NVIDIA vient de publier un modèle accéléré conçu spécifiquement pour le GPT-OSS-120B. NVIDIA vient de publier un nouveau modèle, gpt-oss-120b-Eagle3-throughput, spécialement conçu pour fonctionner avec gpt-oss-120b. Il peut être utilisé comme pré-modèle pour le décodage spéculatif de gpt-oss-120b, améliorant ainsi la vitesse de sortie de ce dernier. Pour ceux qui ne connaissent pas le décodage spéculatif, il consiste à utiliser un petit modèle pour générer des données, puis à traiter ces données par lots avec un modèle plus important pour correction. Ainsi, si le petit modèle « devine correctement », le traitement est très rapide. De plus, dans les contextes courants, on trouve encore de nombreux mots vides (des mots très fréquents mais qui contribuent peu à la compréhension du sens principal d'une phrase). Par conséquent, le gain de vitesse est significatif.

Informations sur le modèle / 1




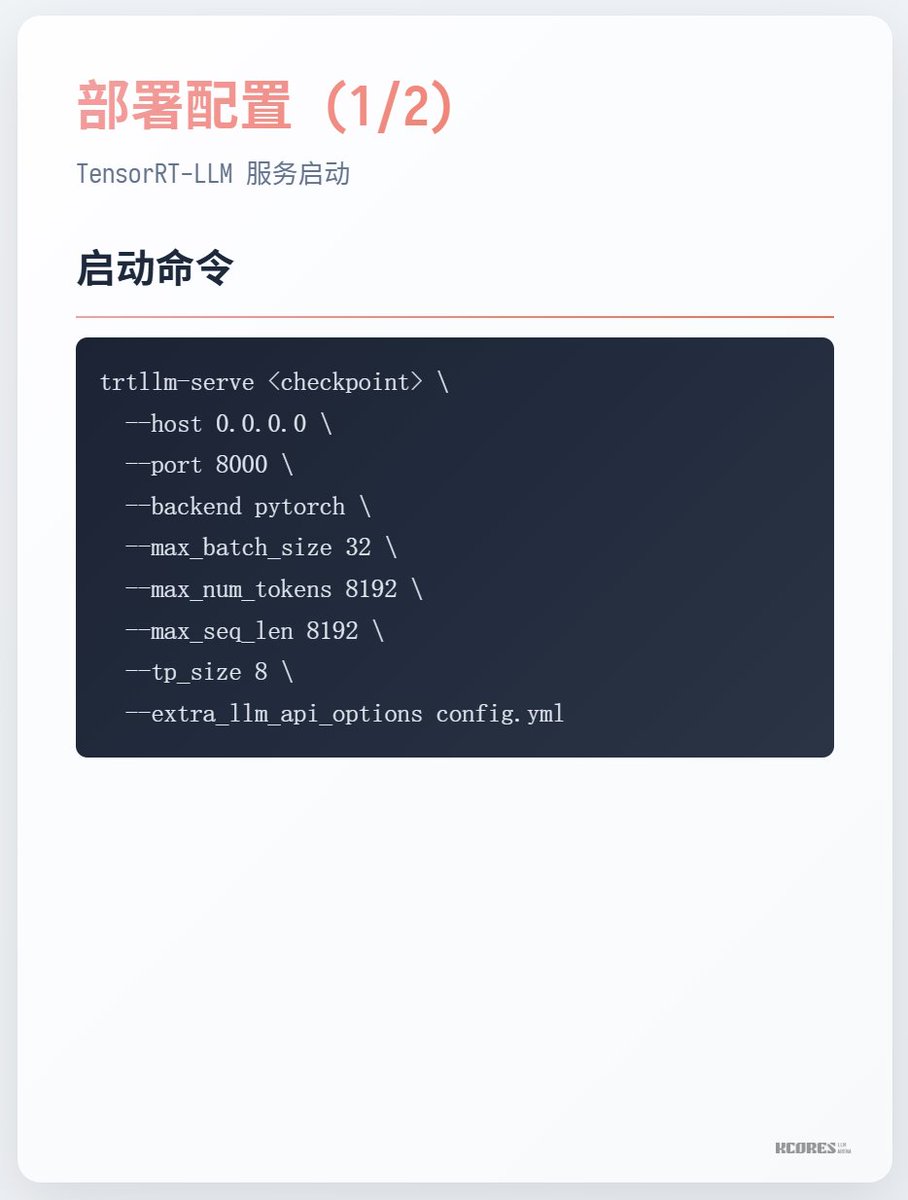
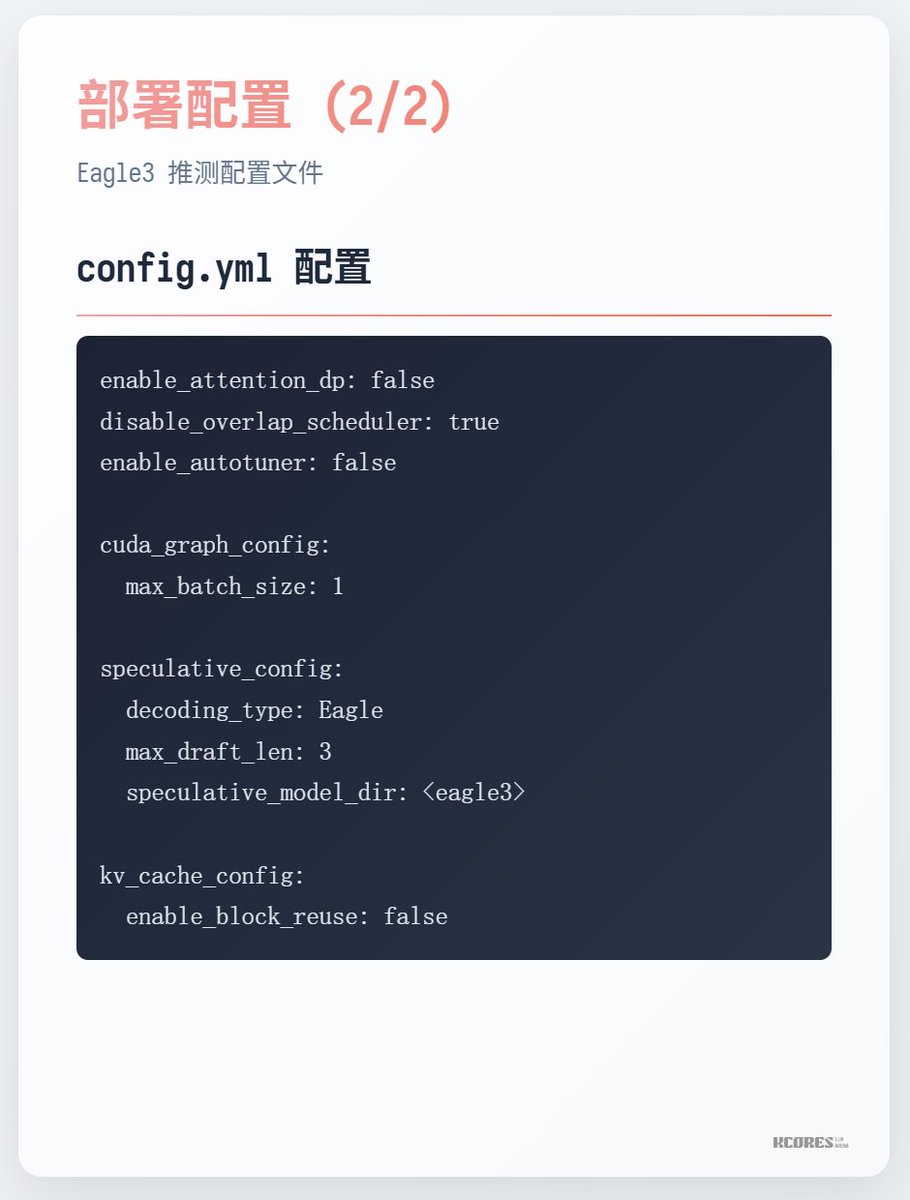
Comment courir