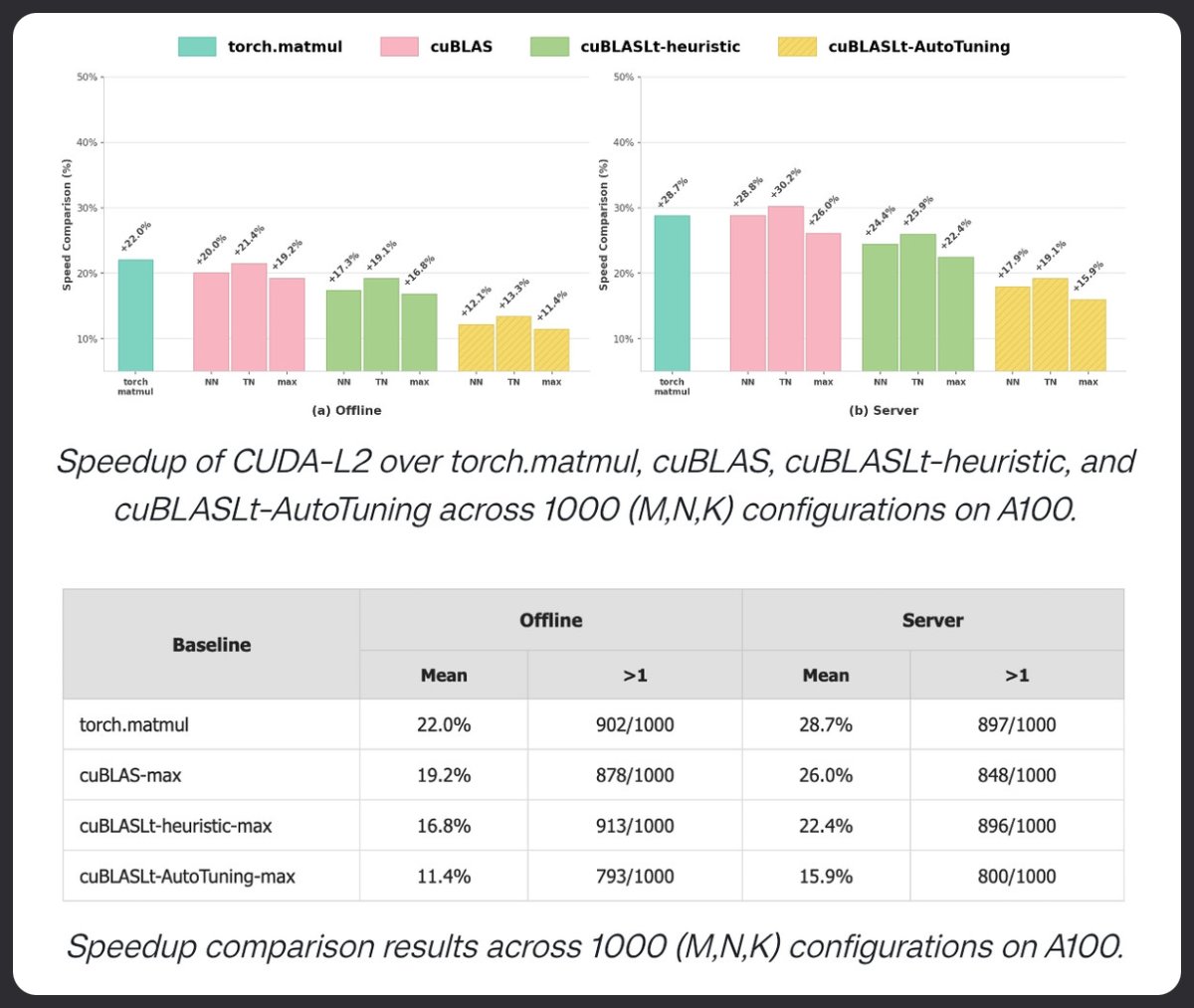
CUDA-L2 utilise l'apprentissage par renforcement pour surpasser cuBLAS en matière de multiplication matricielle. Testé sur 1000 configurations HGEMM, il surpasse torch.matmul, cuBLAS et cuBLASLt AutoTuning sur A100. +22% en mode hors ligne. +28,7 % en mode serveur. Les LLM sont en train d'optimiser les noyaux.
📄 Articlarxiv.org/pdf/2512.02551l5KX 🔗 Gigithub.com/deepreinforce-…apZLAgY