Renaître de l'échec : une rétrospective concrète sur le déploiement d'un agent d'IA frontend Aujourd'hui, lors de FEDay, j'ai présenté une étude de cas sur la mise en œuvre d'un agent frontal. Loin de célébrer une victoire, il s'agissait de raconter comment une équipe est passée du succès technique à l'échec produit, et comment cet échec a conduit à une refonte cruciale de notre cadre de réflexion. L'intérêt de ce récit ne réside pas dans une méthodologie pour réussir, mais dans les pièges que nous avons rencontrés et l'évolution de notre réflexion.

L’année 2025 est présentée comme « l’année de l’agent ». Avec la sortie de Deep Research, Manus et Claude Code, la communauté tech est en ébullition. De nombreuses équipes se posent la même question : « Devrions-nous créer un agent ? »

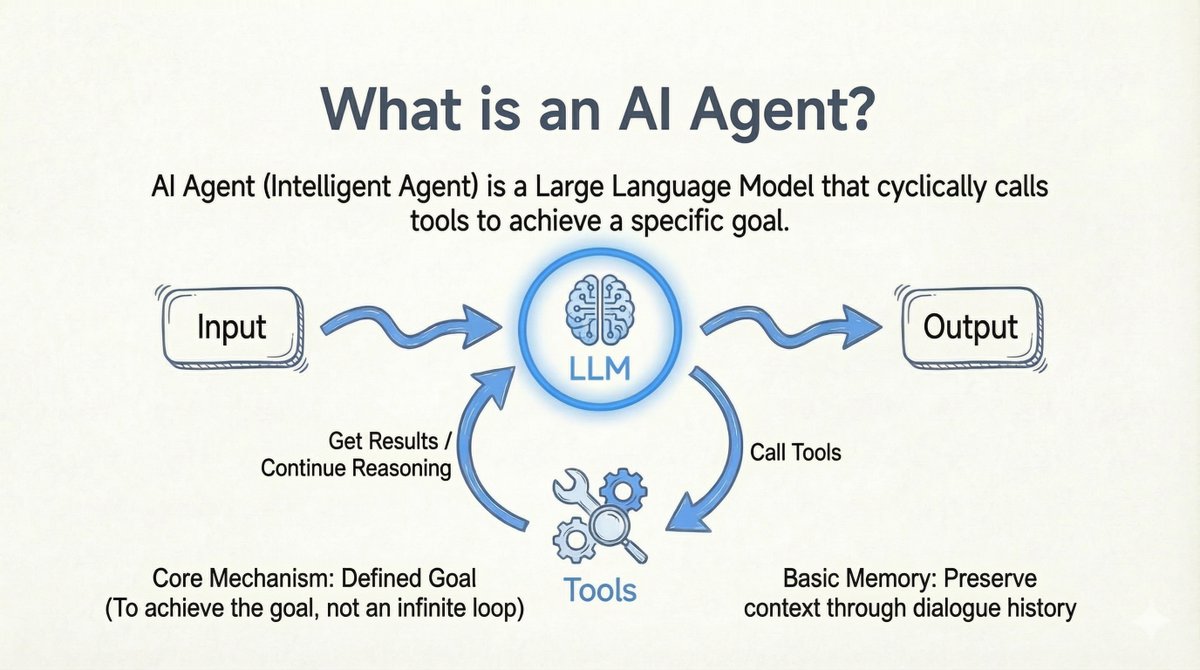
Avant d'entrer dans le vif du sujet, permettez-moi de préciser ma définition d'un agent IA : > Agent IA : Un modèle de langage étendu (LLM) qui parcourt les appels d'outils pour atteindre un objectif spécifique. - Outils en boucle : le modèle appelle l'outil -> obtient le résultat -> poursuit le raisonnement. - Point de terminaison clair : il sert à atteindre un objectif, et non à boucler indéfiniment. - Source d'objectif flexible : l'objectif peut provenir d'un utilisateur ou d'un autre LLM. - Mémoire de base : Conserve le contexte grâce à l'historique des conversations.
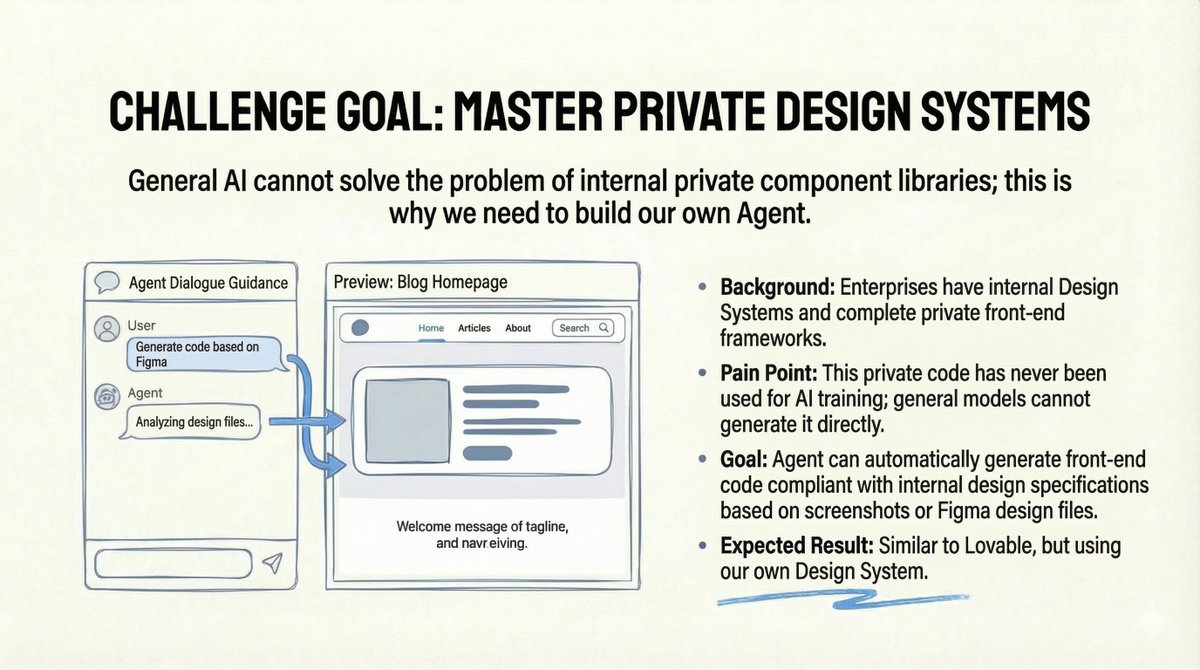
Le défi : les systèmes de conception privés L'équipe d'un ami rencontrait un véritable problème d'entreprise : la société disposait d'un système de conception interne complet et d'un framework frontend privé. Or, ce code étant privé, aucun modèle d'IA public n'avait jamais été entraîné dessus. De ce fait, les modèles généralistes étaient incapables de générer du code conforme à leurs spécifications internes. L’objectif semblait clair : créer un outil similaire à Lovable, mais basé sur leur propre système de conception. Les utilisateurs téléchargeraient une maquette Figma ou une capture d’écran, et l’agent générerait automatiquement le code frontend conforme aux normes internes. Ça a l'air parfait, non ?
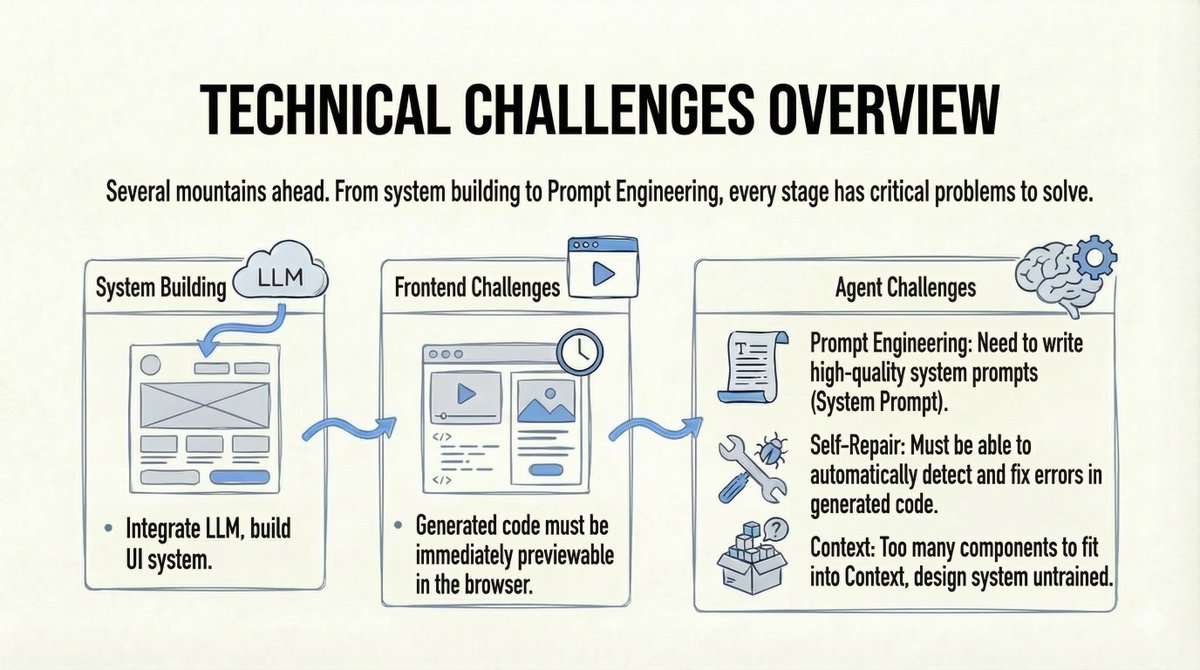
Le constat de la réalité : les défis étaient considérables : 1. La construction d'un système d'agents complet est plus difficile qu'il n'y paraît (interaction utilisateur, ingénierie du contexte, etc.). 2. Le modèle doit comprendre et utiliser des composants privés qu'il n'a jamais vus. 3. Nous avions besoin d'aperçus en temps réel du code généré dans le navigateur. 4. Nous avions besoin de capacités d'auto-réparation en cas de défaillance du code.
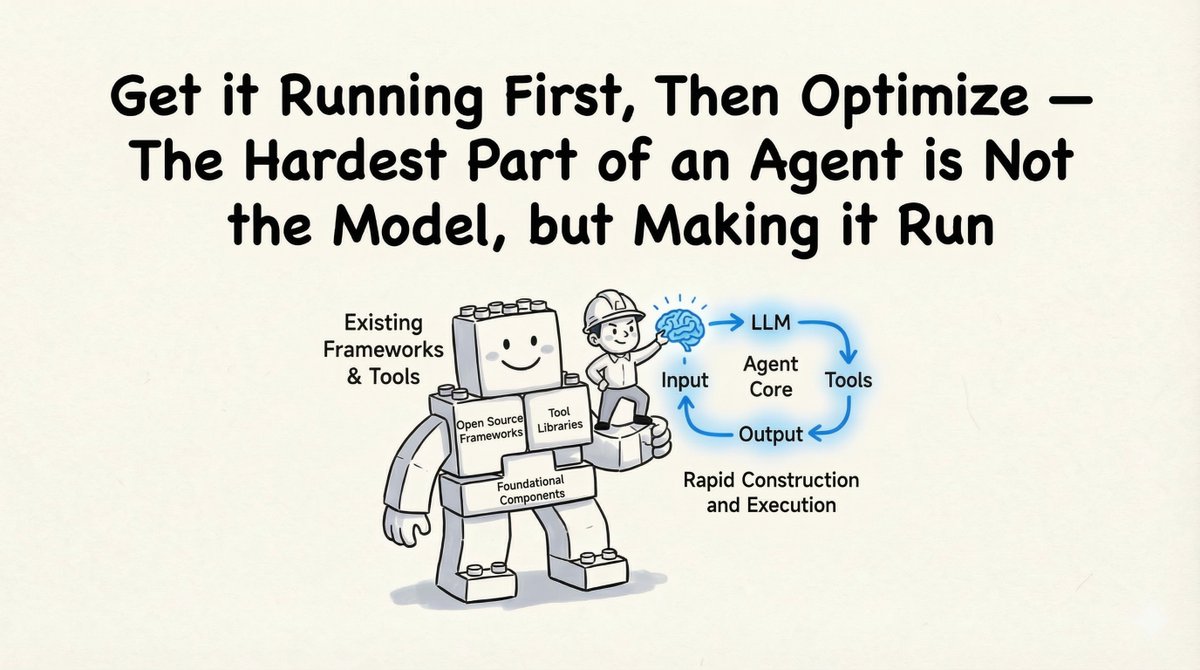
Le « succès technique » : comment nous l'avons bâti En tant que consultant technique, mon premier conseil était pragmatique : « Faites-le fonctionner avant de l’optimiser. » La création de l’agent n’est pas la partie la plus difficile ; c’est l’exécution complète du cycle qui l’est.
1. La Fondation : Kit de développement logiciel (SDK) de l'agent Claude Au lieu de réinventer la roue, nous avons utilisé le kit de développement logiciel (SDK) de l'agent Claude. - Preuve à l'appui : Claude Code a prouvé que cette architecture fonctionne. - Prêt à l'emploi : les outils intégrés couvrent 90 % des scénarios. - Extensible : Prend en charge les outils personnalisés, le protocole MCP (Model Context Protocol) et les compétences personnalisées. (Vous pouvez trouver une partie du code prototype en open source ici : https://t.co/eon1eb3ECD)

2. Solution préliminaire : Système de fichiers local Nous avons d'abord essayé Sandpack (environnement de test basé sur un navigateur) pour la prévisualisation du code, mais cela s'est avéré inefficace avec les composants privés complexes. Solution de contournement : nous avons fourni à l'agent un système de fichiers local (une machine virtuelle ou un répertoire par session). Cela lui a permis de lire, d'écrire, de modifier et de compiler librement le code.
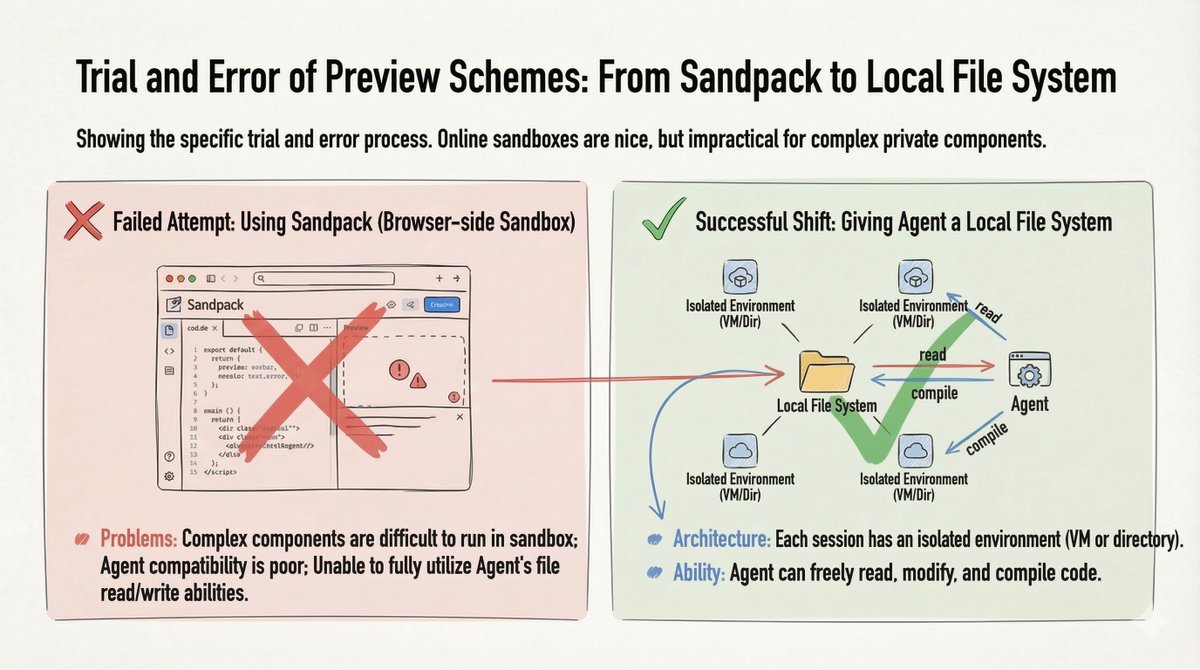
Fournir à l'agent un système de fichiers local est le seul moyen de maximiser ses capacités.

3. Résolution du problème du « composant inconnu » Comment enseigner à une IA à utiliser une bibliothèque de composants qu'elle n'a jamais vue ? Considérez-le comme un nouvel employé. Nous avons converti les spécifications du système de conception, les listes de composants et la documentation de l'API au format Markdown. Aucun RAG complexe n'est nécessaire : nous avons simplement autorisé l'agent à effectuer une récupération de fichiers sur la documentation locale et le « code de référence de haute qualité ».

4. Assurance qualité : La boucle de vérification Pour garantir le bon fonctionnement du code, nous avons mis en place une boucle automatisée : Génération → Vérification → Réparation - Outils : analyse statique du code, vérifications de compilation et comparaison visuelle (à l’aide de Chrome DevTool MCP). - Optimisation : Nous avons placé les outils de vérification dans une compétence ou un sous-agent afin d'éviter de surcharger la fenêtre de contexte de l'agent principal.

L’« échec produit » : le silence après le lancement Le système fonctionnait. La démo était époustouflante. Nous l'avons lancé… et presque personne ne l'a utilisé. Une fois l'effet de nouveauté passé, le taux d'abandon a explosé. Après une analyse approfondie et des entretiens avec les utilisateurs, nous avons réalisé que le problème ne résidait pas dans la technologie, mais dans un décalage entre la logique produit et les habitudes des utilisateurs.
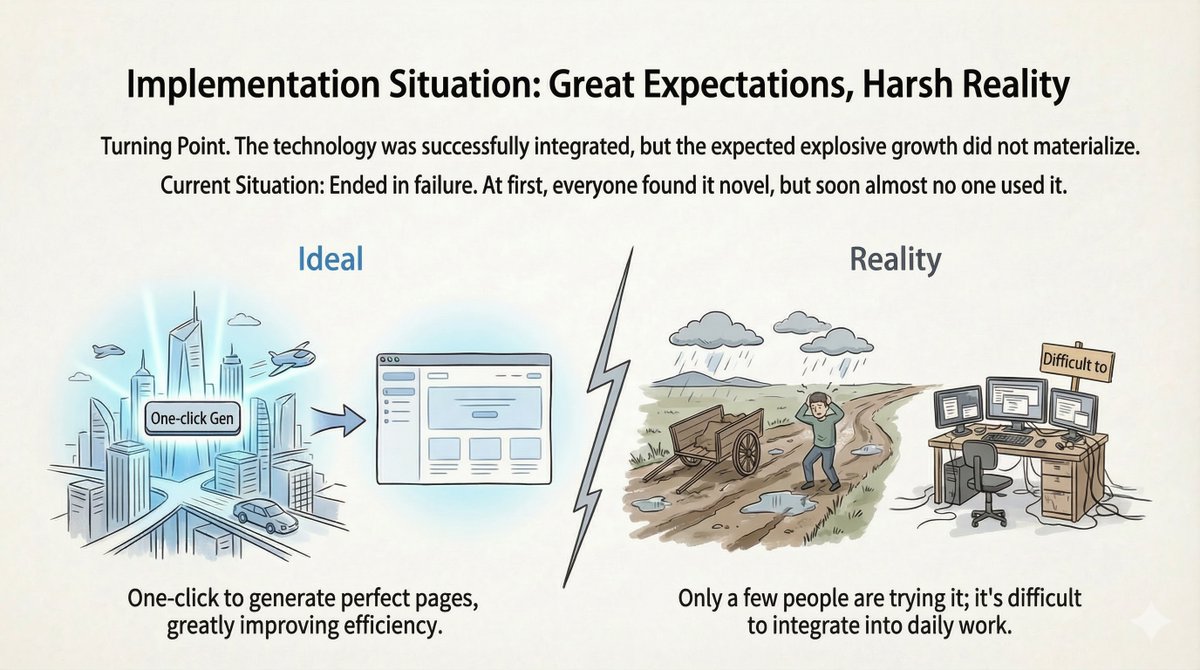
Pourquoi cela a échoué 1. Résistance aux habitudes : Les designers et les chefs de produit travaillent principalement sur Figma, pas dans des fenêtres de chat. Passer de leur zone de confort à une interface conversationnelle a constitué un obstacle majeur. La plupart ne savaient même pas quoi écrire. 2. Le goulot d'étranglement 80/20 : L'agent a parfaitement exécuté 80 % du travail. Cependant, les 20 % restants nécessitaient des modifications manuelles, une tâche extrêmement fastidieuse. Souvent, ces 20 % déterminaient si le code était utilisable. 3. Fragmentation du flux de travail : L’environnement de génération était déconnecté de l’environnement de développement réel. Les développeurs devaient copier-coller manuellement le code, ce qui rendait le processus fastidieux.

La mise à niveau cognitive : recadrer le problème Nous avons réalisé que nous avions posé la mauvaise question : « Comment construire un agent d’IA pour un système de conception ? » Cela a fait de l’agent le but, plutôt que le moyen. La bonne question était : « Quel est le but ultime de notre système de conception ? » 1. Spécifications de conception unifiées à l'échelle de l'entreprise. 2. Amélioration de l'efficacité du développement.

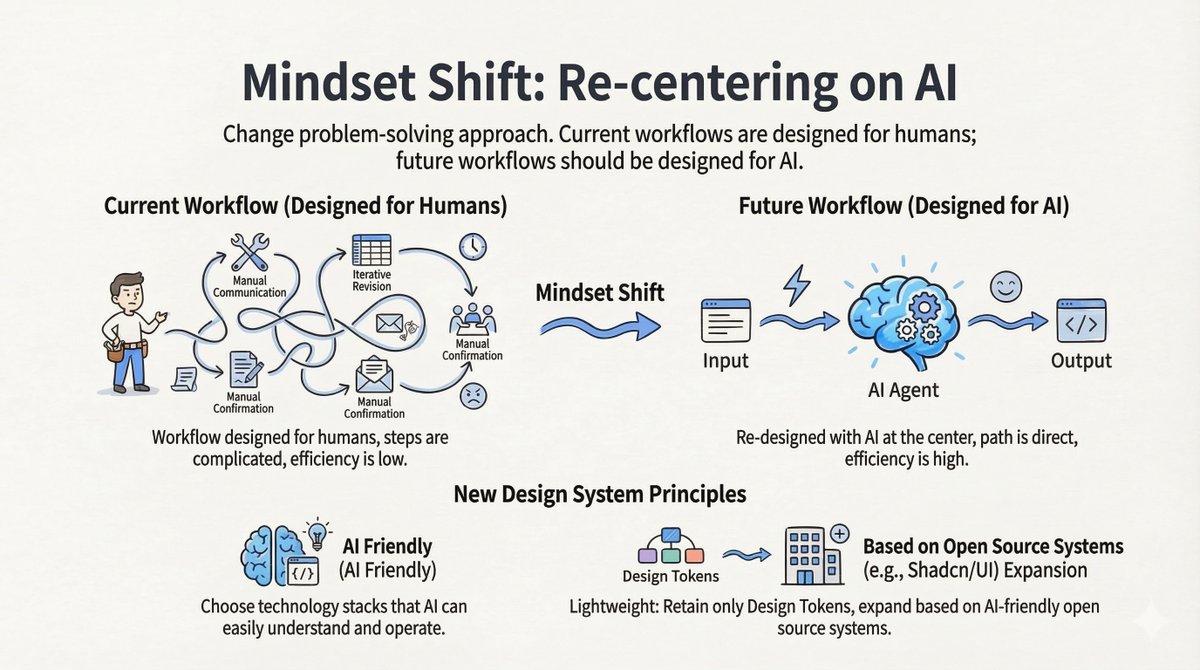
Changement 1 : Concevoir pour l’IA, pas pour les humains Les flux de travail actuels sont centrés sur l'humain : communication manuelle, modification itérative, confirmation manuelle. Les flux de travail futurs doivent être centrés sur l'IA : Entrée -> Agent IA -> Sortie. Nouveaux principes de conception : - Adapté à l'IA : Choisissez des technologies que les titulaires d'un LLM comprennent facilement. - Léger : ne conservez que les jetons de conception. Privilégiez les systèmes open source compatibles avec l’IA (comme shadcn/ui) plutôt que de maintenir une bibliothèque privée massive.
Deuxième étape : De « agent » à « compétence » Le tournant le plus crucial a été l'abandon de la « plateforme d'agents indépendants ». Ancien modèle (Île) : Un agent autonome, isolé du développeur, ce qui engendre des frictions. Nouveau modèle (intégration) : Transformer le système de conception en une compétence pouvant être intégrée dans les environnements de développement d'IA existants (comme Cursor ou Claude Code).

Qu'est-ce qu'une compétence ? Il s'agit simplement de documentation Markdown (que l'IA peut lire) + de scripts d'automatisation (pour initialiser les projets et installer le système). Désormais, un développeur travaille dans son environnement habituel. Lorsqu'il a besoin du système de conception, l'agent générique appelle cette fonctionnalité « compétence », et le code généré est directement intégré au dépôt du projet. (Approche de référence : anthropics/skills/tree/main/skills/web-artifacts-builder)

Analyses approfondies : 4 points clés à retenir 1. Succès technique ≠ succès produit Nombre d'ingénieurs (moi y compris) tombent dans le piège de penser : « Ça marche, donc c'est un succès. » Les utilisateurs se fichent de votre pile technologique ; ce qui compte pour eux, c'est que le produit résolve leur problème sans perturber leur flux de travail. 2. Concevoir des flux de travail « centrés sur l'IA » On parle souvent d'approche « centrée sur l'utilisateur », mais il faut y ajouter une dimension supplémentaire : « centrée sur l'IA ». Il ne s'agit pas de faire en sorte que l'IA imite les processus humains. Il faut repenser ces processus pour que l'IA puisse fonctionner avec une efficacité maximale, puis laisser l'utilisateur profiter du résultat. 3. Compétence > Agent Les plateformes d'agents indépendants rencontrent d'importants obstacles à leur adoption. Intégrer les fonctionnalités sous forme de Skill, qui s'intègre à l'écosystème existant, constitue une approche bien plus pragmatique. 4. Action Même si le produit initial a « échoué », l’amélioration cognitive a été inestimable. On ne peut pas apprendre à passer d’un « flux de travail humain » à un « flux de travail IA » sans se salir les mains.
Construisez-le ! L'échec est acceptable. Il est infiniment préférable à l'inaction.
