Pi0.5 de @physical_int est l'une des meilleures politiques de robotique open source de bout en bout actuellement disponibles 🤖 Il s'agit d'une version améliorée du Raspberry Pi 0. Les dernières avancées concernant x.com/physical_int/s…sées sur cette version. Voyons comment cela fonctionne :
Qu'est-ce qui a changé par rapport au Pi0 ? - Tokenisation FAST - Une version FAST optionnelle était disponible sur Pi0, mais elle est devenue une composante essentielle de la formation pour Pi0.5. - Système 2 - s'appuyant sur l'article de Hi Robot, Pi 0.5 utilise sa partie VLM comme un système de raisonnement de haut niveau (système 2) pour raisonner et planifier des tâches complexes. - Une meilleure recette d'entraînement et quelques petites modifications.
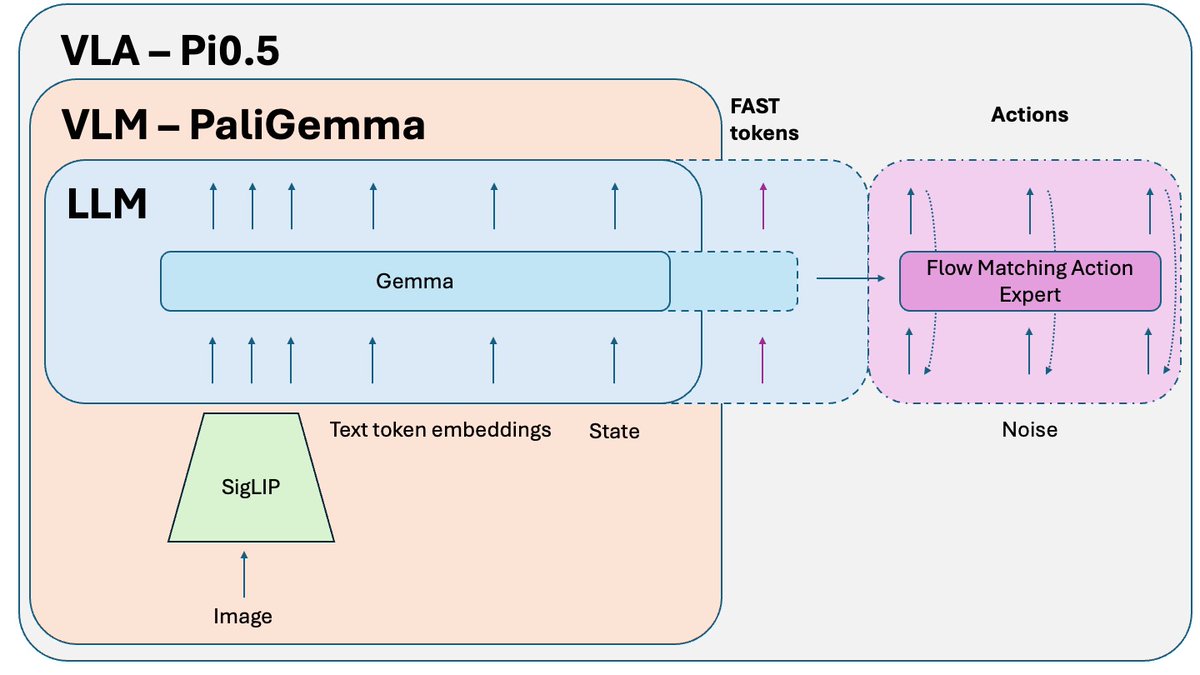
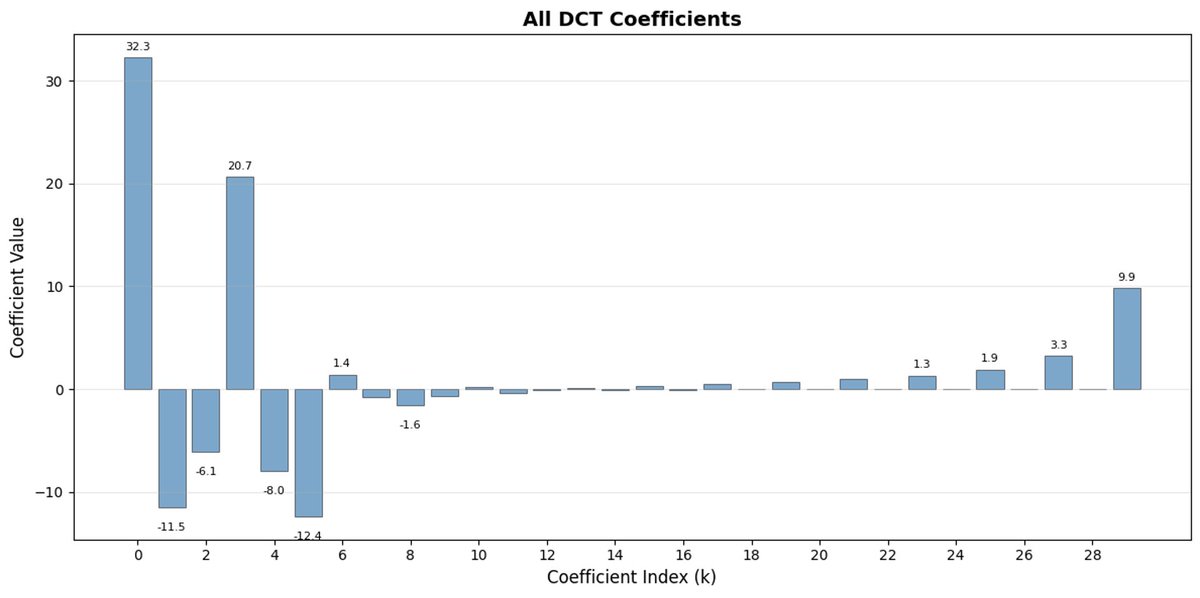
FAST est une approche de tokenisation qui permet de compresser des séquences d'actions en jetons discrets très denses en informations grâce à la DCT (Discrete Cosine Transform) et au BPE (Byte Pair Encoding). La DCT est le même algorithme que celui utilisé pour la compression d'images en JPEG. Elle représente le signal comme une somme de fonctions cosinus de fréquences différentes. Les premières composantes capturent la tendance générale et la forme du signal, tandis que les composantes suivantes capturent de plus en plus de détails. Le JPEG progressif envoie d'abord les composantes basse fréquence, ce qui donne une image floue, puis plus nette à mesure que l'on ajoute des composantes.



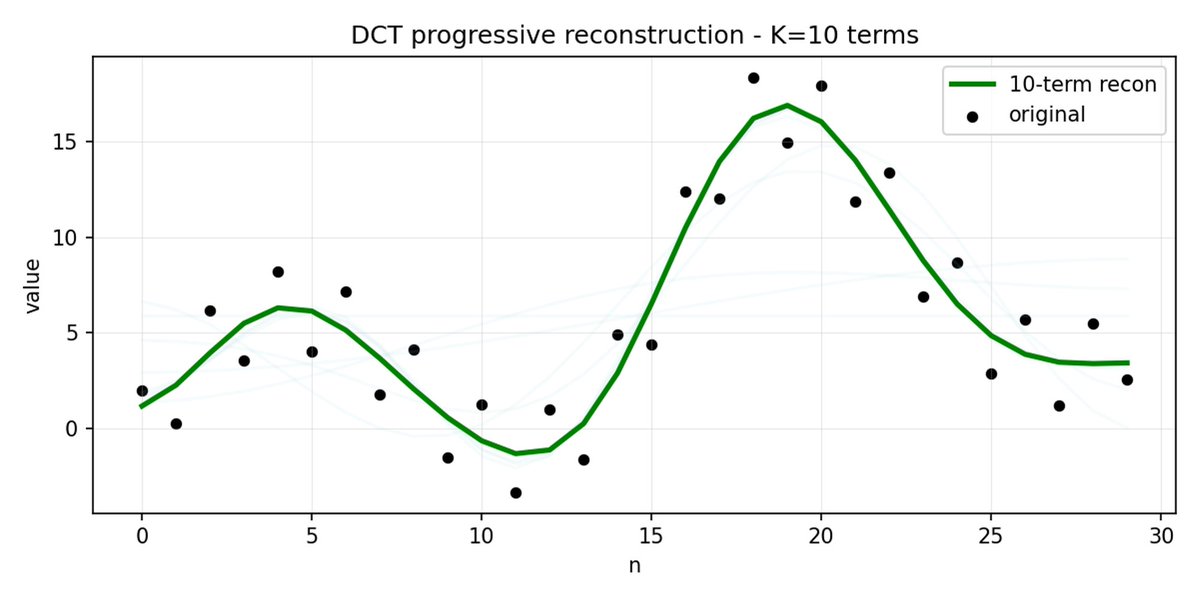
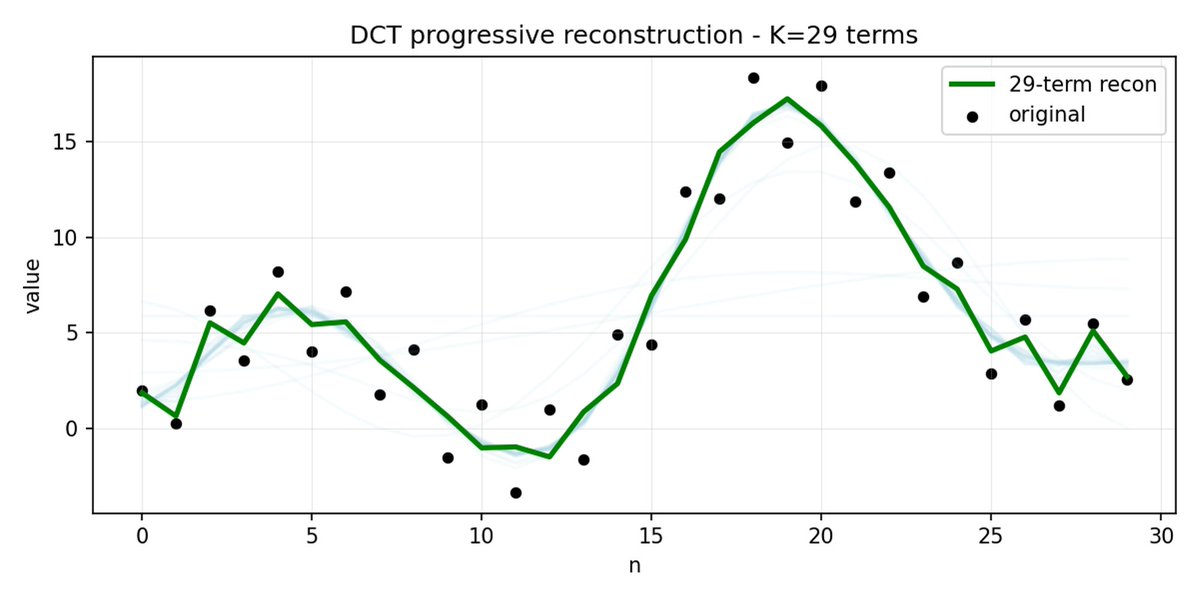
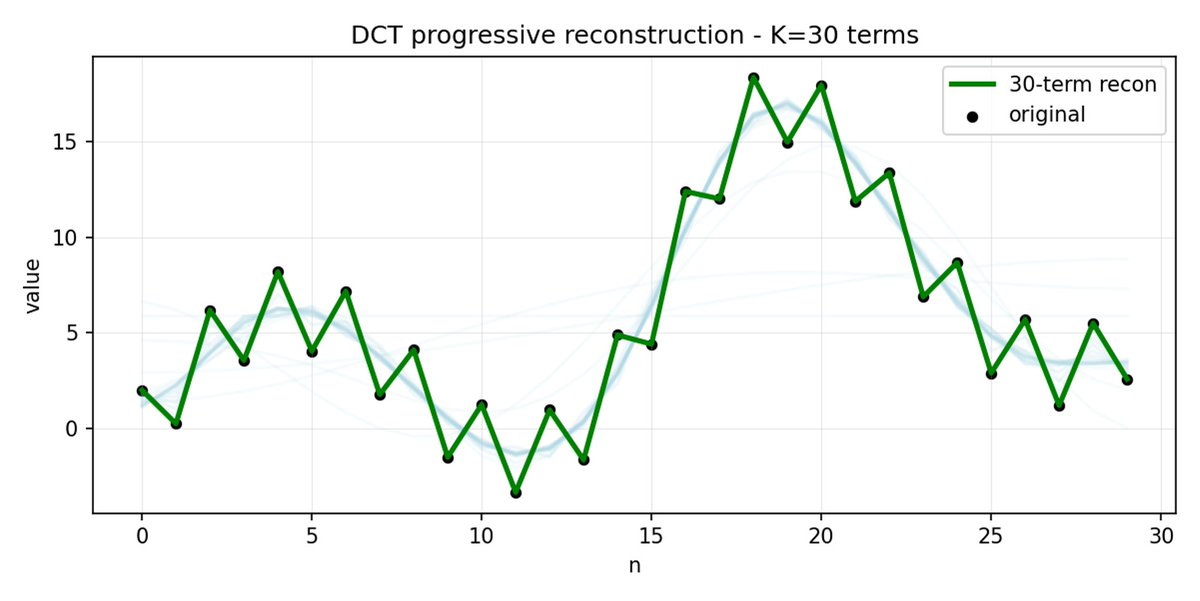
FAST fait de même pour les blocs d'action. Au lieu de prédire 30 valeurs d'action corrélées, vous prédisez une représentation plus courte et plus significative. Souvent, on peut ne conserver que quelques coefficients principaux (qui contiennent la plus grande partie de l'énergie du signal d'origine) et reconstruire assez bien la trajectoire.
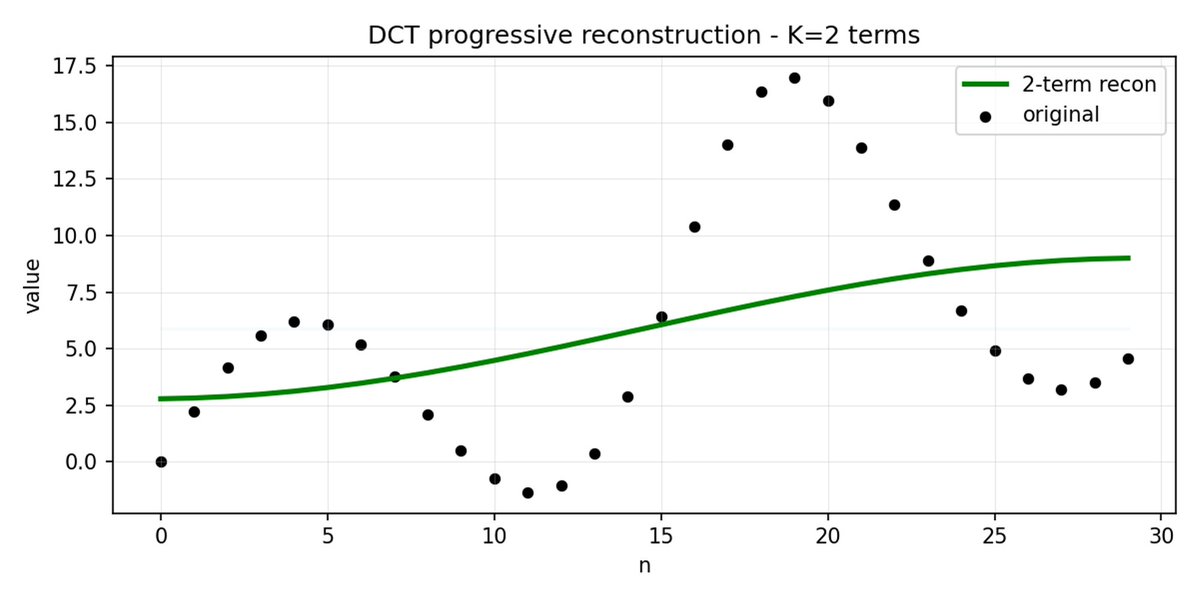
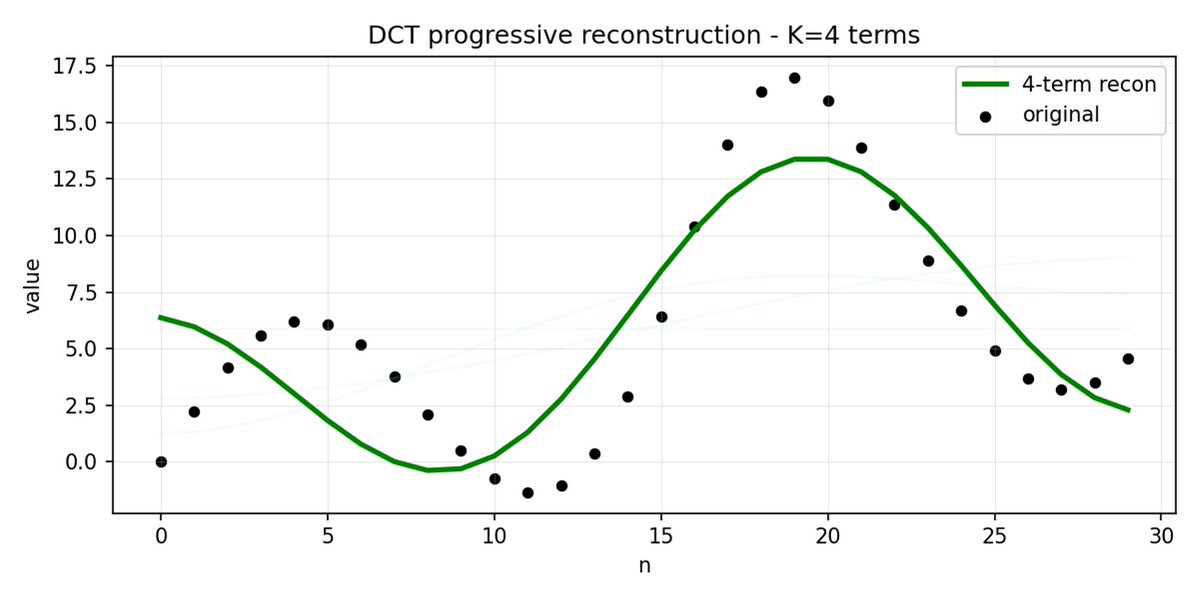
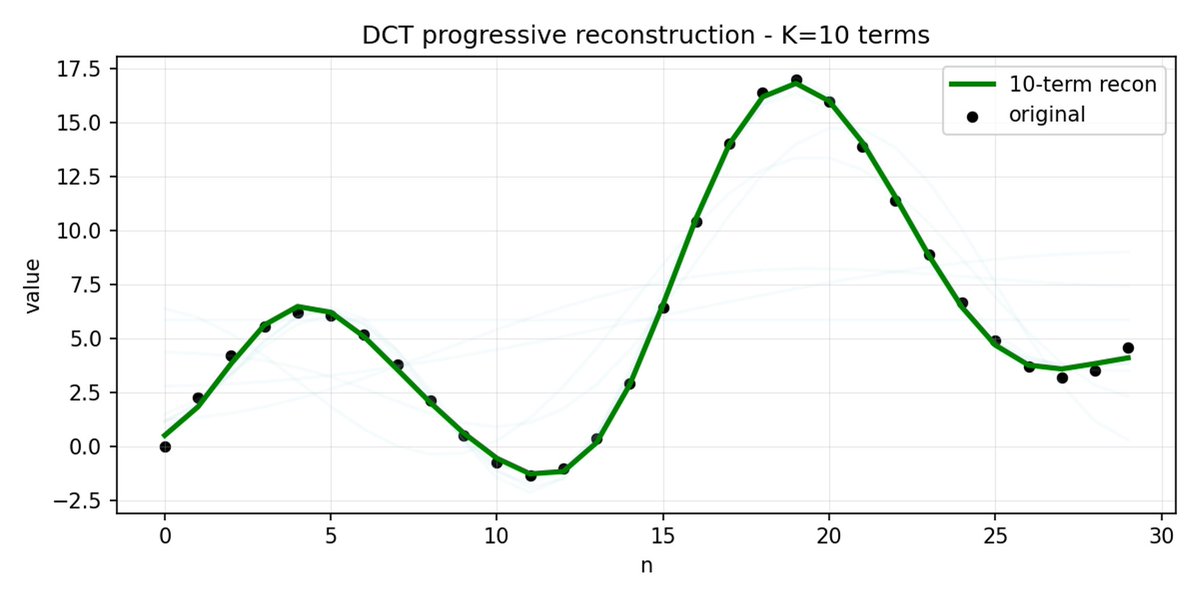
L'encodage par paires d'octets (BPE) est l'approche de tokenisation la plus populaire utilisée dans les LLM. Il recherche les paires de jetons les plus fréquentes et les fusionne en jetons uniques. Lorsqu'elle est appliquée en plus de la DCT quantifiée, de nombreux coefficients nuls des composantes à haute fréquence, ainsi que les mouvements combinés courants de différentes articulations, sont fusionnés en jetons uniques, ce qui conduit à une forte compression.
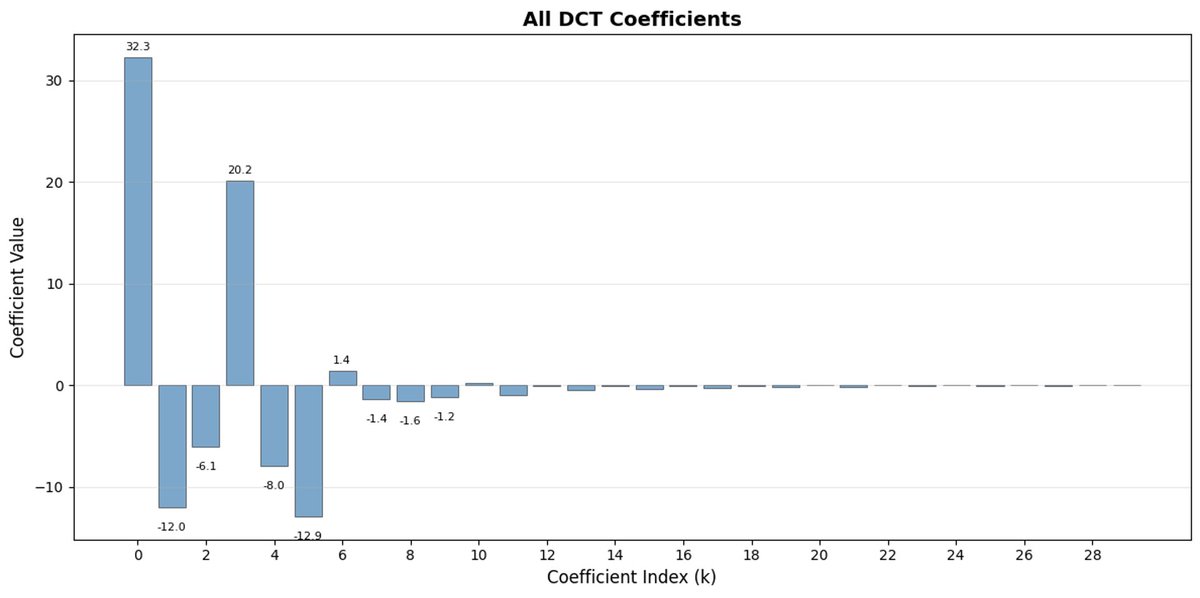
FAST peut mal compresser si vos actions présentent du bruit à haute fréquence (comme des artefacts de normalisation par pas de temps), si les coefficients cessent d'être proches de zéro et si la compression se dégrade. Les données réelles des robots sont généralement lisses, donc tout ira bien dans la plupart des cas ; il faut simplement faire attention au prétraitement des données.
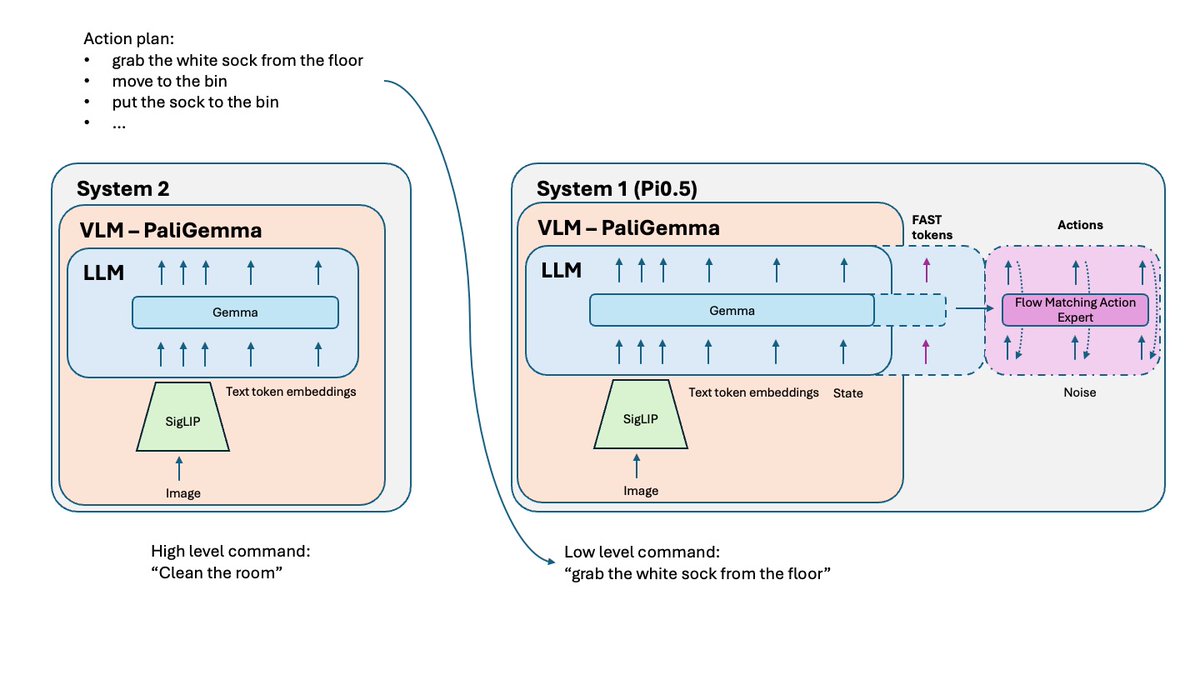
Les politiques VLA, conçues pour des tâches simples, peuvent avoir du mal à les combiner en problèmes complexes à long terme. Pour résoudre ce problème, le système 2, de niveau supérieur, est utilisé. Pi0.5 utilise le même VLM que le système 1 (VLA), mais il est sollicité beaucoup moins fréquemment pour analyser le problème et définir l'étape suivante. Celle-ci est ensuite transmise au système 1 pour exécution.
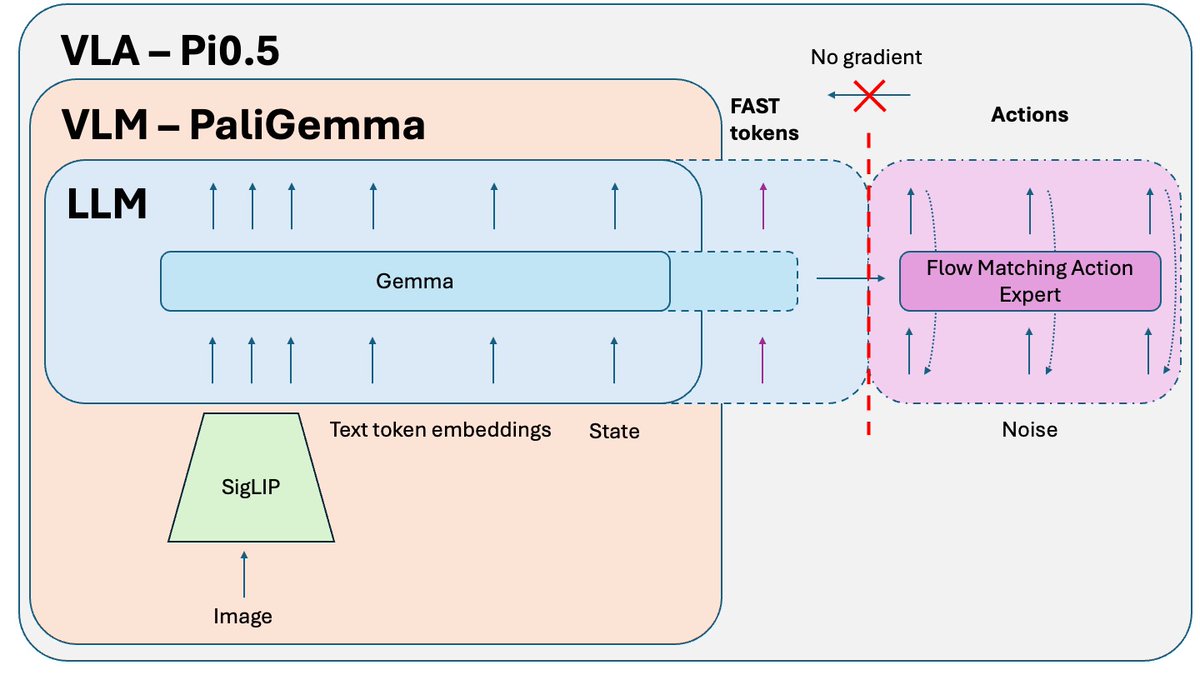
Une astuce supplémentaire, publiée après l'article Pi0.5 mais utilisée pour entraîner la version open source du modèle, est l'isolation des connaissances. Lorsqu'on entraîne conjointement la partie VLM (pré-entraînée sur des données à l'échelle d'Internet) et l'expert d'action (initialisé aléatoirement), le gradient bruité de l'expert d'action corrompt le pré-entraînement du VLM. Ce dernier finit tout simplement par oublier ses connaissances pré-entraînées. La solution consiste à isoler le gradient de l'expert en actions et à lui permettre d'influencer uniquement les poids de l'expert en actions, tandis que le VLM est entraîné sur des jetons d'action FAST + des données non liées à l'action pertinentes.
Un autre problème rencontré lors de l'inférence est le mouvement non fluide dû au découpage en blocs. Le modèle prédit le prochain segment, l'exécute, puis fait une pause pour prédire le suivant (vidéo ci-dessous, vitesse x3). Si vous essayez de prédire un segment de données avant que le précédent ne soit exécuté, cela peut entraîner des erreurs fatales si le modèle passe à un nouveau mode d'action pendant l'exécution d'un mode très différent. La solution consiste à utiliser le remplissage (inpainting), une technique souvent employée en génération d'images. On peut prédire le segment suivant pendant l'exécution du précédent, mais on force cette nouvelle prédiction à correspondre exactement à la fin du segment précédent. Le résultat est un mouvement beaucoup plus fluide, sans à-coups ni pauses, et des performances et un débit du modèle supérieurs.
Pour une analyse approfondie (avec visuels, démonstration et instructions de réglage), regardez ma nouvelyoutu.be/QgGhK1LaUe8/TDdhedJiDn