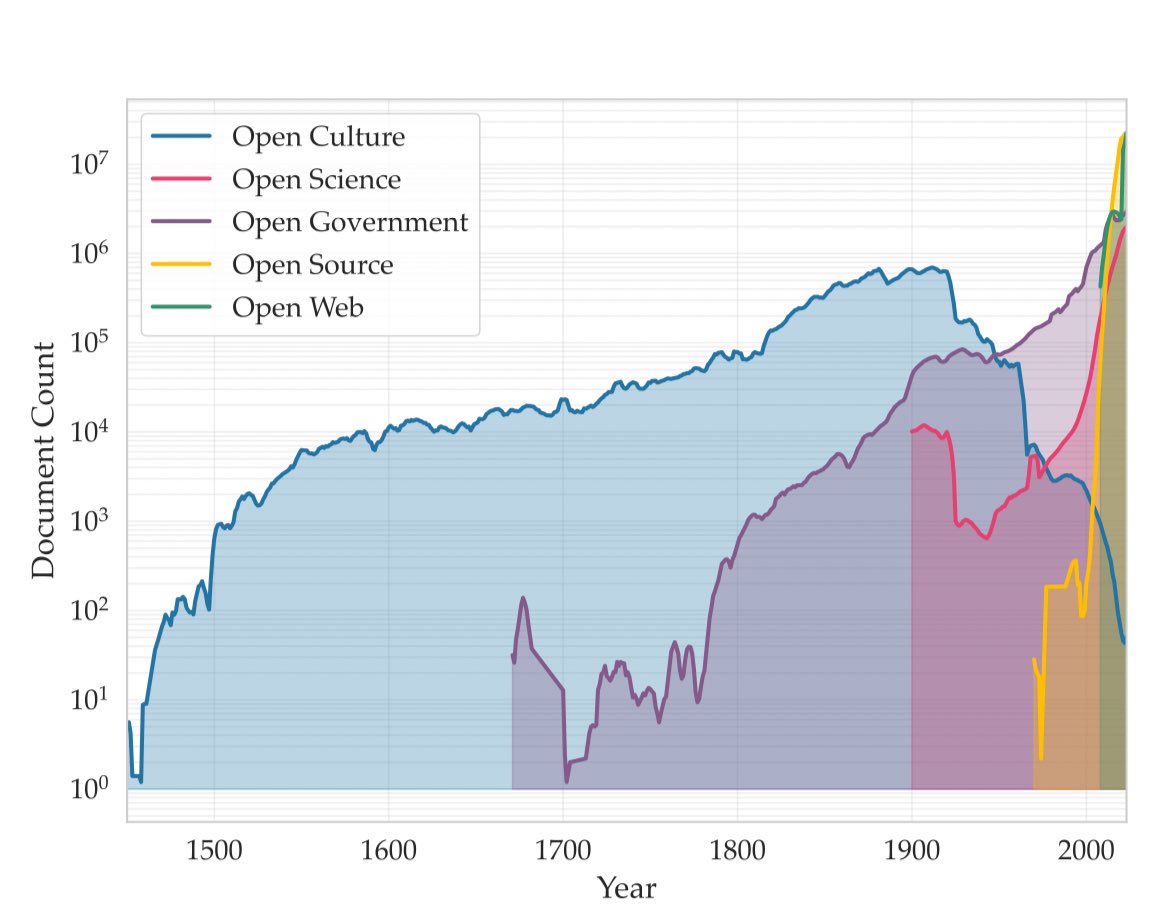
Pour rappel, Common Corpus possède le plus grand ensemble de données disponible pour ce type de projet : environ 900 milliards de jetons avant 1950.
Mais aujourd'hui, je serais davantage intéressé par une approche en environnement synthétique pour les modèles temporels. Un modèle de raisonnement inspiré de l'époque romaine pourrait même être envisageable.