Le modèle de Bolmo adopte une approche ingénieuse : au lieu d'un entraînement à partir de zéro, il « encode » le modèle existant. Il intègre un encodeur/décodeur local qui compresse les séquences d'octets en « jetons potentiels » avant de les transmettre à un transformateur classique pour traitement. Ceci permet une conversion avec une surcharge minimale.


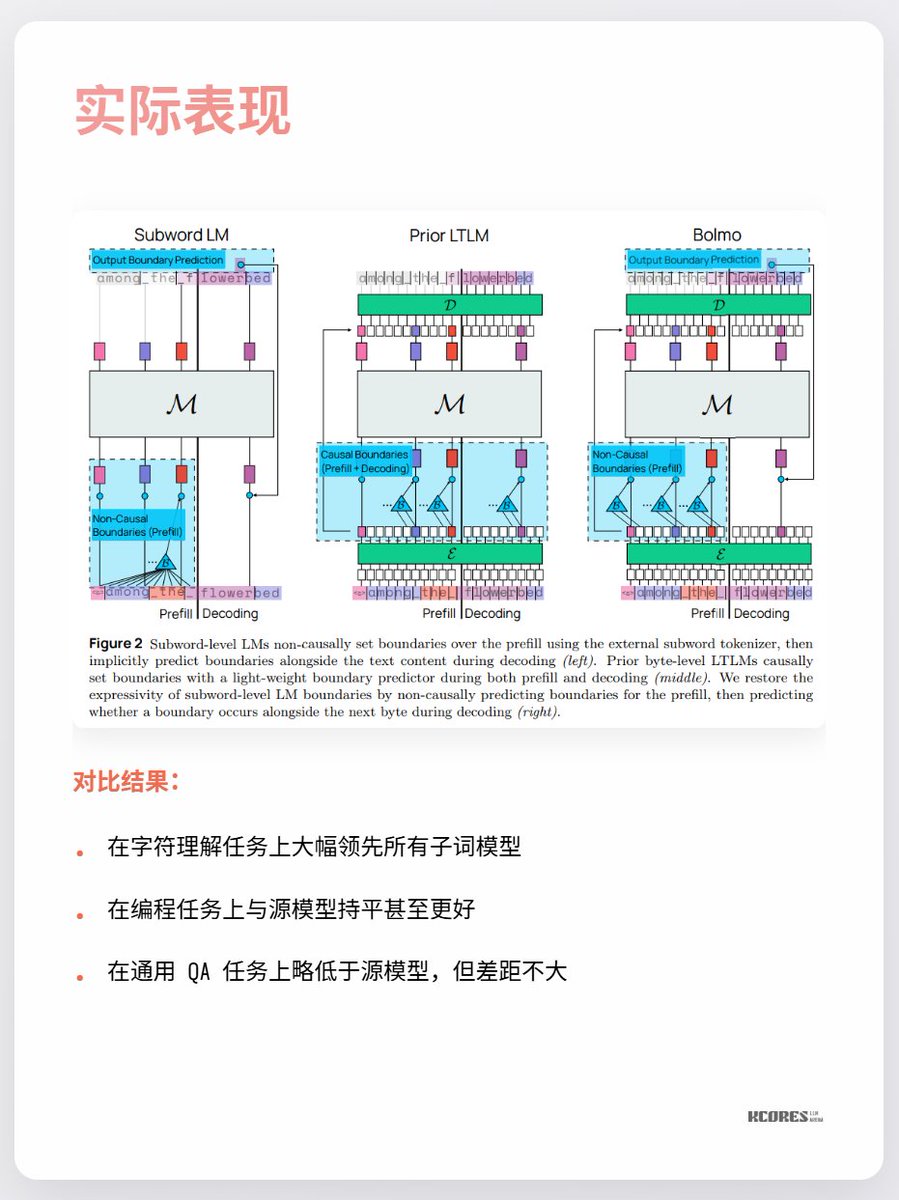
Les principaux points de désaccord actuels portent sur le faible bénéfice observé et sur le fait que des séquences plus longues impliquent un cache clé-valeur plus important, ce qui accroît la pression sur la mémoire du GPU. De plus, l'avantage significatif n'est constaté que pour la tâche de compréhension des caractères, les autres tâches n'apportant que peu d'amélioration notable. En bref, il est intéressant de suivre ce phénomène. L'exploration en spirale qui accompagne les percées technologiques est toujours passionnante. Par exemple, j'appréciais particulièrement les redresseurs à mercure (dernière image), mais ils ont depuis été remplacés par les IGBT.

