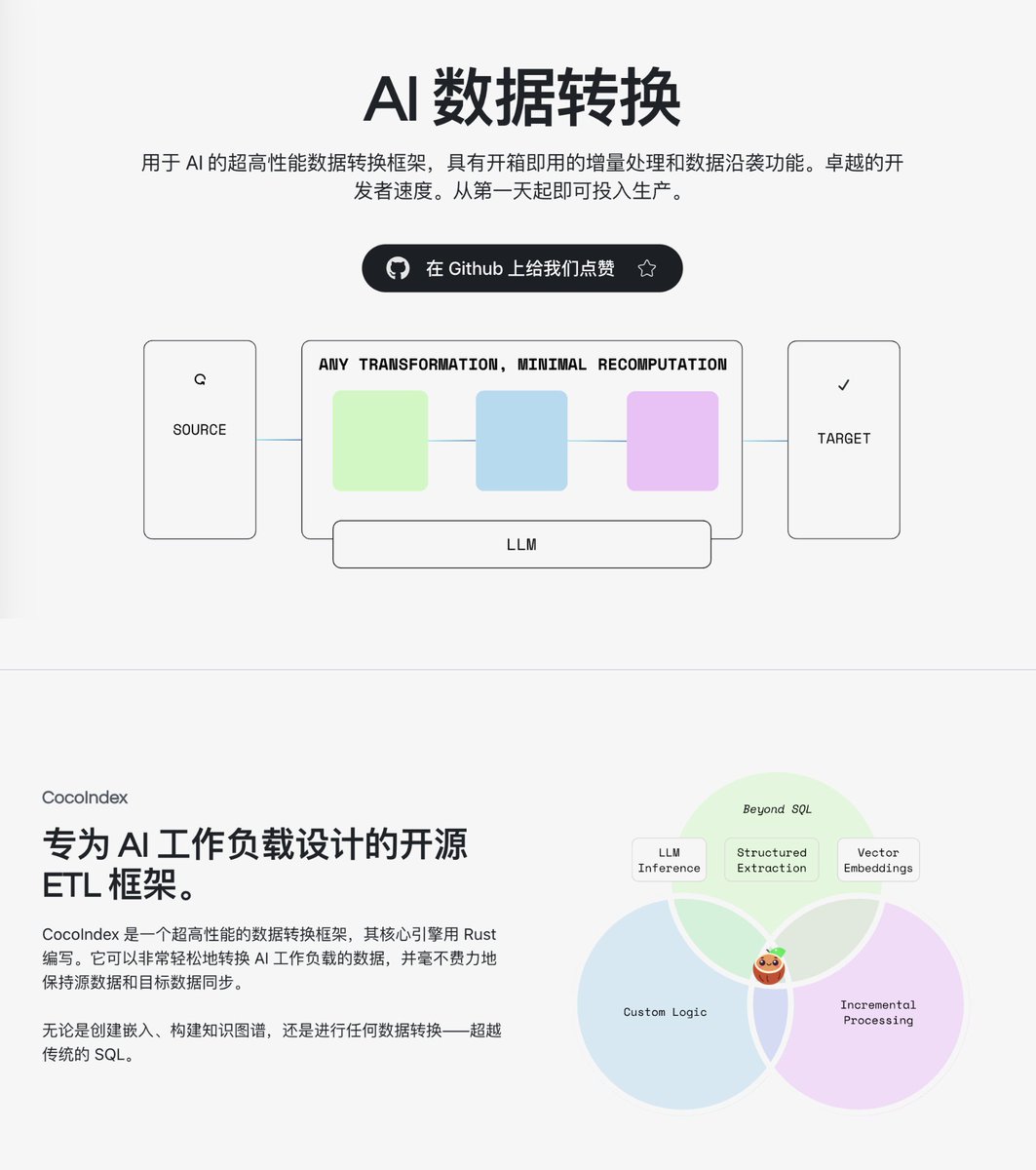
Lors du développement d'applications RAG ou de la construction de bases de connaissances, la partie la plus problématique n'est souvent pas la sélection du modèle, mais le pipeline de traitement des données. Cela nécessite l'écriture de nombreux scripts Python pour nettoyer, découper et vectoriser les données, et si les données sources changent, relancer l'ensemble du processus est à la fois long et coûteux. J'ai récemment découvert le projet open-source CocoIndex sur GitHub, un framework de transformation de données haute performance conçu spécifiquement pour les scénarios d'IA. Avec seulement une centaine de lignes de code Python, vous pouvez définir l'ensemble du processus, de la lecture et du découpage des fichiers à l'insertion du vecteur dans la bibliothèque. GitHub : https://t.co/RwUjyHJEym Il prend en charge diverses sources et cibles de données, notamment les fichiers locaux, Amazon S3, Google Drive et les bases de données vectorielles telles que Postgres, Qdrant et LanceDB. En outre, il comprend également des composants de conversion couramment utilisés tels que la segmentation de texte, la génération d'embeddings, l'analyse de PDF et la construction de graphes de connaissances. Il fournit une multitude d'exemples couvrant plus de 20 scénarios d'application pratiques, notamment la recherche sémantique, les graphes de connaissances, la recommandation de produits et la recherche d'images, qui peuvent être directement consultés et utilisés.