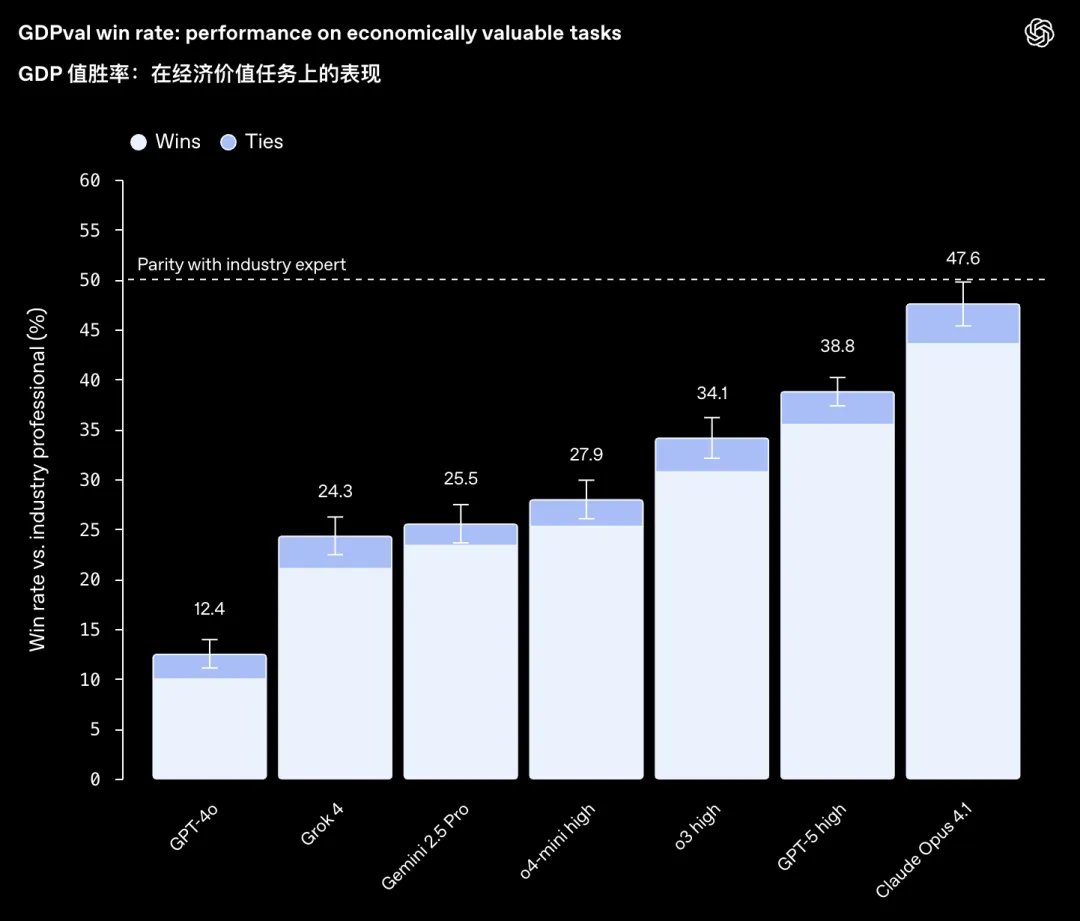
Sam est aux anges : le bilan de fin d’année d’OpenAI, GPT 5.2, est officiellement publié. Ne vous laissez pas tromper par son numéro de version ; il s'agit de la grande surprise d'OpenAI pour la fin de l'année. Le positionnement officiel est le suivant : le modèle le plus performant à ce jour pour le travail intellectuel professionnel. Les performances du modèle ont été grandement améliorées, mais son prix a également augmenté de manière significative, de 40 %. Dans le contexte de la tendance générale à la réduction des coûts, une augmentation de prix pour un modèle nécessite généralement une base solide. Qu’est-ce qui confère à ce modèle sa fiabilité ? Il y a quelque temps, OpenAI a conçu GDPval, qui s'inspire de l'indicateur économique clé du produit intérieur brut (PIB). Les 1 320 tâches professionnelles couvrent 44 professions soigneusement sélectionnées parmi les 9 principaux secteurs contribuant au PIB américain. Cette tâche exige la soumission de livrables authentiques, tels que des présentations commerciales, des feuilles de calcul comptables, des plannings de services d'urgence, des organigrammes de production ou de courtes vidéos. Lors de la première sortie de GDPval, Claude Opus 4.1 était largement en tête avec un score de 47,6. Mais aujourd'hui, GPT-5.2 a directement fait grimper mon score à plus de 70 %.
Capacités de codage SWE-Bench Pro est une évaluation rigoureuse pour l'ingénierie logicielle en situation réelle. Contrairement à SWE-bench Verified, qui ne teste que Python, SWE-Bench Pro teste quatre langages et est conçu pour être plus résistant à la contamination, plus exigeant, plus diversifié et plus pertinent sur le plan industriel. GPT-5.2 Thinking a atteint une nouvelle performance de pointe de 55,6 % sur le SWE-Bench Pro, surpassant les 52 % de Claude Opus 4.5 et les 43,3 % de Gemini 3 Pro.

GPT-5.2 a établi une nouvelle référence dans le domaine du raisonnement sur un contexte long. La métrique MRCR v2 (Multi-turn coreder resolution) mesure comment plusieurs requêtes utilisateur « aiguille » identiques sont insérées dans un long document « meule de foin » constitué d'un grand nombre de requêtes et de réponses similaires, puis le modèle doit reproduire la réponse correspondant à la nième « aiguille ». GPT-5.2 est le premier modèle à atteindre une précision proche de 100 % sur les variantes MRCR à 4 broches (jusqu'à 256 000 jetons).

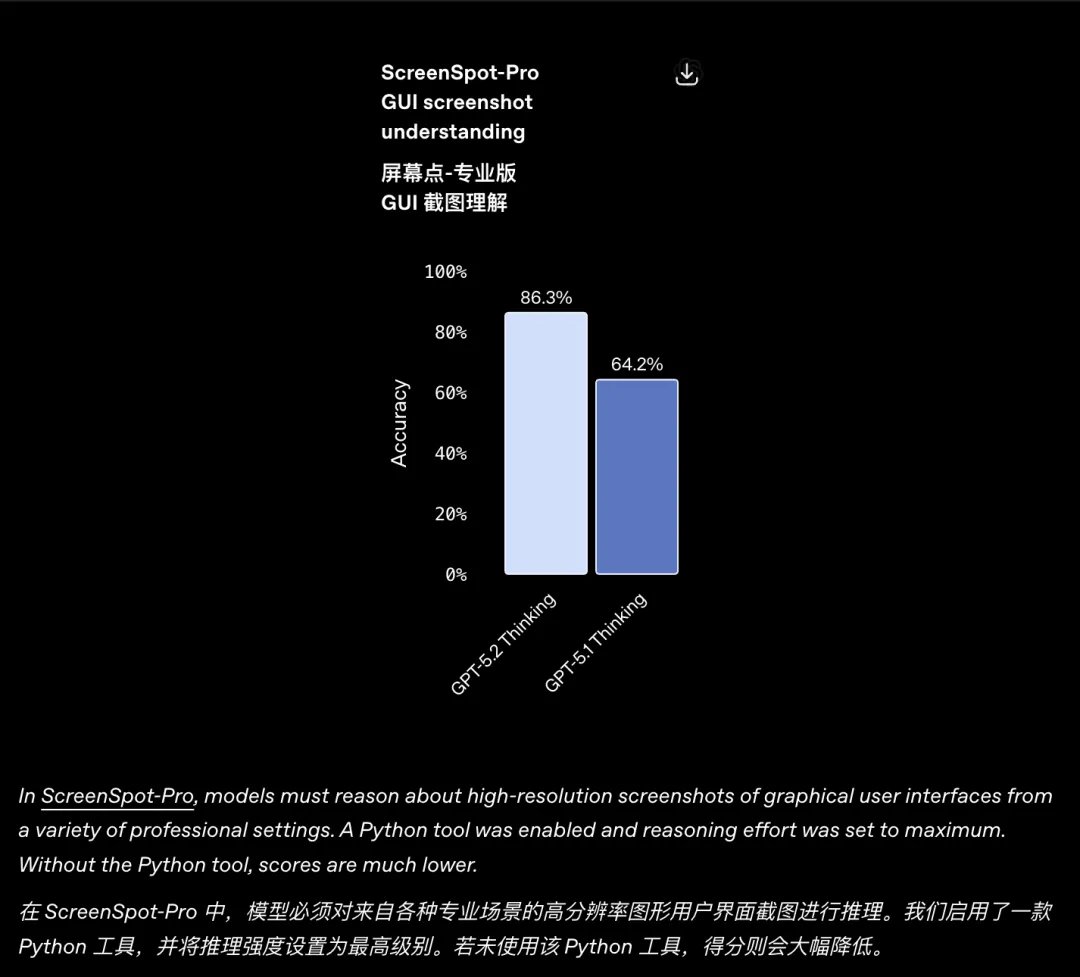
Réduction des hallucinations Une autre amélioration majeure de GPT-5.2 réside dans la réduction significative des « illusions ». Le taux d'erreur est inférieur de 30 % à celui de son prédécesseur. Compréhension visuelle GPT-5.2 Thinking a réduit le taux d'erreur de près de moitié dans les tâches impliquant un raisonnement diagrammatique et la compréhension des interfaces logicielles.

Version standard : Entrée 1,75 $, sortie 14 $. Version professionnelle : Entrée 21 $, sortie 168 $. Globalement, le prix a augmenté de 40 % par rapport à GPT 5.1. C'est incroyable. Trop cher. Les tendances en matière d'IA cette année incluent des augmentations de prix pour les modèles de texte (GPT 5.2) et les modèles d'images (Banana Pro). La tendance en matière d'IA l'année prochaine sera-t-elle une hausse des prix des modèles vidéo ?
