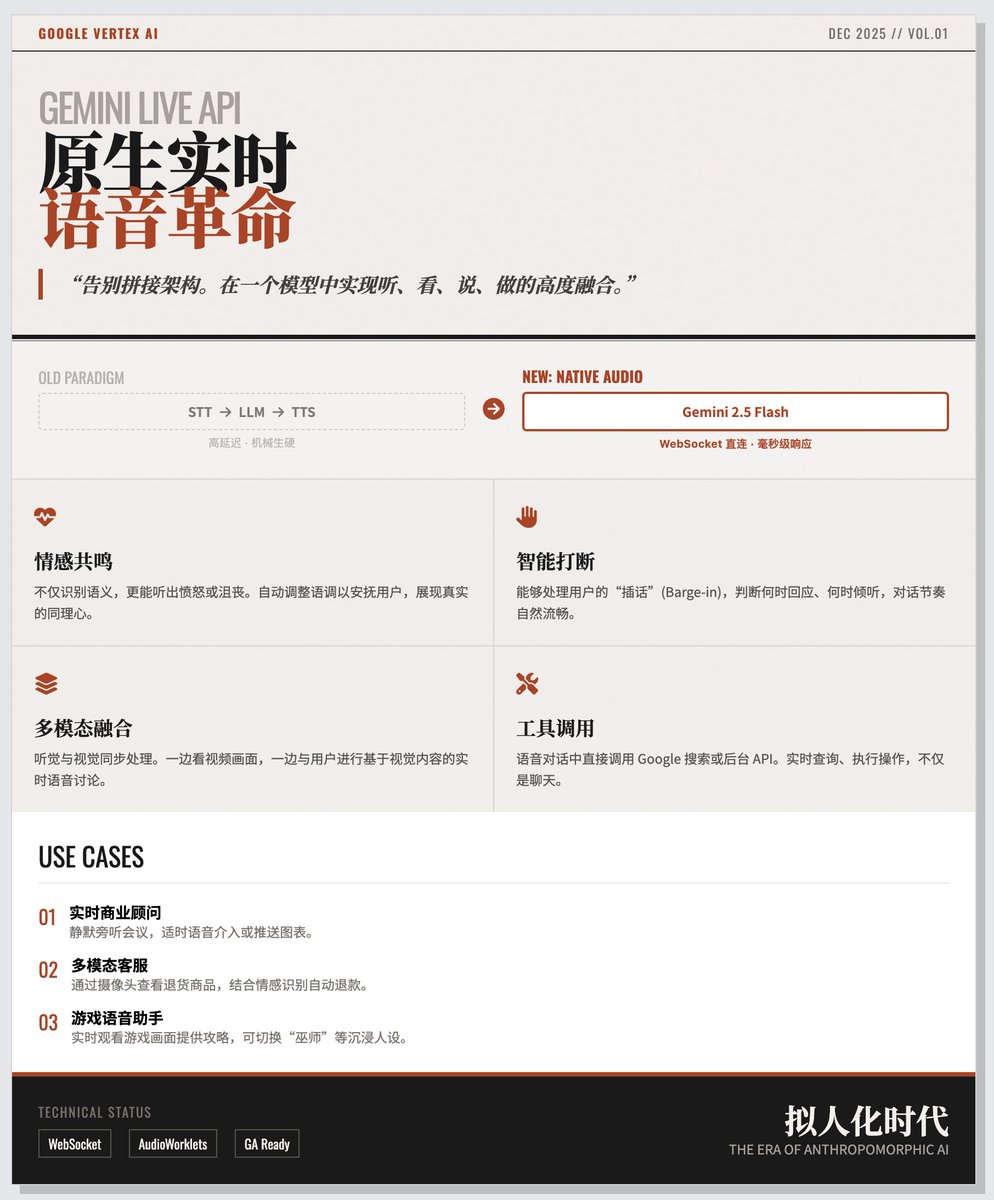
Google a officiellement lancé l'API Gemini Live, basée sur le modèle audio natif Flash Gemini 2.5. Les développeurs n'ont plus besoin d'assembler laborieusement des circuits de traitement vocal complexes ; ils peuvent désormais obtenir une intégration poussée de l'écoute, de la vision, de la parole et de l'action au sein d'un seul modèle. Transformation radicale : Dites adieu à l’assemblage à latence élevée et adoptez la communication native en temps réel. La création d’une IA de dialogue vocal nécessite généralement trois étapes : STT → LLM → TTS. Ce processus est non seulement gourmand en ressources, mais il rend également le dialogue mécanique et rigide. L'innovation majeure de l'API Gemini Live réside dans : • Traitement audio natif : le modèle Gemini 2.5 Flash peut « entendre » et comprendre directement l’audio d’origine et générer directement des réponses audio. • Latence extrêmement faible : élimine les étapes de conversion intermédiaires et permet une réponse en temps réel de l’ordre de la milliseconde grâce à une seule connexion WebSocket. • Fusion multimodale : Le modèle peut non seulement entendre, mais aussi traiter simultanément les flux vidéo, le texte et les informations visuelles. Par exemple, les utilisateurs peuvent diffuser une vidéo tout en conversant vocalement avec l’IA. Cet article de blog, intitulé « Cinq capacités clés de type humain », souligne comment cette API rend l'IA plus semblable à une vraie personne, plutôt qu'à une simple machine à questions-réponses. • Résonance émotionnelle : le modèle peut entendre le ton, le débit et les émotions (comme la colère et la frustration) de l’orateur et ajuster automatiquement son propre ton pour apaiser l’utilisateur ou faire preuve d’empathie. • Gestion intelligente des interruptions et écoute : au-delà de la simple détection vocale, l’IA détermine quand répondre, quand garder le silence et gère même les interruptions de l’utilisateur, pour une conversation plus naturelle. • Utilisation d'outils : lors des conversations vocales, l'IA peut utiliser des outils externes en temps réel ou effectuer une recherche Google pour obtenir les informations les plus récentes. • Mémoire persistante : Maintien de la cohérence contextuelle dans les interactions multimodales. • Stabilité de niveau entreprise : En tant que version GA, elle offre la haute disponibilité et la prise en charge multirégionale requises pour les environnements de production. Développement et déploiement : des modèles aux applications concrètes Pour aider les développeurs à démarrer rapidement, Google propose deux modèles de démarrage rapide et trois exemples de scénarios d’application représentatifs : Modèle de développement : Modèle JavaScript pur : sans aucune dépendance, idéal pour comprendre le protocole WebSocket sous-jacent et le streaming multimédia. • Modèle React : Conception modulaire avec flux de travail de traitement audio, adapté à la création d’applications d’entreprise complexes. Trois principaux scénarios pratiques : 1. Conseiller d'affaires en temps réel : Points forts : Elle comprend un « mode silencieux » et un « mode vocal ». L’IA peut écouter les réunions comme un copilote, en affichant uniquement les informations graphiques à l’écran (sans déranger le participant), ou intervenir vocalement pour fournir des suggestions au besoin. 2. Service client multimodal : Points forts : Les utilisateurs peuvent présenter directement les produits problématiques (comme les articles retournés) via leur caméra. L’IA combine l’analyse visuelle et la reconnaissance des émotions vocales pour déclencher automatiquement le traitement du remboursement par les outils en arrière-plan. 3. Assistant vocal de jeu : Points forts : L’IA surveille le jeu du joueur en temps réel et fournit des conseils stratégiques. Les utilisateurs peuvent également modifier la « personnalité » de l’IA (par exemple, un sage magicien ou un robot de science-fiction), ce qui en fait non seulement un commandant, mais aussi un partenaire de jeu. Blog officiel de Google