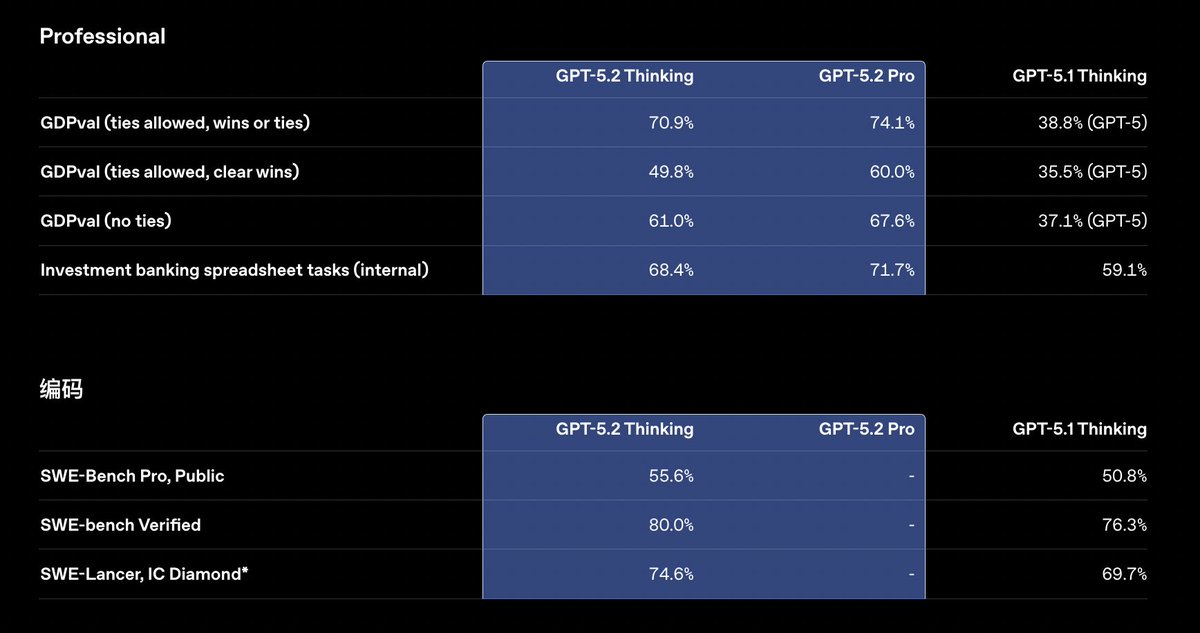
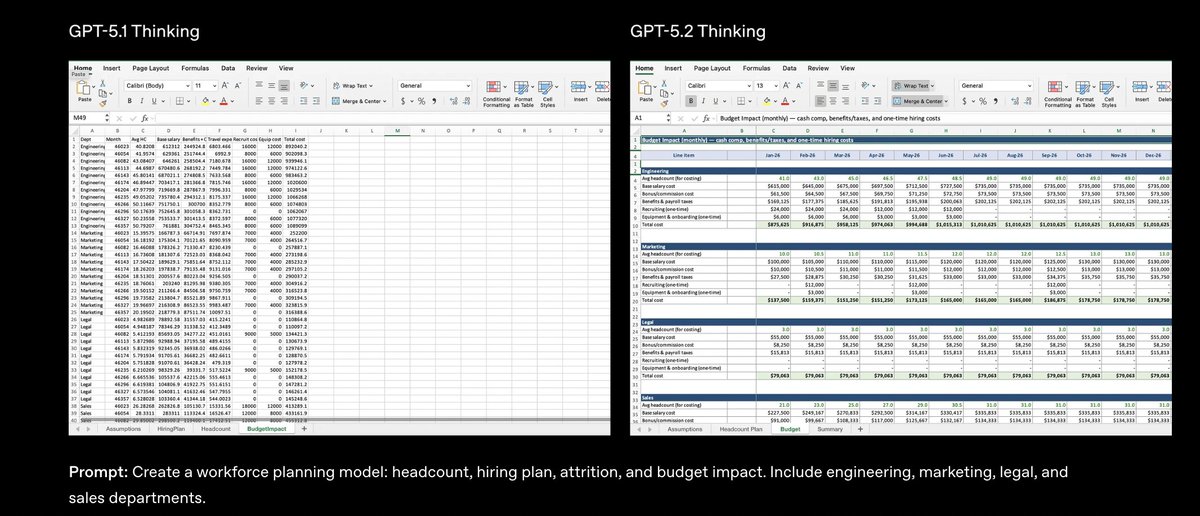
La version 5.2 de GPT a été publiée, repoussant considérablement les limites du secteur dans les domaines du travail intellectuel, de la programmation, de la recherche scientifique, des documents longs et des tâches de vision. Comprend trois niveaux : Instantané, Réfléchi et Pro. Atteignant le « niveau d'expert humain » sur GDPval (une évaluation mesurant 44 tâches de connaissances professionnelles), GPT-5.2 Thinking a égalé ou surpassé les experts de l'industrie dans 70,9 % des cas, étant 11 fois plus rapide et coûtant moins de 1 % des experts. Ils sont particulièrement doués pour la création de feuilles de calcul et de présentations, et leur score moyen dans les tâches de modélisation de feuilles de calcul pour la banque d'investissement est 9,3 % supérieur à celui de GPT-5.1. Autrement dit, auparavant, lorsqu'on demandait à l'IA d'écrire du code, de créer des présentations PowerPoint ou de construire des modèles financiers, elle ne fournissait qu'une ébauche, et le format, les formules, les références et l'esthétique devaient tous être revus manuellement. Maintenant, compte tenu des exigences, il peut soumettre un fichier Excel/Slide contenant les formules, la mise en forme, les schémas de couleurs et les commentaires, le tout en une seule fois. Capacités de codage : 55,6 % sur SWE-Bench Pro, 80 % sur SWE-bench Verified, avec une capacité améliorée à générer des interfaces utilisateur 3D front-end et complexes en une seule étape. Recherche mathématique et physique : 100 % de réussite au concours de mathématiques AIME 2025 FrontierMath T1-3 40,3 % (+9,3 %), a aidé les chercheurs à compléter une nouvelle preuve de la théorie de l'apprentissage statistique. GPQA Niveau Diamant Diplômé Q&A : 92,4 % ; Niveau Pro : 93,2 %. Texte long et visuels : Parmi les 256 000 jetons, le taux de récupération des jetons « 4 aiguilles » est proche de 100 %, et les segments MRCRv2 sont en tête avec une moyenne de 30 parcelles. Le taux d'erreur pour la reconnaissance des graphiques, des tableaux de bord et des images de cartes mères a été réduit de moitié, et l'intégration avec les outils Python est prise en charge. Invocation d'outils et agent intelligent : Tau2-bench affiche un taux de réussite de 98,7 % dans les scénarios de China Telecom, permettant aux utilisateurs d'effectuer plus de 10 étapes, notamment les changements de vol, le suivi des bagages et les demandes de sièges spéciaux, sur plusieurs systèmes en un seul processus. Réduction des hallucinations : En réalité, le taux d'erreur dans les réponses ChatGPT a diminué de 30 %, et après l'activation de la recherche, le taux d'erreur a atteint 93,9 %. Entrée : 1,75 / 1 M de jetons (0,175 en cache), sortie : 14 ; Version Pro : 21 / 168 $ Les utilisateurs de ChatGPT Plus et des versions supérieures bénéficieront d'un déploiement progressif à partir d'aujourd'hui ; l'API est entièrement lancée. #GPT52 #OpenAIGPT
Bloopenai.com/zh-Hans-CN/ind…SpIL