : Sans capacités d'agent, un modèle complexe n'est qu'un « doctorat théorique ». Peu importe le nombre de livres qu'une personne lit, même en atteignant un niveau postdoctoral, si elle ne peut pas résoudre de problèmes, elle n'est qu'un réceptacle de connaissances, incapable de générer de la productivité. Cette analogie est pertinente. Le pré-entraînement s'apparente à suivre des cours, et l'apprentissage par renforcement à s'exercer sur des problèmes, mais nous sommes encore au stade de l'apprentissage. L'agent est essentiel au bon fonctionnement du modèle ; il constitue le seuil permettant d'entrer dans le monde réel et de générer une valeur pratique. La généralisation et le transfert entre différents environnements d'agents ne sont pas aisés. Les compétences acquises dans un environnement de programmation peuvent ne pas être efficaces dans un environnement de navigateur. L'approche la plus simple consiste actuellement à accumuler en continu des données provenant de divers environnements et à mettre en œuvre un apprentissage par renforcement adapté à chacun d'eux. Auparavant, lors du développement d'agents, nous intégrions divers outils au modèle. La tendance actuelle consiste à incorporer directement les données issues de ces outils dans l'« ADN » du modèle pour son entraînement. Cela peut paraître un peu absurde, mais c'est effectivement la voie la plus efficace actuellement. Karpathy a également cité Agent parmi les changements les plus importants de cette année. Il a pris Claude Code en exemple, soulignant qu'Agent devrait pouvoir « résider dans votre ordinateur », en appelant des outils, en exécutant des boucles et en résolvant des problèmes complexes. --- Troisième niveau : la mémoire est un besoin fondamental, mais la manière de l’obtenir reste encore floue. Tang Jie a consacré beaucoup de temps à la question de la mémoire. Il estime que la mémoire est essentielle à la mise en œuvre des modèles dans des environnements réels. Il a divisé la mémoire humaine en quatre couches : - Mémoire à court terme, correspondant au cortex préfrontal - Mémoire à moyen terme, correspondant à l'hippocampe Les souvenirs à long terme sont situés dans le cortex cérébral. - La mémoire historique humaine, correspondant à Wikipédia et aux archives historiques L'IA doit également imiter ce mécanisme ; le modèle à grande échelle pourrait correspondre à : - Fenêtre contextuelle → Mémoire à court terme - Recherche RAG → Mémoire intermédiaire - Paramètres du modèle → Mémoire à long terme Une approche possible est la « mémoire compressée », qui consiste à stocker les informations importantes dans un format concis et simplifié, au sein même du contexte. Les « contextes ultra-longs » actuels ne prennent en compte que la mémoire à court terme, se contentant d'allonger la taille du « post-it » utilisable. Si la fenêtre contextuelle devient suffisamment longue à l'avenir, la mémoire à court, moyen et long terme pourrait être prise en charge. Mais un problème encore plus complexe se pose : comment mettre à jour les connaissances du modèle ? Comment modifier ses paramètres ? Ce problème reste non résolu. --- Quatrième couche : l’apprentissage en ligne et l’auto-évaluation pourraient constituer le prochain paradigme de mise à l’échelle. Cette section représente la partie la plus tournée vers l'avenir du point de vue de Tang Jie. Le modèle actuel est « hors ligne », c'est-à-dire qu'il est entraîné mais ne change pas. Cela pose plusieurs problèmes : le modèle ne peut pas véritablement itérer de manière autonome, le réentraînement gaspille des ressources et une grande quantité de données interactives est perdue. Idéalement, le modèle devrait pouvoir apprendre en ligne et devenir plus intelligent à chaque utilisation. Toutefois, pour y parvenir, une condition préalable est nécessaire : le modèle doit savoir s’il est correct ou non. C’est ce qu’on appelle l’« auto-évaluation ». Si le modèle peut juger de la qualité de sa propre production, même par une estimation probabiliste, il connaît l’objectif d’optimisation et peut s’améliorer. Tang Jie estime que la mise en place d'un mécanisme d'auto-évaluation pour un modèle est un problème complexe, mais qu'elle pourrait constituer la prochaine voie de développement. Il a employé plusieurs termes : apprentissage continu, apprentissage en temps réel et apprentissage en ligne. Cela rejoint l'argument de Karpathy concernant RLVR. RLVR est efficace précisément parce qu'il fournit des « récompenses vérifiables », permettant au modèle de savoir s'il a raison ou tort. Si ce mécanisme peut être généralisé à davantage de scénarios, l'apprentissage en ligne pourrait devenir une réalité. --- Cinquième niveau : Le premier principe des applications de l'IA est le « remplacement d'emplois ». Voici la phrase qui m'a le plus inspiré : Le premier principe de l'application des modèles d'IA ne devrait pas être la création de nouvelles applications ; son essence réside dans le remplacement du travail humain par l'IA générale. Par conséquent, le développement d'une IA capable de remplacer différents emplois est la clé de son application. L'essence de l'IA n'est pas de créer de nouvelles applications, mais de remplacer les emplois humains. Deux voies : 1. Transformer les logiciels qui nécessitaient auparavant une intervention humaine en IA. 2. Créer un logiciel d'IA qui corresponde à un emploi humain spécifique, remplaçant directement les travailleurs humains. Le chat a déjà partiellement remplacé la recherche et intègre désormais l'interaction émotionnelle. La prochaine étape consiste à remplacer le service client, les programmeurs juniors et les analystes de données. Par conséquent, la percée majeure en 2026 réside dans le remplacement de différents emplois par l'IA. Les entrepreneurs ne devraient pas se demander « quel logiciel je veux développer pour les utilisateurs », mais plutôt « quel type d'employé IA je veux créer pour aider le patron à réduire les coûts de main-d'œuvre pour un poste donné ». Autrement dit, au lieu de toujours penser à créer un nouveau produit « IA+X », il faut d'abord réfléchir aux emplois humains qui peuvent être remplacés, puis remonter la chaîne pour déterminer la forme du produit. Cela fait écho à l'observation de Karpathy à propos du « Curseur pour X ». Si le Curseur est essentiellement « la version IA du travail du programmeur », alors des choses similaires apparaîtront dans divers secteurs. --- Sixième couche : Le modèle à l'échelle du domaine est une « fausse proposition ». Ce point de vue pourrait en déranger certains, mais Tang Jie l'affirme sans détour : le modèle spécifique à un domaine est une proposition erronée. Si l'on parle d'IA générale, quel est l'intérêt d'une « IA générale spécifique à un domaine » ? La raison d'être des grands modèles spécifiques à un domaine est que les entreprises d'applications refusent d'admettre leur défaite face aux entreprises de modélisation d'IA et espèrent se constituer un avantage concurrentiel grâce à leur savoir-faire métier et dompter l'IA pour en faire un outil. Mais l'essence même de l'IA est un « tsunami » : elle emporte tout sur son passage. Inévitablement, certaines entreprises, dans certains secteurs, perdront leurs avantages concurrentiels et seront entraînées dans le monde de l'IA générale. Leurs données métier, leurs processus et les données de leurs agents seront progressivement intégrés au modèle principal. Bien sûr, les modèles de domaine existeront longtemps avant que l'IA générale ne devienne réalité. Mais quelle sera la durée de cette période ? Difficile à dire, car l'IA évolue trop vite. --- La septième couche : Intelligence multimodale et incarnée – un avenir prometteur, mais un chemin difficile. L'informatique multimodale représente assurément l'avenir. Cependant, le problème actuel est qu'elle n'apporte qu'une aide limitée pour repousser les limites de l'intelligence artificielle générale. Le texte, le multimodal et la génération multimodale peuvent être développés plus efficacement séparément. Bien entendu, explorer une combinaison des trois exige du courage et des financements. L'intelligence incarnée (robots) est encore plus complexe. Le défi est le même qu'avec les agents : la polyvalence. On programme un robot pour fonctionner dans le scénario A, mais il ne fonctionne pas dans un autre. Que faire ? La collecte et la synthèse des données sont à la fois difficiles et coûteuses. Que faire ? Collecter des données ou les synthétiser. Aucune de ces options n’est simple et les deux sont coûteuses. Mais à l’inverse, dès que le volume de données augmente et que des fonctionnalités généralistes émergent, une barrière à l’entrée se forme naturellement. Un autre problème souvent négligé est que les robots eux-mêmes posent également problème. L'instabilité et les dysfonctionnements fréquents sont des problèmes matériels qui limitent le développement de l'intelligence incarnée. Tang Jie prévoit que des progrès significatifs seront réalisés dans ces domaines d'ici 2026. --- En reliant l'article de Tang Jie à l'ensemble du contexte, on découvre une feuille de route assez claire : Actuellement, la mise à l'échelle pré-entraînée reste efficace, mais il faudrait davantage mettre l'accent sur l'alignement et les capacités de gestion des longues traînes. Récemment, les agents ont constitué une avancée majeure, permettant aux modèles de passer de la simple communication à l'action. À moyen terme, les systèmes de mémorisation et l'apprentissage en ligne sont des cours essentiels, et les modèles doivent apprendre à s'auto-évaluer et à itérer. À long terme, la substitution d'emplois est l'essence même des applications, et l'avantage concurrentiel du secteur sera brisé par l'AGI. À long terme, les approches multimodales et incarnées se développeront indépendamment, en attendant la maturation des technologies et des données. --- En comparant les points de vue de Tang Jie et de Karpathy, plusieurs points de consensus peuvent être observés : Premièrement, le changement fondamental en 2025 est la mise à niveau du paradigme de formation, passant de la « pré-formation comme méthode principale » à la « collaboration en plusieurs étapes ». Deuxièmement, Agent représente une étape importante, un saut clé pour les modèles passant de l'apprentissage à la pratique. Troisièmement, il existe un écart entre les scores de référence et les capacités réelles, et cette question fait l'objet d'une attention croissante. Quatrièmement, l'essence des applications d'IA est de remplacer ou d'améliorer les emplois humains, et non de créer des applications pour le simple plaisir de créer des applications. Les différentes perspectives sont également intéressantes. Karpathy s'intéresse davantage à la question philosophique de la forme que prend l'intelligence artificielle, tandis que Tang Jie se concentre sur le problème d'ingénierie de la mise en œuvre du modèle dans des situations concrètes. L'une privilégie la compréhension, l'autre la mise en œuvre. Les deux points de vue sont nécessaires. Ce n'est qu'avec une compréhension claire que nous pourrons savoir si nous sommes sur la bonne voie ; ce n'est qu'avec une ingénierie solide que nous pourrons transformer les idées en réalité. 2026 sera une année merveilleuse.
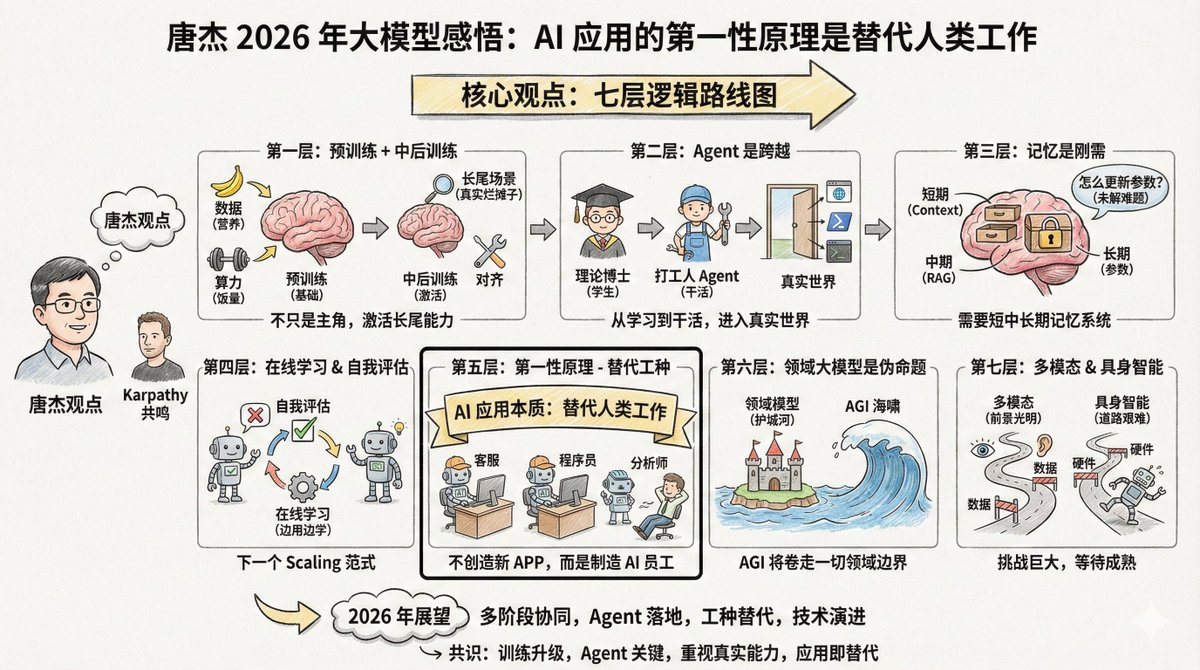
Le contenu sweibo.com/2126427211/QjI…te Weibo de Tang Jie : https://t.co/AOdkBXNIey J'aimerais partager quelques réflexions récentes, en espérant qu'elles seront utiles à tous. Le pré-entraînement permet aux grands modèles d'acquérir une connaissance intuitive du monde et de développer des capacités de raisonnement élémentaires. L'utilisation de données plus nombreuses, de paramètres plus importants et d'une puissance de calcul accrue demeure la méthode la plus efficace pour faire évoluer les modèles de base. L'activation de l'alignement et l'amélioration des capacités d'inférence, notamment l'activation de capacités plus complètes pour la gestion des variations à longue traîne, constituent un autre élément clé pour garantir la performance des modèles. Si les benchmarks généraux évaluent la performance globale des modèles, ils peuvent également entraîner un surapprentissage pour nombre d'entre eux. Dans des scénarios réels, comment les modèles peuvent-ils s'aligner plus rapidement et plus efficacement sur les variations à longue traîne des scènes réelles, renforçant ainsi le réalisme ? Les interventions en cours et en fin d'entraînement permettent un alignement rapide et des capacités d'inférence robustes dans un plus grand nombre de scénarios. Les capacités des agents représentent une étape cruciale dans l'expansion des capacités des modèles et sont essentielles pour permettre aux modèles d'IA d'intégrer le monde réel (virtuel ou physique). Sans ces capacités, les grands modèles resteront au stade de l'apprentissage théorique, à l'instar d'une personne qui, même au doctorat, accumule des connaissances sans les mettre en pratique. Auparavant, les agents étaient implémentés via l'application du modèle ; désormais, les modèles peuvent intégrer directement les données des agents dans le processus d'entraînement, ce qui accroît leur polyvalence. Cependant, la généralisation et le transfert entre différents environnements d'agents restent complexes. La solution la plus simple consiste donc à enrichir continuellement les données provenant de ces environnements et à implémenter un apprentissage par renforcement adapté à chacun. L'acquisition d'une mémoire du modèle est essentielle, une capacité nécessaire à toute application d'un modèle dans des environnements réels. La mémoire humaine se divise en quatre étapes : à court terme (cortex préfrontal), à moyen terme (hippocampe), à long terme (cortex cérébral distribué) et historique (wikis ou livres d'histoire). La capacité des grands modèles à acquérir une mémoire à travers ces différentes étapes est cruciale. Le contexte, l'horizon temporel et les paramètres du modèle peuvent correspondre à différentes étapes de la mémoire humaine, mais la manière d'y parvenir est déterminante. Une approche possible est la compression de la mémoire, qui consiste simplement à stocker le contexte. Si un grand modèle peut gérer des contextes suffisamment longs, l'acquisition d'une mémoire à court, moyen et long terme devient pratiquement possible. Cependant, l'itération sur les connaissances du modèle et la modification de ses paramètres demeurent un défi majeur. Apprentissage en ligne et auto-évaluation. La compréhension des mécanismes de la mémoire place l'apprentissage en ligne au cœur des préoccupations. Les modèles à grande échelle actuels sont périodiquement réentraînés, ce qui pose plusieurs problèmes : le modèle ne peut pas véritablement s'auto-améliorer, or l'auto-apprentissage et l'auto-itération seront inévitablement nécessaires à l'étape suivante ; le réentraînement est également coûteux et entraîne la perte d'une grande quantité de données interactives. Par conséquent, la mise en œuvre de l'apprentissage en ligne est cruciale, et l'auto-évaluation en est un aspect fondamental. Pour qu'un modèle apprenne par lui-même, il doit d'abord savoir s'il est correct ou incorrect. S'il le sait (même de manière probabiliste), il connaîtra l'objectif d'optimisation et pourra s'améliorer. Ainsi, la conception d'un mécanisme d'auto-évaluation des modèles représente un défi. Cela pourrait également constituer le prochain paradigme de mise à l'échelle. Apprentissage continu/apprentissage en temps réel/apprentissage en ligne ? Enfin, à mesure que le développement de modèles à grande échelle devient de plus en plus intégré, il est inévitable de combiner développement et application. L'objectif principal de l'application des modèles d'IA ne devrait pas être la création de nouvelles applications ; son essence réside dans le remplacement du travail humain par l'IA. Par conséquent, le développement d'une IA capable de remplacer différents emplois est essentiel à son application. La messagerie instantanée remplace partiellement la recherche et, d'une certaine manière, elle intègre l'interaction émotionnelle. L'année prochaine sera une année charnière pour le remplacement de différents emplois par l'IA. En conclusion, abordons la multimodalité et l'incarnation. La multimodalité représente sans aucun doute un avenir prometteur, mais le problème actuel est qu'elle ne contribue pas significativement à l'augmentation des capacités de l'intelligence artificielle générale (IAG), et que cette augmentation reste inconnue. L'approche la plus efficace consiste peut-être à développer ces trois aspects séparément : le texte, la multimodalité et la génération multimodale. Bien sûr, explorer leur combinaison, même modérée, pourrait révéler des capacités inédites, mais cela exige du courage et un soutien financier conséquent. De même, si vous comprenez le fonctionnement des agents, vous saurez où se situent les points faibles de l'intelligence incarnée : il est trop difficile de généraliser (bien que cela ne soit pas forcément vrai), mais activer des capacités incarnées générales avec un échantillon restreint est pratiquement impossible. Que faire, alors ? Collecter ou synthétiser des données n'est ni simple ni bon marché. À l'inverse, à mesure que le volume de données augmente, des capacités générales émergent naturellement et constituent une barrière à l'entrée. Bien sûr, ce défi ne concerne que l'intelligence artificielle. Pour l'intelligence incarnée, les robots eux-mêmes posent également problème ; leur instabilité et leurs dysfonctionnements fréquents limitent son développement. Des progrès significatifs sont attendus dans ces domaines d'ici 2026. Abordons également le modèle maître de domaine et ses applications. J'ai toujours pensé que ce modèle était une illusion : avec l'IA déjà en place, quelle IA spécifique à un domaine existe-t-il ? Cependant, l'IA n'étant pas encore pleinement aboutie, les modèles de domaine persisteront longtemps (difficile de dire combien de temps exactement, compte tenu du rythme rapide de son développement). Leur existence reflète essentiellement la réticence des entreprises d'applications à s'avouer vaincues par les entreprises d'IA. Elles espèrent se constituer un rempart de savoir-faire métier, résister à l'intrusion de l'IA et la maîtriser comme un outil. Mais l'IA est par nature comme un tsunami : elle emporte tout sur son passage. Inévitablement, certaines entreprises de domaine finiront par franchir leurs remparts et se laisser happer par le monde de l'IA. En bref, les données, les processus et les données des agents du domaine intégreront progressivement le modèle maître. L'application de modèles à grande échelle doit également revenir aux principes fondamentaux : l'IA n'a pas besoin de créer de nouvelles applications. Son essence est de simuler, de remplacer ou d'assister les humains dans l'exécution de certaines tâches humaines essentielles (certains métiers). Cela conduit généralement à deux types d'applications : d'une part, l'intégration de l'IA dans des logiciels existants, modifiant ainsi ce qui nécessitait initialement une intervention humaine ; d'autre part, la création de logiciels d'IA adaptés à un métier spécifique, remplaçant le travail humain. Par conséquent, l'application de modèles à grande échelle doit être utile aux personnes et créer de la valeur. Si un logiciel d'IA est créé mais que personne ne l'utilise et qu'il ne génère aucune valeur, alors ce logiciel est dépourvu de toute vitalité.