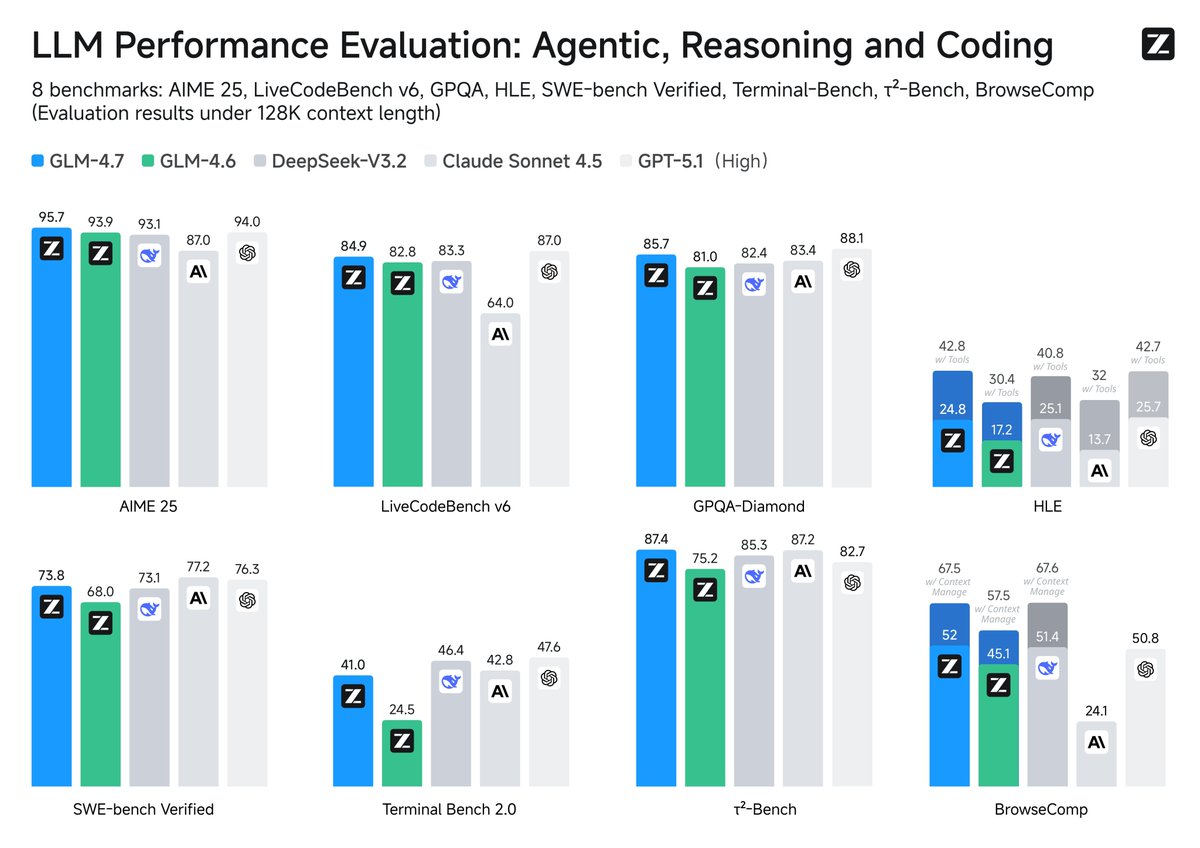
Zhipu vient de publier en open source son dernier modèle : GLM-4.7, dont les capacités d’outillage surpassent celles de Claude Sonnet 4.5. Il a obtenu un score de 67,5 à l'évaluation des tâches Web BrowseComp et de 87,4 à l'évaluation des appels d'outils interactifs τ²-Bench, surpassant Claude Sonnet de 4,5. Il a atteint 42,8 % en HLE, une amélioration de 41 % par rapport à GLM-4.6 et surpassant GPT-5.1. Super GPT-5.2 dans Code Arena Les capacités de GLM-4.7 se manifestent à trois niveaux : programmation, raisonnement et agents intelligents. En termes de compétences en programmation, y compris front-end/back-end et respect des instructions, les performances se sont nettement améliorées par rapport à 4,6 lors d'un test à l'aveugle de 100 tâches dans un projet réel. Il améliore également les performances en programmation multilingue et dans les agents intelligents embarqués, permettant de « réfléchir avant d'agir » au sein de frameworks de programmation tels que Claude Code. La planification à long terme des tâches et la stabilité des appels d'outils permettent une réflexion implicite et optimisée. Les exigences complexes sont automatiquement décomposées en étapes, et les recherches, terminaux, systèmes de fichiers et navigateurs sont lancés. Les erreurs sont gérées par la fonction de restauration. Le système obtient un score de 87,4 sur τ²-Bench, ce qui signifie que les chaînes d'outils à étapes multiples plantent rarement. Le module Skills a été lancé en mode de développement full-stack z ai pour prendre en charge la planification unifiée des tâches multimodales. #ZhipuGLM47
GitHub github.com/zai-org/GLM-4.5JV Visage câlhuggingface.co/zai-org/GLM-4.7qU4ij modelscope.cn/models/ZhipuAI…s://t.co/ELPQoNUXbc