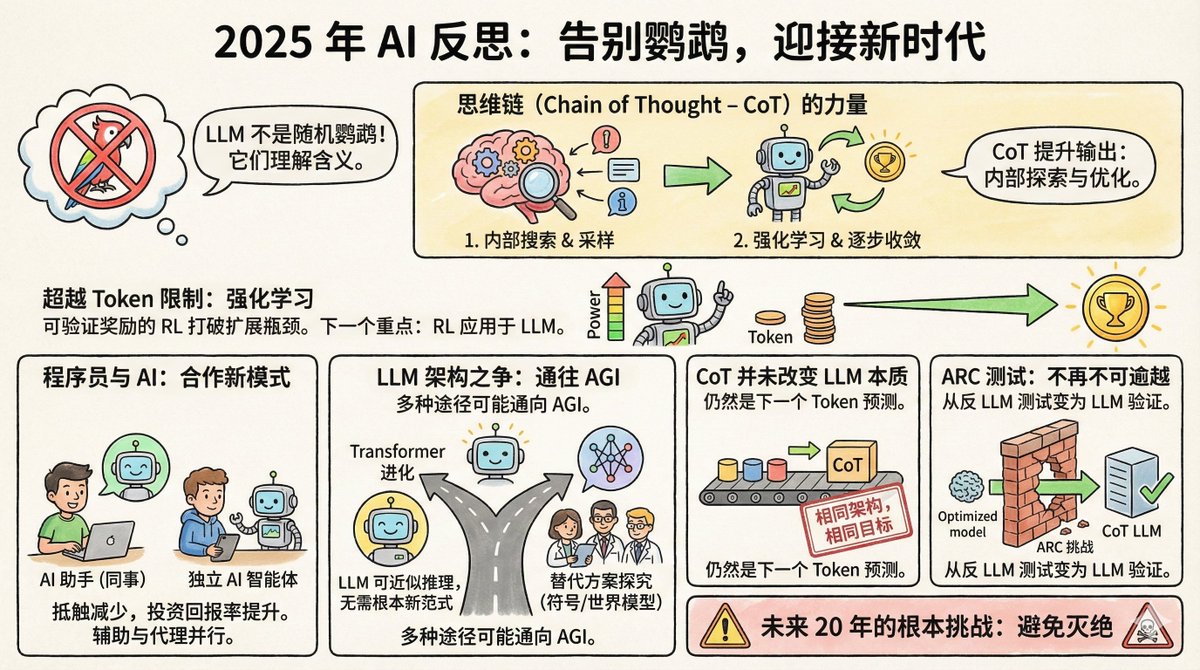
Salvatore Sanfilippo, le créateur de Redis, a récemment publié une réflexion de fin d'année sur l'IA, soulignant huit points clés. Tout d'abord, un peu de contexte : Salvatore n'est pas un spécialiste de l'IA ; c'est une légende du monde de la programmation. En 2009, il a créé Redis, une base de données devenue l'un des systèmes de cache les plus populaires au monde. Il a quitté Redis en 2020 pour se consacrer à ses propres projets. Il est revenu à Redis fin 2024, tout en devenant un utilisateur intensif d'outils d'IA ; Claude est son partenaire de développement. Cette identité est assez intéressante : il est à la fois un expert en technologie et un utilisateur ordinaire d'IA, ce qui lui confère une perspective plus terre-à-terre que les chercheurs en IA pure. Premièrement, l'affirmation concernant les perroquets aléatoires est enfin remise en question. En 2021, Timnit Gebru, chercheur chez Google, et d'autres ont publié un article surnommant les grands modèles de langage « perroquets aléatoires ». Cela signifie que ces modèles assemblent simplement des mots de manière probabiliste, sans comprendre le sens de la question ni savoir ce qu'ils disent. L'analogie est frappante et largement utilisée. Mais Salvatore affirme que d'ici 2025, presque plus personne ne l'utilisera. Pourquoi ? Parce que les preuves sont trop nombreuses. Les modèles LLM surpassent la grande majorité des humains aux examens du barreau, aux examens médicaux et aux concours de mathématiques. Plus important encore, les chercheurs, grâce à la rétro-ingénierie de ces modèles, ont découvert qu'ils contiennent bel et bien des représentations internes de concepts, et non de simples assemblages de mots. Geoffrey Hinton l'a exprimé sans ambages : pour prédire avec précision le mot suivant, il faut comprendre la phrase. La compréhension ne remplace pas la prédiction, mais elle en est une condition nécessaire pour faire de bonnes prédictions. Bien sûr, la question de savoir si LLM le comprend vraiment fait l'objet d'un débat philosophique. Mais en pratique, ce débat est clos. II. La chaîne mentale est une avancée sous-estimée Le processus de réflexion consiste à faire consigner par écrit le raisonnement du modèle avant de répondre. Cela paraît simple, mais le mécanisme sous-jacent est en réalité assez complexe. Salvatore pense que cela a fait deux choses : Premièrement, cela permet au modèle d'explorer ses représentations internes avant de répondre. Autrement dit, il récupère les concepts et informations pertinents dans le contexte de la question, puis répond en fonction de ces informations. C'est un peu comme si quelqu'un prenait des notes sur son examen au préalable. Deuxièmement, grâce à l'apprentissage par renforcement, le modèle apprend à guider son raisonnement étape par étape vers la bonne réponse. La sortie de chaque jeton modifie l'état du modèle, et l'apprentissage par renforcement l'aide à trouver le chemin qui converge vers la bonne réponse. Il n'y a rien de mystérieux, mais les effets sont étonnants. Troisièmement, le goulot d'étranglement de l'expansion de la puissance de calcul a été levé. Il existait autrefois un consensus au sein de la communauté de l'IA : l'amélioration des capacités des modèles dépend de la quantité de données d'entraînement, mais la quantité de texte produite par les humains est limitée, de sorte que l'expansion finira par se heurter à un mur. Mais aujourd'hui, grâce à l'apprentissage par renforcement qui offre des récompenses vérifiables, les choses ont changé. Que sont les récompenses vérifiables ? Pour certaines tâches, comme l’optimisation de la vitesse d’exécution d’un programme ou la démonstration de théorèmes mathématiques, le modèle peut juger lui-même la qualité des résultats. Un programme plus rapide est préférable, et une démonstration correcte est correcte ; aucune annotation humaine n’est nécessaire. Cela signifie que le modèle peut s'améliorer continuellement sur ce type de tâches, générant une quantité quasi infinie de signaux d'entraînement. Salvatore pense que ce sera la voie de la prochaine grande avancée en intelligence artificielle. Vous souvenez-vous du 37e coup d'AlphaGo ? Personne ne l'avait compris à l'époque, mais il a été prouvé par la suite qu'il s'agissait d'un coup divin. Salvatore pense que LLM pourrait suivre une voie similaire dans certains domaines. IV. L'attitude des programmeurs a changé. Il y a un an, la communauté des programmeurs était divisée en deux camps : les uns considéraient la programmation assistée par l’IA comme une arme magique, les autres comme un simple gadget. Aujourd’hui, les sceptiques ont largement changé d’avis. La raison est simple : le retour sur investissement a dépassé un seuil critique. Le modèle peut certes commettre des erreurs, mais le gain de temps qu’il permet compense largement le coût de leur correction. Il est intéressant de constater que les approches des programmeurs vis-à-vis de l'IA se répartissent en deux catégories : la première considère LLM comme un « collègue », l'utilisant principalement via des interfaces conversationnelles web. Salvatore lui-même appartient à cette catégorie et utilise des versions web comme Gemini et Claude pour collaborer comme s'il discutait avec une personne compétente. Une autre école de pensée considère LLM comme une « intelligence de codage indépendante et autonome », lui permettant d'écrire du code, d'exécuter des tests et de corriger les bogues par elle-même, tandis que les humains sont principalement responsables de la révision. Ces deux usages reposent sur des philosophies différentes : faut-il considérer l’IA comme un assistant ou comme un exécutant ? V. Le Transformer pourrait être la solution. Certains éminents scientifiques spécialisés en IA ont commencé à explorer des architectures autres que Transformer, en créant des entreprises pour étudier des représentations symboliques explicites ou des modèles du monde. Salvatore adopte une position ouverte mais prudente sur ce sujet. Il estime que le LLM est essentiellement une approximation du raisonnement discret dans un espace différentiable, et qu'il est possible d'atteindre l'AGI sans un paradigme fondamentalement nouveau. De plus, l'AGI peut être implémentée indépendamment à travers diverses architectures totalement différentes. En d'autres termes, tous les chemins mènent à Rome. Le Transformer n'est peut-être pas le seul chemin, mais ce n'est pas forcément une impasse non plus. VI. La chaîne de mentalité ne change pas l'essence du LLM. Certains ont revu leur position. Ils disaient autrefois que LLM n'était qu'un perroquet qui répète sans cesse les mêmes choses, mais reconnaissent désormais que LLM en a le pouvoir. Cependant, ils affirment aussi que la chaîne mentale modifie fondamentalement la nature de LLM, de sorte que les critiques précédentes restent valables. Salvatore a déclaré sans ambages : Ils mentent. L'architecture reste la même ; il s'agit toujours d'un Transformer. L'objectif de l'entraînement demeure inchangé : prédire le jeton suivant. Le contenu de type « CoT » est également généré jeton par jeton, comme pour tout autre contenu. On ne peut pas prétendre que le modèle « est devenu autre chose » simplement parce qu'il est devenu plus puissant, afin de justifier un jugement erroné. C'est une affirmation plutôt abrupte, mais elle est logique. Les jugements scientifiques doivent reposer sur des mécanismes, et les définitions ne doivent pas être modifiées simplement parce que le résultat a changé. Un autre exemple qui illustre bien ce point est le test ARC. VII. Les tests ARC sont passés d'une position anti-LLM à une position favorable aux LLM. ARC est un test conçu par François Chollet en 2019 spécifiquement pour mesurer les capacités de raisonnement abstrait. Sa conception vise à résister à la récupération de la mémoire et aux recherches par force brute, exigeant un véritable raisonnement pour être résolu. À l'époque, beaucoup pensaient que le modèle LLM ne réussirait jamais ce test. En effet, il exige la capacité de généraliser des règles à partir d'un nombre très restreint d'exemples et de les appliquer à de nouvelles situations, ce que le perroquet aléatoire est précisément incapable de faire. Résultat ? Fin 2024, le modèle o3 d’OpenAI a atteint une précision de 75,7 % sur ARC-AGI-1. En 2025, même sur le plus difficile ARC-AGI-2, les meilleurs modèles ont atteint une précision supérieure à 50 %. Ce renversement de situation est assez ironique. Le test, conçu initialement pour prouver l'inefficacité de la LLM, est devenu paradoxalement la preuve de son efficacité. VIII. Défis fondamentaux pour les 20 prochaines années Le dernier point tient en une seule phrase : le défi fondamental de l’IA au cours des 20 prochaines années est d’éviter son extinction. Il n'a pas donné plus de détails, juste cette phrase. Mais vous comprenez ce qu'il veut dire. Lorsque l'IA sera suffisamment puissante, la question de savoir « comment éviter qu'elle ne cause de problèmes majeurs » ne relèvera plus de la science-fiction. Salvatore n'est ni un fervent défenseur de l'IA, ni un sceptique convaincu. Il maîtrise cette technologie et l'utilise concrètement. Son point de vue n'est ni purement théorique, ni purement commercial, mais plutôt l'observation sereine d'un ingénieur chevronné. Son principal constat est que les modèles linéaires à longue portée (LLM) sont bien plus puissants que beaucoup ne sont prêts à l'admettre, que l'apprentissage par renforcement ouvre de nouvelles possibilités et que notre compréhension de ces systèmes est encore loin d'être complète. Voici probablement le véritable état du développement de l'IA en 2025 : les capacités s'accélèrent, les controverses diminuent, mais l'incertitude demeure énorme.