Tout le monde sait que les modèles à grande échelle possèdent un tokenizer, qui enregistre les tables de segmentation des mots utilisées par le modèle et constitue l'unité de base pour la compréhension sémantique et les calculs. Mais vous êtes-vous déjà demandé pourquoi la segmentation des mots est nécessaire ? Ne serait-il pas plus simple de saisir directement les tokens en utilisant l'encodage UTF-8 ? Examinons le nouveau modèle actuel, le Bolmo-8B. Ils ont directement abandonné l'approche traditionnelle et ont utilisé à la place les octets UTF-8 comme unité de base, traitant chaque caractère comme une séquence d'octets pour le traitement.
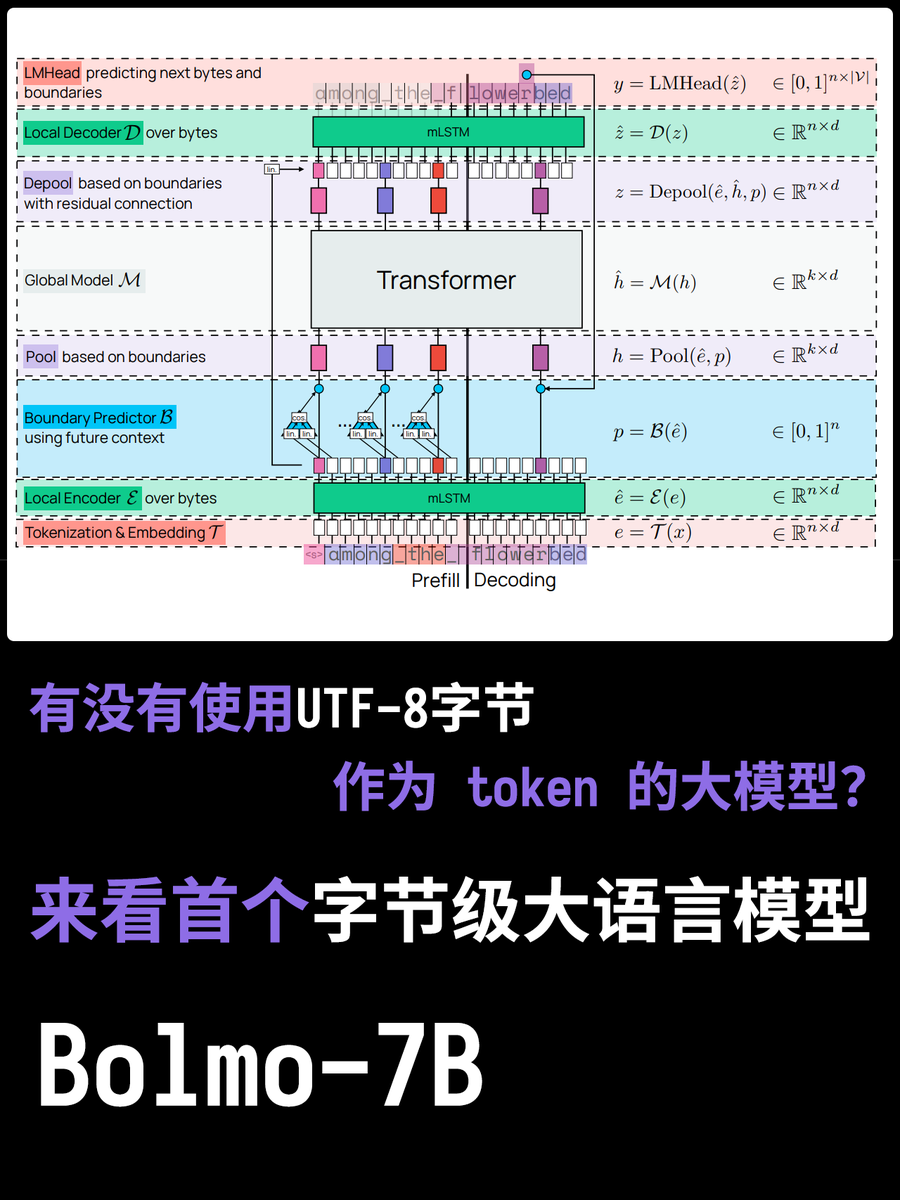
Le principal avantage de cette méthode est qu'elle permet de répondre facilement à des questions comme « Combien de "r" y a-t-il dans le mot "fraises" ? » ! En effet, chaque lettre est encodée indépendamment en UTF-8. Cependant, les problèmes que cela engendre sont bien réels. Un mot peut parfois être très complexe, et parfois très simple. Les analyseurs lexicaux traditionnels parviennent à gérer ce problème dans une certaine mesure, mais avec l'UTF-8, chaque mot doit être segmenté en un jeton de sa longueur, ce qui rend l'allocation des ressources de calcul très rigide.
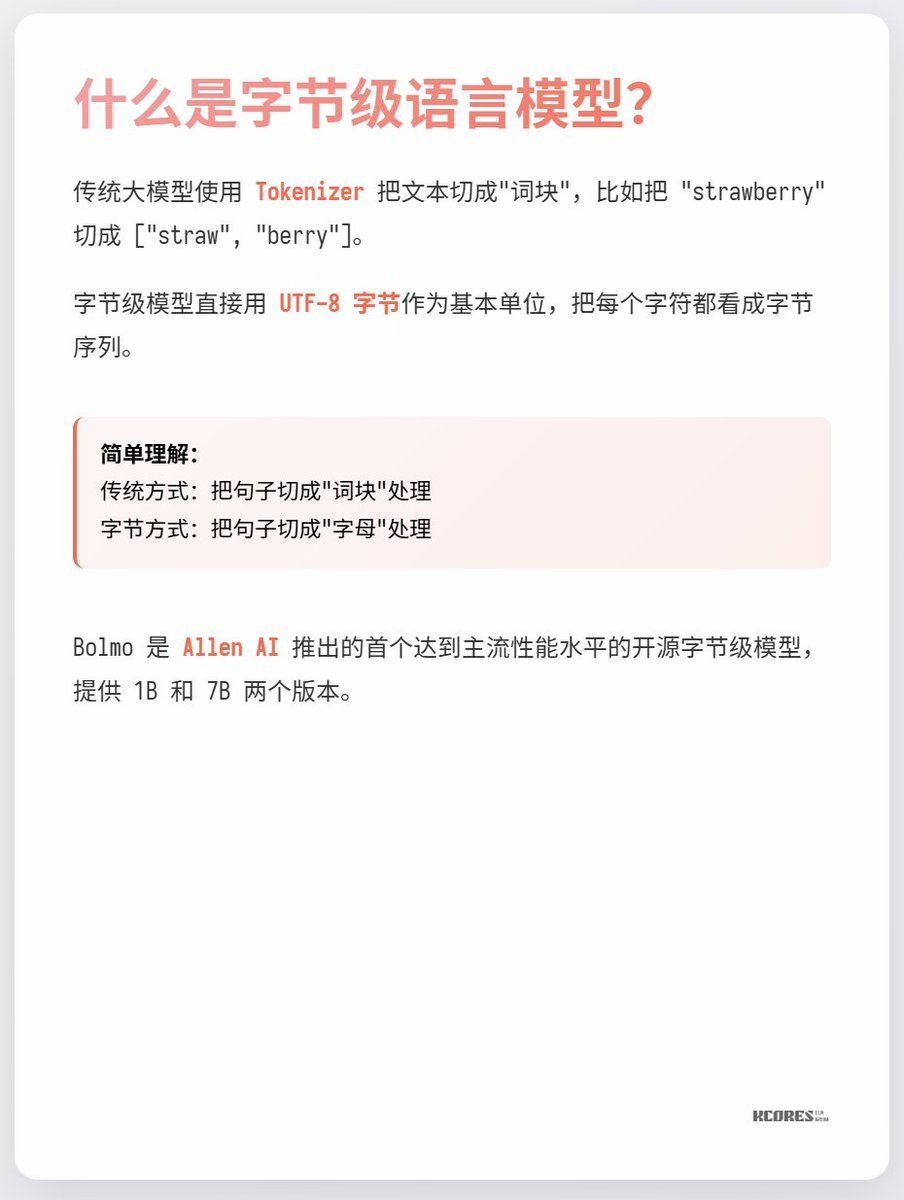



Le modèle de Bolmo adopte une approche ingénieuse : au lieu d'un entraînement à partir de zéro, il « encode » le modèle existant. Il intègre un encodeur/décodeur local qui compresse les séquences d'octets en « jetons potentiels » avant de les transmettre à un transformateur classique pour traitement. Ceci permet une conversion avec une surcharge minimale.

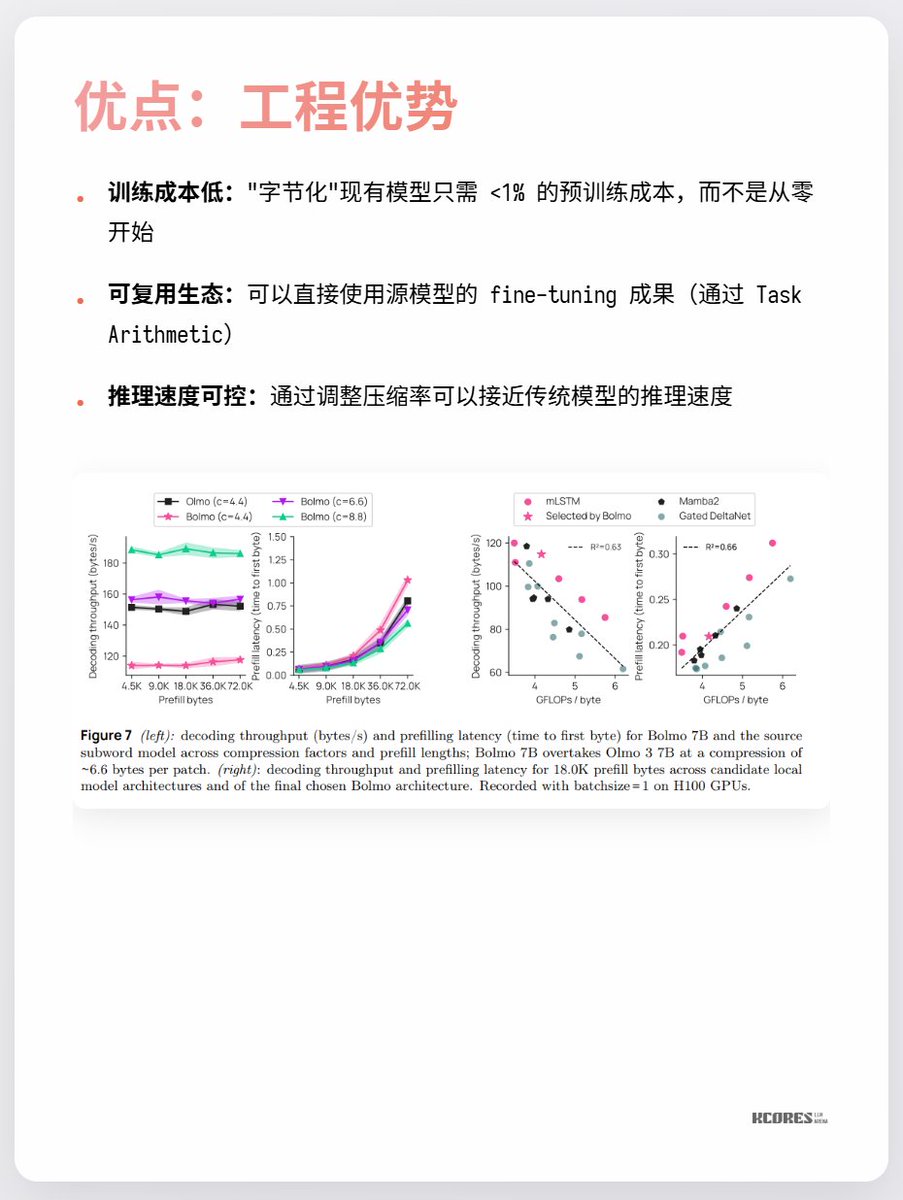

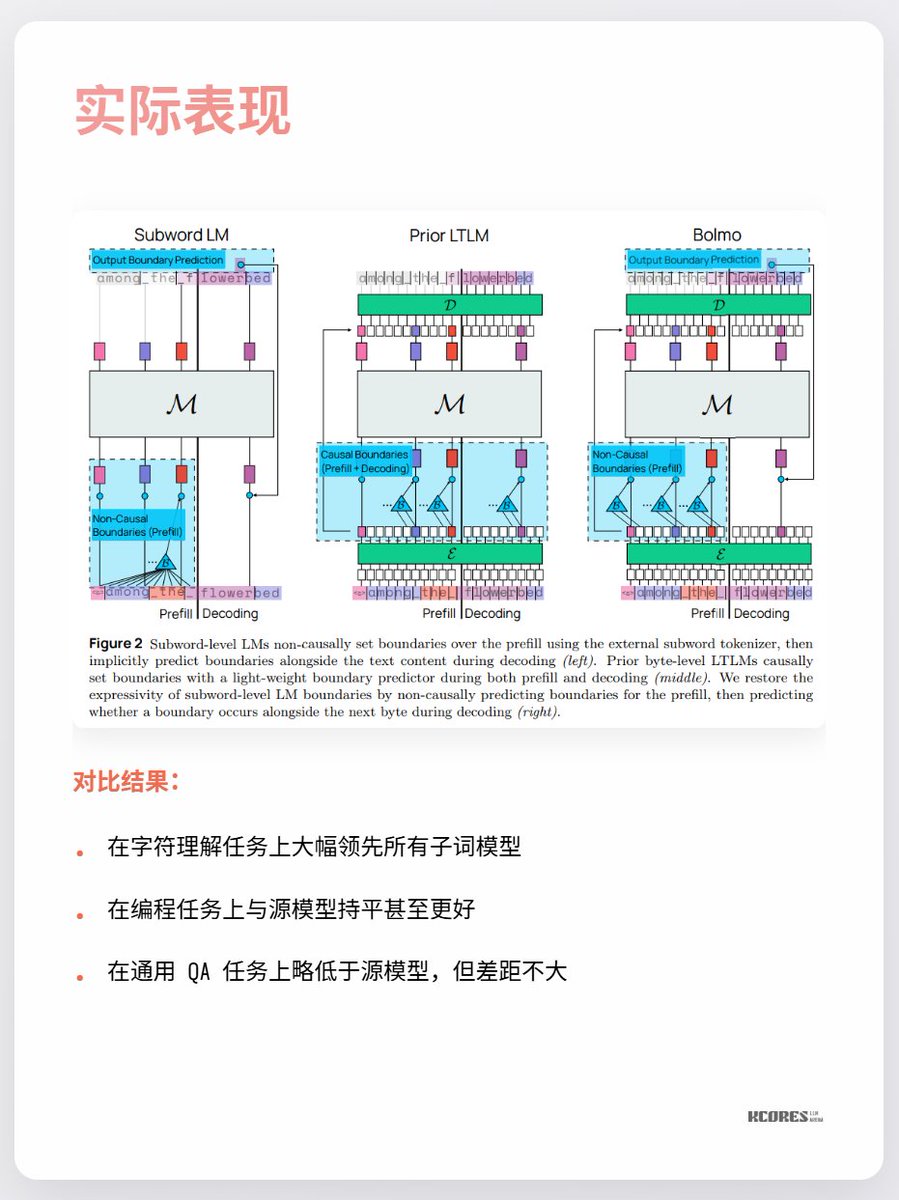
Les principaux points de désaccord actuels portent sur le faible bénéfice observé et sur le fait que des séquences plus longues impliquent un cache clé-valeur plus important, ce qui accroît la pression sur la mémoire du GPU. De plus, l'avantage significatif n'est constaté que pour la tâche de compréhension des caractères, les autres tâches n'apportant que peu d'amélioration notable. En bref, il est intéressant de suivre ce phénomène. L'exploration en spirale qui accompagne les percées technologiques est toujours passionnante. Par exemple, j'appréciais particulièrement les redresseurs à mercure (dernière image), mais ils ont depuis été remplacés par les IGBT.

